



 本文对比了Nvidia和AMD的GPU架构,介绍了费米架构、开普勒架构和Maxwell架构的特点,探讨了两种不同设计理念下的性能表现。
本文对比了Nvidia和AMD的GPU架构,介绍了费米架构、开普勒架构和Maxwell架构的特点,探讨了两种不同设计理念下的性能表现。
链接:https://www.zhihu.com/question/22630075/answer/29041618
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
现在Nvidia的节奏基本上是一个结构用两年。类似于intel的钟摆计划。
我们先先谈谈开普勒架构之前的费米架构好了。
费米的本质是什么,英伟达只要用他来搞通用计算的还有DX11(这个涉及当年的环境问题)。
费米架构提出了GPC和SM的结构概念。每一个GPC则有4个SM,sm里面有32个CUDA,每个CUDA Core是一个统一的处理器核心,执行顶点,像素,几何和kernel函数,然后有16个储存单元和8个特殊单元。
上面一段话的意思是,GPC是一个很完整的GPU,而且细分的十分完整。
所以你会看到高中低端是这么分配的低端一个,中端两个,高端四个。
大家会不会想到CPU呢。。单核,双核,四核。。大概就是思路。。
然后又引入了一二级缓存这种东西。。大家详细了解自己去搜相关东西吧。。
而AMD当时的思路跟Nvidia不一样的是,坚持用simd。至于为什么?可能是AMD和ATI整合,也可能是ATI做过游戏机的芯片制造,这个不好推断)
大的核心里面有Shader单元,每个Shader内部有5个ALU单元。
五个ALU处理完了之后一起上传,而CUDA Core是直接上传了,这就是mimd。
看到ZOL论坛有一个很好的比方。。我就粗略说说意思(传送门【NV 开普勒 架构解析篇】)
AMD就是一辆战车,然后一个马拉着战车(发射端和控制逻辑端),上面有五个家伙。弓箭手啊,战士,扔斧子的。
费米就是骑兵。。
战车虽然相比较骑兵发挥不出一个人的优势。但是养马在古代很贵的好吧,就算现在也很贵好吧。。
战车上有五个汉子,相当于马加五个人,而骑兵是一个马加一个人。
性价比肯定是战车好。
但是数量到了一定程度。史实是大兵团对战时,骑兵可以用经典的魔兽战术hit and run对付战车,先遭遇,一轮齐射,射完马上后撤,迂回一圈再过来齐射,射完再后撤········(中世纪时曾经很虎的东欧战车军就是这样被蒙古骑兵团灭的,西征波兰战役的虐杀)。中世纪开始大家都发现了,一旦战争规模玩大了,只能用骑兵,再贵也得用。
Nvidia依旧保持卡皇身份,但是中低端的AMD高功耗比和性价比虐杀。
显卡跟骑兵不一样的是。。你弄了那么多马(发射器和控制逻辑),那玩意是要发热的。。而且也是要占晶体管的。
所以你就看到核弹这个词的产生了。。。热得要死,晶体管多的要命。
详细请看传送门
写的挺好的(对了 要不要找别人授权啥的。。我没这意识啊。。)
总结一下就是AMD追求数量,而Nvidia追求效率。。
