







path环境变量的意义:让系统找到一些exe文件
1.有python和anaconda,想使用anaconda,要怎么配置环境变量?
(1)配置一下路径
C:\Anaconda3----python.exe
C:\Anaconda3\Scripts----pip.exe
(2)把这两个目录放在path环境变量的最前面,这样系统在找python和pip的时候会先找到anaconda下面的这个
2.python2和python3如何实现兼容?
当我们在cmd中输入python命令的时候,系统会去path环境变量下面寻找与命令相同的exe可执行文件启动。
当我们安装了python2和python3的时候,只需要修改两个环境中的python.exe文件名,比如把python2的改成python2.exe,把python3的改成python3.exe。这样在输入命令的时候,如果想启动python3,输入python3即可。
pip也是一样的原理。
一、selenium
(一)selenium操作Chrome浏览器的方法
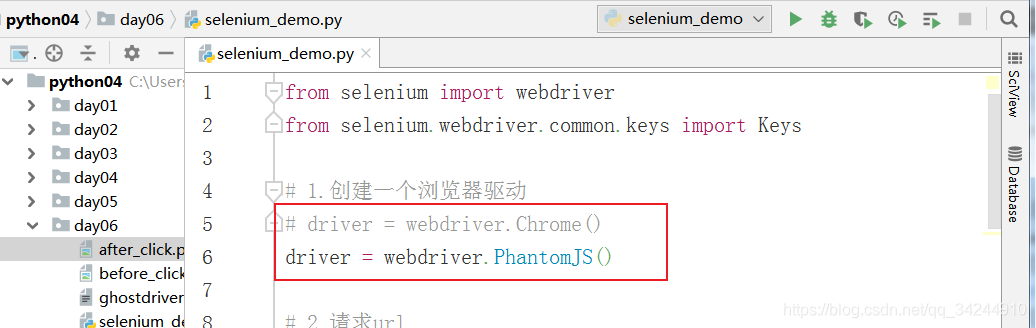
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# 1.创建一个浏览器驱动
driver = webdriver.Chrome()
# 2.请求url
driver.get('http://www.baidu.com/')
# 查看标题
print(driver.title)
# 查看cookie
print(driver.get_cookies())我啥都懂地对地导弹
input = driver.find_element_by_id('kw')
input.send_keys(u'爬虫')
# 截屏
driver.save_screenshot('before_click.png')
subtim = driver.find_element_by_id('su')
subtim.click()
driver.save_screenshot('after_click.png')
# webelement对象
webele = driver.find_element_by_id('kw')
input.send_keys(Keys.CONTROL,'a')
input.send_keys(Keys.CONTROL,'x')
# 查找webelement对象的方法
# input = driver.find_element_by_id('kw')
input = driver.find_element_by_css_selector('#kw')
# driver.find_element_by_xpath()
input.send_keys('scrapy')
subtim.submit()
# 查看webelement元素坐标
print(input.location)
# 查看元素的大小
print(input.size)
改为selenium+phantomjs
无可视化浏览器界面,提高运行速度
(二)selenium常用方法总结
1.获取当前页面的Url
方法:current_url
实例:driver.current_url
2.获取元素坐标
方法:location
解释:首先查找到你要获取元素的,然后调用location方法
实例:driver.find_element_by_xpath("xpath").location
3.表单的提交
方法:submit
解释:查找到表单(from)直接调用submit即可
实例:driver.find_element_by_id("form1").submit()
4.获取CSS的属性值
方法:value_of_css_property(css_name)
实例:driver.find_element_by_css_selector("input.btn").value_of_css_property("input.btn")
5.获取元素的属性值
方法:get_attribute(element_name)
实例:driver.find_element_by_id("kw").get_attribute("kw")
6.判断元素是否被选中
方法:is_selected()
实例:driver.find_element_by_id("form1").is_selected()
7.返回元素的大小
方法:size
实例:driver.find_element_by_id("iptPassword").size 返回值:{'width': 250, 'height': 30}
8.判断元素是否显示
方法:is_displayed()
实例:driver.find_element_by_id("iptPassword").is_displayed()
9.判断元素是否被使用
方法:is_enabled()
实例:driver.find_element_by_id("iptPassword").is_enabled()
10.获取元素的文本值
方法:text
实例:driver.find_element_by_id("iptUsername").text
11.元素赋值
方法:send_keys(*values)
实例:driver.find_element_by_id("iptUsername").send_keys('admin')
12.返回元素的tagName
方法:tag_name
实例:driver.find_element_by_id("iptUsername").tag_name
13.删除浏览器所有的cookies
方法:delete_all_cookies()
实例:driver.delete_all_cookies()
14.删除指定的cookie
方法:delete_cookie(name)
实例:deriver.delete_cookie("my_cookie_name")
15.关闭浏览器
方法:close()
实例:driver.close()
16.关闭浏览器并且退出驱动程序
方法:quit()
实例:driver.quit()
17.返回上一页
方法:back()
实例:driver.back()
18.清空输入框
方法:clear()
实例:driver.clear()
19.浏览器窗口最大化
方法:maximize_window()
实例:driver.maximize_window()
20.查看浏览器的名字
方法:name
实例:drvier.name
21.返回当前会话中的cookies
方法:get_cookies()
实例:driver.get_cookies()
22.根据cookie name 查找映射Value值
方法:driver.get_cookie(cookie_name)
实例:driver.get_cookie("NET_SessionId")
23.截取当前页面
方法:save_screenshot(filename)
实例:driver.save_screenshot("D:\\Program Files\\Python27\\NM.bmp")
(三)selenium种查找页面元素的方法
1.通过id进行查找
