






 本文介绍了如何利用Selenium模块及其PhantomJS组件,通过模拟浏览器行为来抓取百度搜索结果的相关链接。示例代码展示了从指定URL获取页面内容,并通过查找特定元素来提取所需信息。
本文介绍了如何利用Selenium模块及其PhantomJS组件,通过模拟浏览器行为来抓取百度搜索结果的相关链接。示例代码展示了从指定URL获取页面内容,并通过查找特定元素来提取所需信息。
selenium模块主要用来做测试,模拟键盘、鼠标来操作浏览器。
phantomjs 就像一个无界面的浏览器一样。
两个结合能很好的解决js抓取的问题。
测试代码:
#coding=utf-8 from selenium import webdriver driver = webdriver.PhantomJS() #抓取百度搜索结果的相关链接 url = "http://www.baidu.com/s?wd=web&ie=utf-8&tn=baiduhome" driver.get(url) q = driver.find_element_by_id("rs") s = q.find_elements_by_tag_name('th') for i in s: print i.text driver.quit()
结果:
如何定位元素,selenium的的资料有详细的讲解,这里省略...字
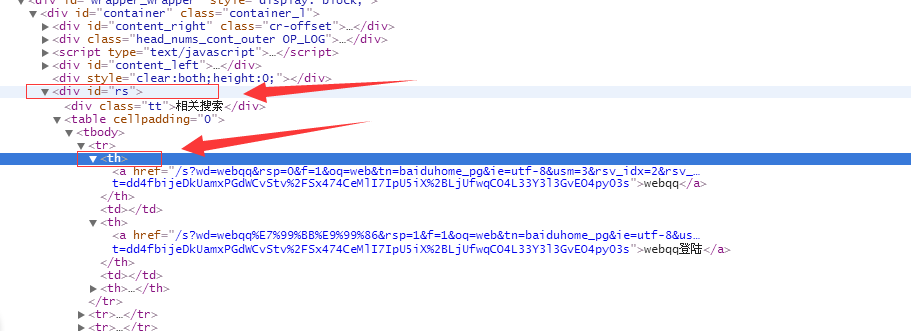
如下结果正常:
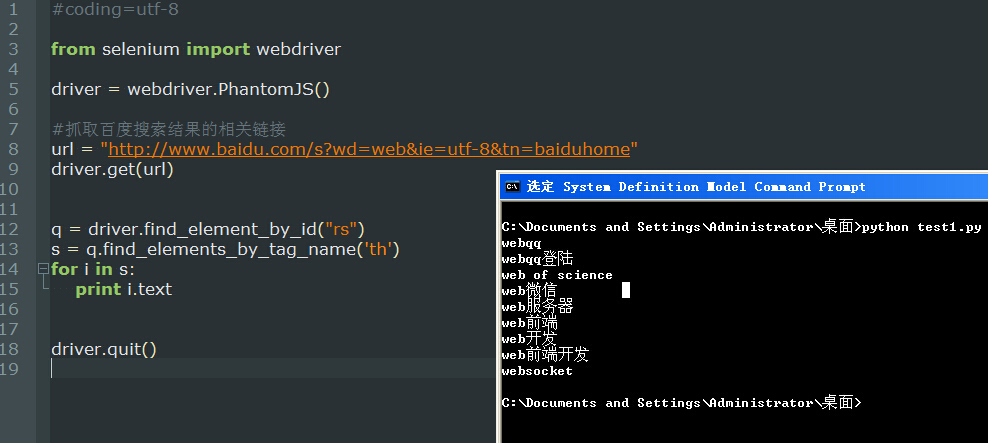
下篇打算用slenium做个google的采集.....待续未完

















 577
577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