后来AMD发觉在这么玩下去不行,毕竟规模越来越大了。。也开始制造骑兵了,再贵也得用。。。就是tahtil架构。
开普勒开始追求所谓的能耗,如何追求能耗的呢?降低控制逻辑单元和指令发射器的比例,,用较少的逻辑单元去控制更多的CUDA核心,增加吞吐量啊等等方面。
<img src="https://i-blog.csdnimg.cn/blog_migrate/028a748df1da983f7009b1850caa185b.png" data-rawheight="492" data-rawwidth="500" class="origin_image zh-lightbox-thumb" width="500" data-original="https://pic2.zhimg.com/c2ded9290c1ee7a6d32e21f1935a76b5_r.jpg">
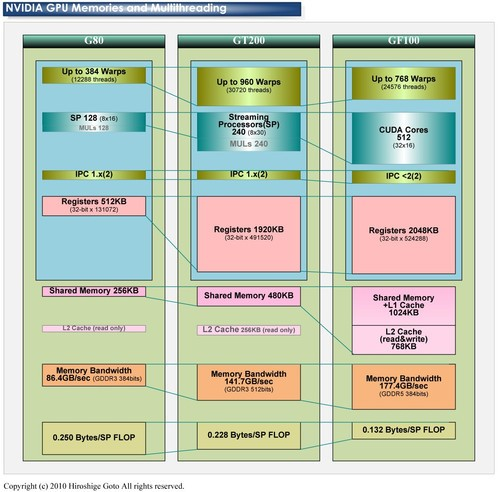
但是关键还是在调度的机制。
减少了调度的模块,才能拥有非常多的cuda(也就是工作单位)
<img src="https://i-blog.csdnimg.cn/blog_migrate/9e50d31294ce738f8291c5172c458983.png" data-rawheight="282" data-rawwidth="500" class="origin_image zh-lightbox-thumb" width="500" data-original="https://pic3.zhimg.com/db1a634716f43218ad92f51df98f26e6_r.jpg">通过软件把GPU用来分配工作的任务,来交给了CPU。
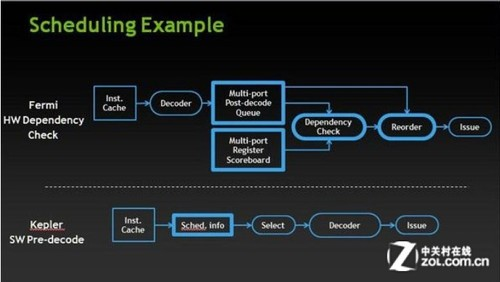 通过软件把GPU用来分配工作的任务,来交给了CPU。
通过软件把GPU用来分配工作的任务,来交给了CPU。
<img src="https://i-blog.csdnimg.cn/blog_migrate/63b38297db9e57b6b0b698c418797191.png" data-rawheight="866" data-rawwidth="500" class="origin_image zh-lightbox-thumb" width="500" data-original="https://pic4.zhimg.com/b7f42f772e6ed7cd9481615e18834a13_r.jpg">
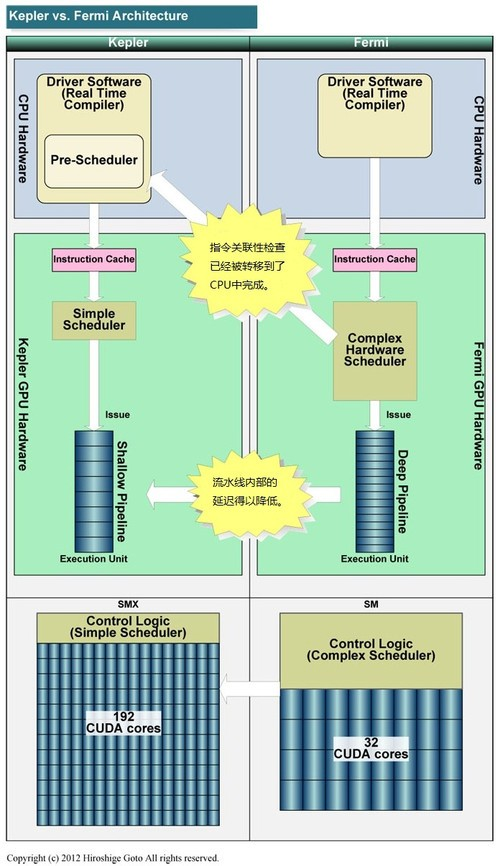
还有关键的几点是制程的改进,用了台积电的28mm,ddr5的显卡内存,动态提速(类似睿频的概念)等。
nvidia 在全面优化各方面,梳理各方面的思绪。方方面面的优化,只为了追求效率和功耗比。
最后说说 Maxwell 架构

相比较开普勒架构的