driver.find_element_by_id('kw')
2.通过css选择器进行查找
input = driver.find_element_by_css_selector('#kw')
3.通过xpath进行查找
driver.find_element_by_xpath()
二、selenium+phantomjs
(一)请求页面的流程
from selenium import webdriver
1.创建driver对象
driver = webdriver.PhantomJS()
2.请求url
driver.get(url)
3.等待
time.sleep(5)
三种等待
1.强制等待
import time
time.sleep(10)
2.隐式等待
driver.implicitly_wait(10)
隐式等待就是等到页面全部加载完成,比如js,css或者图片全请求加载到页面,也就是我们常看到的页面不再转圈圈为止,程序才会开始继续运行。
3.显示等待
导包
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
步骤
-
创建等待对象
wait = WebDriverWait( driver, # 浏览器驱动对象 10, # 最大等待时长 0.5, # 扫描间隔 ) -
wait.until(等待条件):等待条件成立,程序才继续运行
等待条件在selenium中有个专门的模块来设置,即expected_conditions as EC
最常用的条件有以下两个:
- EC.presence_of_element_located(locator对象)
- EC.presence_of_all_elements_located(locator对象)
两个条件都是验证元素是否出现
第一个只要一个符合条件的元素加载出来即可
第二个必须所有符合条件的元素都加载出来才行
传入的参数都是元组类型的locator对象:
(通过什么查找(By.ID,By.XPATH,By.CSS_SELECTOR),查找的内容的语法)如(By.ID,‘kw’)
-
wait.until方法的返回值是对应定位器定位到的webelement对象
如果需要对这个webelement对象做一些操作,可以很方便的做到。
4.获取页面内容
html = driver.page_source
5.用lxml模块解析页面内容
tree = etree.HTML(html)
三、项目
(一)豆瓣读书(面向对象,强制等待)
import time
from selenium import webdriver
from lxml import etree
base_url = 'https://search.douban.com/book/subject_search?search_text=python&cat=1001&start=%s'
driver = webdriver.PhantomJS()
def get_text(text):
if text:
return text[0]
return ''
def get_books(text):
html = etree.HTML(text)
div_list = html.xpath('//div[@id="root"]/div/div/div/div/div')
for div in div_list:
book = {}
# 图书名称
book_name = get_text(div.xpath('.//div[@class="detail"]/div[@class="title"]/a/text()'))
# 评分
book_score = get_text(div.xpath('.//span[@class="rating_nums"]/text()'))
# 评价数
book_appraise = get_text(div.xpath('.//span[@class="pl"]/text()'))
# 详情页链接
book_url = get_text(div.xpath('.//div[@class="title"]/a/@href'))
# 作者,出版社,价格,出版日期
book_info = get_text(div.xpath('.//div[@class="meta abstract"]/text()')).split(' /')
if all([book_name,book_url]):
book['书名'] = book_name
book['评分'] = book_score
book['评价数'] = book_appraise[1:len(book_appraise)-1]
book['详情页路由'] = book_url
book['作者'] = '/'.join(book_info[:-3])
book['出版社'] = book_info[-3]
book['价格'] = book_info[-1]
book['出版日期'] = book_info[-2]
print(book)
if __name__ == '__main__':
for i in range(10):
driver.get(base_url%(i*15))
time.sleep(2)
html_str = driver.page_source
get_books(html_str)
封装,显示等待
import time
from selenium import webdriver
from lxml import etree
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from urllib import parse
class Douban(object):
def __init__(self,url):
self.url = url
self.wait = WebDriverWait(driver,10)
self.parse()
def get_text(self,text):
if text:
return text[0]
return ''
def get_content_by_selenium(self,url,xpath):
driver.get(url)
# 等待
# time.sleep(3)
# until方法里面是一些条件
# locator对象是一个元组
webelement = self.wait.until(EC.presence_of_element_located((By.XPATH,xpath)))
return driver.page_source
def parse(self):
html_str = self.get_content_by_selenium(self.url,'//div[@id="root"]/div/div/div/div')
html = etree.HTML(html_str)
div_list = html.xpath('//div[@id="root"]/div/div/div/div/div')
for div in div_list:
book = {}
# 图书名称
book_name = self.get_text(div.xpath(
