






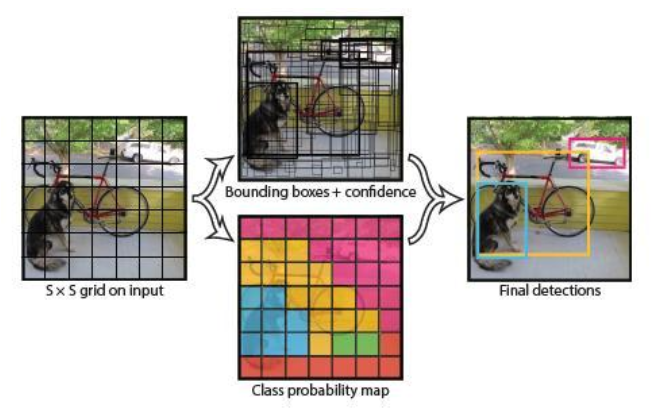
图1
如图1所示,将输入图像分成S*S个格子,对每个格子预测B个bounding box,每个bounding box又包含5个预测值:x,y,w,h,confidence。其中,x,y为bounding box中心坐标,w,h为宽和高,confidence为置信度。confidence的计算公式为:![]() 。每个bbox都对应一个confidence,如果格子中没有object,则confidence就为零;如果格子中包含object,则confidence为bbox与ground truth的IOU值。
。每个bbox都对应一个confidence,如果格子中没有object,则confidence就为零;如果格子中包含object,则confidence为bbox与ground truth的IOU值。
每个格子预测C个类别的概率,即在含有object的条件下属于某一类的概率,有C类。![]() 。由此得到bbox属于每类的confidence score。对于其中某一类,小于0.2者设置为零,通过NMS算法去除重叠率大的bbox,最后得到每个bbox对应C个confidence score,取最大且大于零的值。如图2所示。
。由此得到bbox属于每类的confidence score。对于其中某一类,小于0.2者设置为零,通过NMS算法去除重叠率大的bbox,最后得到每个bbox对应C个confidence score,取最大且大于零的值。如图2所示。
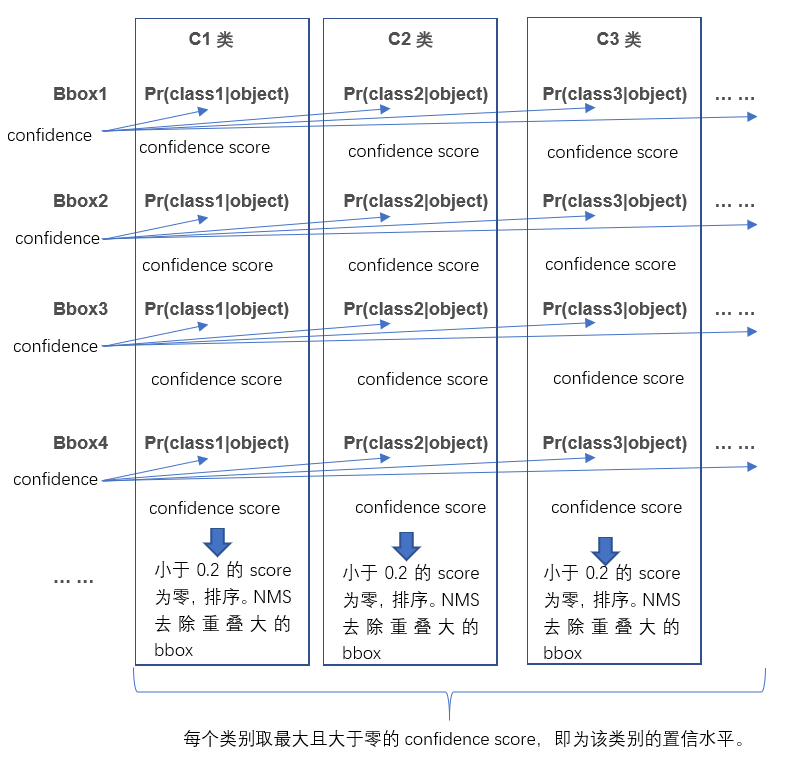
图2
网络层方面,主要采用GoogLeNet,卷积层主要用来提取特征,全连接层主要用来预测类别概率和坐标。作者先在ImageNet数据集上预训练网络,而且网络只采用fig3的前面20个卷积层,输入是224*224大小的图像。然后在检测的时候再加上随机初始化的4个卷积层和2个全连接层,同时输入改为更高分辨率的448*448。Relu层改为pRelu,即当x<0时,激活值是0.1*x,而不是传统的0,如图3所示。
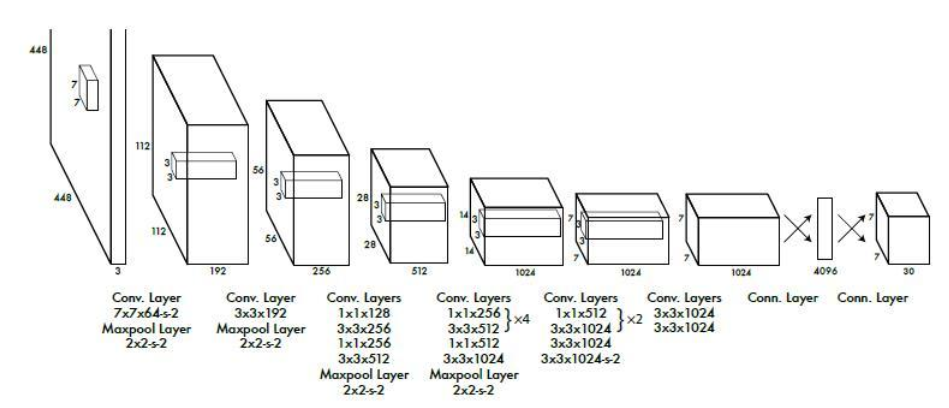
图3
损失函数方面,前面两行表示localization error(即坐标误差),第一行是box中心坐标(x,y)的预测,第二行为宽和高的预测。第三、四行表示bounding box的confidence损失,分成grid cell包含与不包含object两种情况。这里注意下因为每个grid cell包含两个bounding box,所以只有当ground truth 和该网格中的某个bounding box的IOU值最大的时候,才计算这项。 第五行表示预测类别的误差,注意前面的系数只有在grid cell包含object的时候才为1。

参考资料:
https://blog.youkuaiyun.com/u014380165/article/details/72616238

















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