<img src="https://i-blog.csdnimg.cn/blog_migrate/ea585a71177edf235e2338677081b09b.png" data-rawwidth="741" data-rawheight="800" class="origin_image zh-lightbox-thumb" width="741" data-original="https://pic2.zhimg.com/6484a9a33ece2754d95c00a837e16dad_r.jpg">
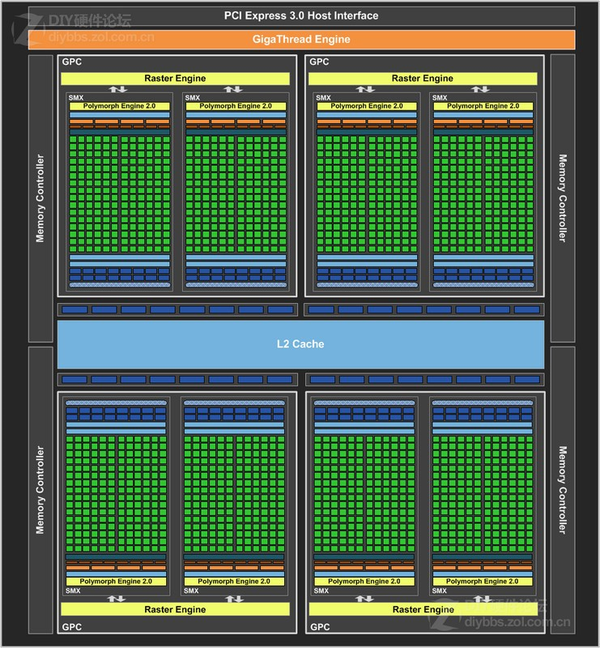
。。。能够更好的检测到每一个cuda的状态(因为每一个sm单元控制的cuda单元减少),并且通过时钟调节来控制每一个效率。
,增加了二级缓存。。集成了NVENC,能在视频解码的仅仅靠NVENC模块,让GPU休眠。。当然还有很多
第一次写这个,然后好多资料是日语,英语的。我这方面好渣,就先默默搜集,以后在啃。,借鉴了一些国内有质量新闻的东西。。比如说中关村的顾杰。。写的还是货比较多的。、。
其实我感觉Nvidia每一代继承了上一代并且在各方面进行改进。。~
~~~~~~~~~~~~~~~~~~~~实际情况~~~~~~~~~~~
gtx750TI是maxwell架构 gtx660 650ti是开普勒架构 hd7850是Tahiti架构
<img src="https://i-blog.csdnimg.cn/blog_migrate/9c3181824eb8f697e4b5e43a0de9a691.png" data-rawwidth="482" data-rawheight="247" class="origin_image zh-lightbox-thumb" width="482" data-original="https://pic1.zhimg.com/1c0d593a46b106296e146a011956ca94_r.jpg">跑分
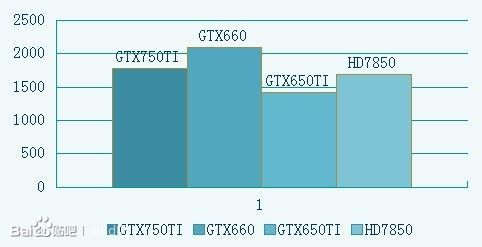 跑分
跑分
<img src="https://i-blog.csdnimg.cn/blog_migrate/49f6cd9a93de6eb39e0c97f63b5ee06f.png" data-rawwidth="465" data-rawheight="241" class="origin_image zh-lightbox-thumb" width="465" data-original="https://pic2.zhimg.com/47009df7ea0521bb68a3a2f4ae082211_r.jpg">功耗
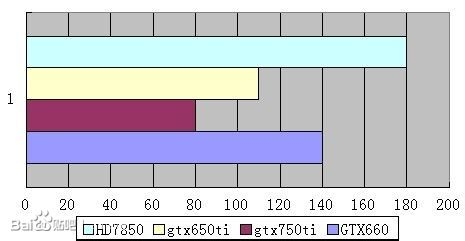 功耗
功耗

















 3998
3998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