'.//div[@class="detail"]/div[@class="title"]/a/text()'))
# 评分
book_score = self.get_text(
div.xpath('.//span[@class="rating_nums"]/text()'))
# 评价数
book_appraise = self.get_text(div.xpath('.//span[@class="pl"]/text()'))
# 详情页链接
book_url = self.get_text(div.xpath('.//div[@class="title"]/a/@href'))
# 作者,出版社,价格,出版日期
book_info = self.get_text(
div.xpath('.//div[@class="meta abstract"]/text()')).split(' /')
if all([book_name, book_url]):
book['书名'] = book_name
book['评分'] = book_score
book['评价数'] = book_appraise[1:len(book_appraise) - 1]
book['详情页路由'] = book_url
book['作者'] = '/'.join(book_info[:-3])
book['出版社'] = book_info[-3]
book['价格'] = book_info[-1]
book['出版日期'] = book_info[-2]
print(book)
if __name__ == '__main__':
driver = webdriver.PhantomJS()
base_url = 'https://search.douban.com/book/subject_search?'
kw = 'python'
for i in range(5):
params = {
'search_text': kw,
'cat': '1001',
'start': str(i * 15),
}
url = base_url + parse.urlencode(params)
Douban(url)
(二)腾讯招聘
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from lxml import etree
def wait_get_content(url,xpath):
driver.get(url)
wait.until(EC.presence_of_element_located((By.XPATH,xpath)))
return driver.page_source
def get_text(value):
if value:
return value[0]
return ''
def get_info(url):
html_str = wait_get_content(url,'//div[@class="recruit-wrap recruit-margin"]')
html = etree.HTML(html_str)
div_list = html.xpath('//div[@class="recruit-wrap recruit-margin"]/div')
for div in div_list:
item = {}
title = get_text(div.xpath('.//a/h4/text()'))
region = get_text(div.xpath('.//a/p/span[2]/text()'))
type = get_text(div.xpath('.//a/p/span[3]/text()'))
date = get_text(div.xpath('.//a/p/span[4]/text()'))
item['title'] = title
item['region'] = region
item['type'] = type
item['date'] = date
print(item)
if __name__ == '__main__':
driver = webdriver.PhantomJS()
wait = WebDriverWait(driver,10)
base_url = 'https://careers.tencent.com/search.html?index=%s'
for i in range(1,2):
get_info(base_url%i)
封装
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from lxml import etree
class Tencent(object):
def __init__(self,url):
self.url = url
self.get_info()
def wait_get_content(self,url, xpath):
driver.get(url)
wait.until(EC.presence_of_element_located((By.XPATH, xpath)))
return driver.page_source
def get_text(self,value):
if value:
return value[0]
return ''
def get_info(self):
html_str = self.wait_get_content(self.url,
'//div[@class="recruit-wrap recruit-margin"]')
html = etree.HTML(html_str)
div_list = html.xpath('//div[@class="recruit-wrap recruit-margin"]/div')
for div in div_list:
item = {}
title = self.get_text(div.xpath('.//a/h4/text()'))
region = self.get_text(div.xpath('.//a/p/span[2]/text()'))
type = self.get_text(div.xpath('.//a/p/span[3]/text()'))
date = self.get_text(div.xpath('.//a/p/span[4]/text()'))
item['title'] = title
item['region'] = region
item['type'] = type
item['date'] = date
print(item)
if __name__ == '__main__':
driver = webdriver.PhantomJS()
wait = WebDriverWait(driver, 10)
base_url = 'https://careers.tencent.com/search.html?index=%s'
for i in range(1, 6):
Tencent(base_url%i)

















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









