



1.下载千问
modelscope download --model Qwen/Qwen2.5-0.5B-Instruct --local_dir Qwen/Qwen2.5-0.5B-Instruct
下载后:
(vllm) root@autodl-container-89aa47baea-756ca94a:~/autodl-tmp/models# du -sh ./*
954M ./Qwen
1.6G ./bert-base-chinese
1.2G ./gpt2-chinese-cluecorpussmall
(vllm) root@autodl-container-89aa47baea-756ca94a:~/autodl-tmp/models# ls Qwen/
Qwen2.5-0.5B-Instruct
(vllm) root@autodl-container-89aa47baea-756ca94a:~/autodl-tmp/models# ls Qwen/Qwen2.5-0.5B-Instruct/
LICENSE README.md config.json configuration.json generation_config.json merges.txt model.safetensors tokenizer.json tokenizer_config.json vocab.json
2.安装LlamaFactory
避坑经验:发现先安装vllm后安装LlamaFactory有依赖冲突,改为先安装LlamaFacotory后安装vllm
-
安装conda环境
conda create --name xxzh python=3.10 -
autodl的学术加速
source /etc/network_turbo
- 数据盘安装LlamaFactory:
cd ~/autodl-tmp - 安装 /LLaMA-Factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .
- 顺便把vllm一起安装
pip install vllm
后面处理
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
trl 0.9.6 requires numpy<2.0.0,>=1.18.2, but you have numpy 2.2.6 which is incompatible.
llamafactory 0.9.4.dev0 requires numpy<2.0.0, but you have numpy 2.2.6 which is incompatible.
llamafactory 0.9.4.dev0 requires pydantic<=2.10.6, but you have pydantic 2.11.7 which is incompatible.
- 启动 LLaMA-Factory
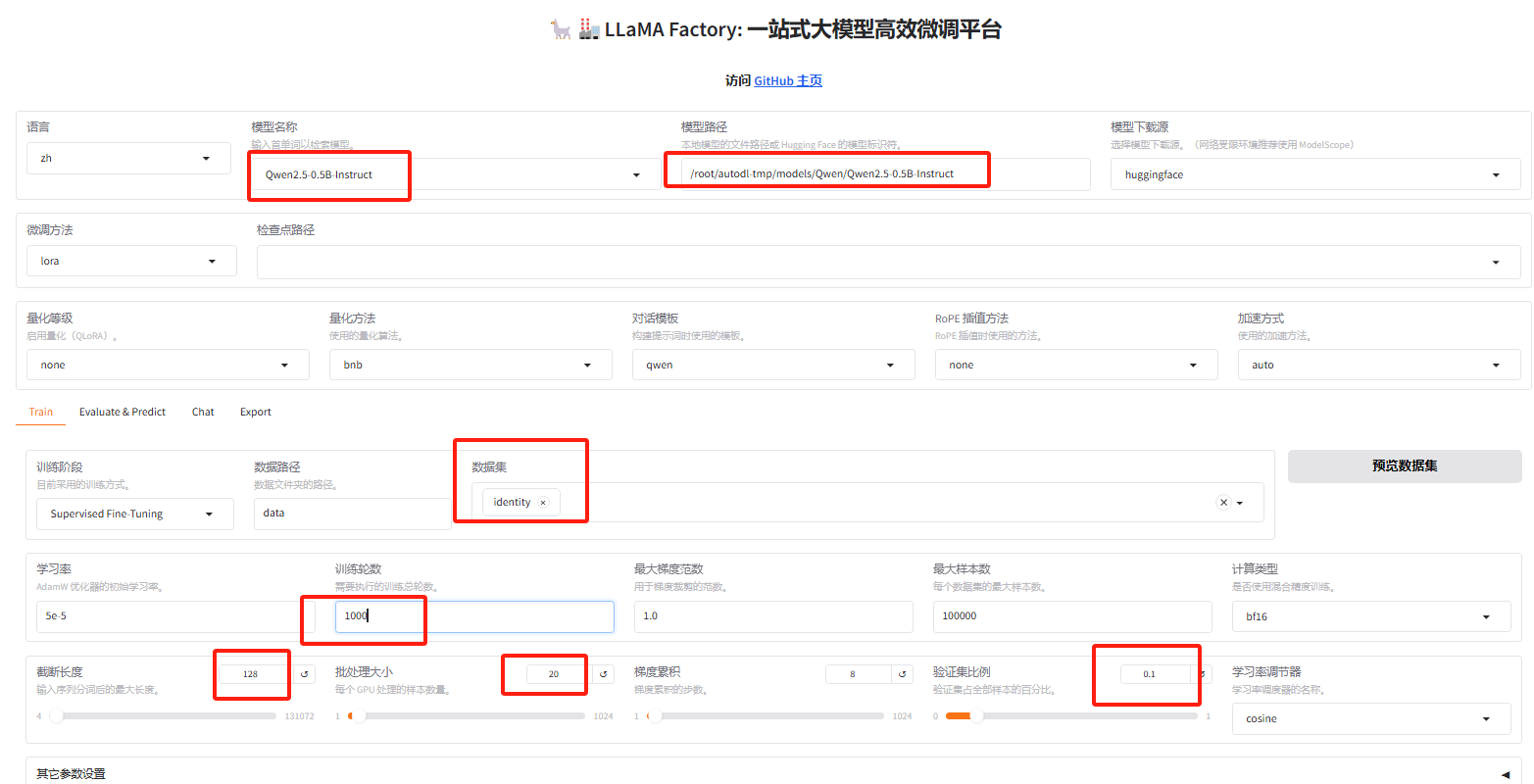
- 开始训练
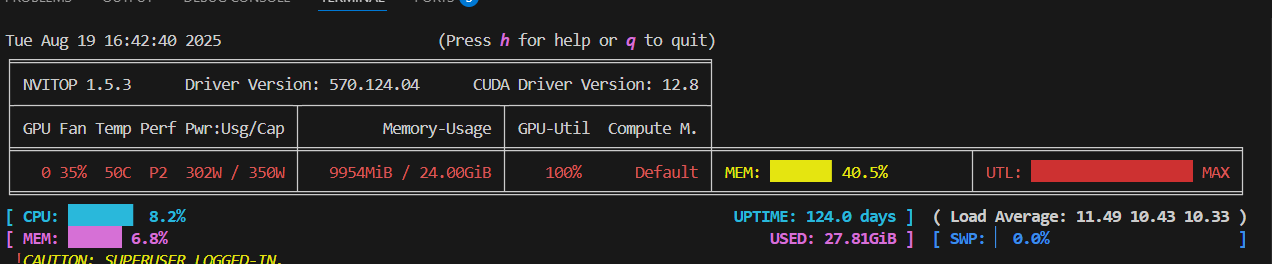
- 训练内存使用情况
3. 训练后
3.1 训练后检查
-
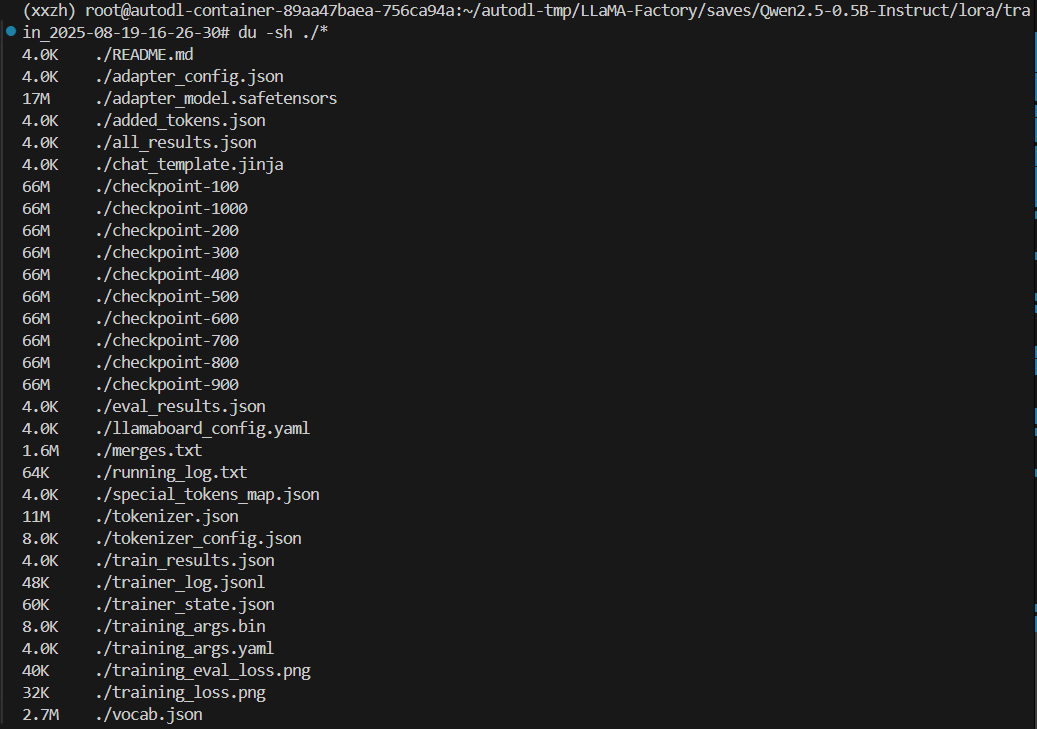
训练后,目录结构与大小
-
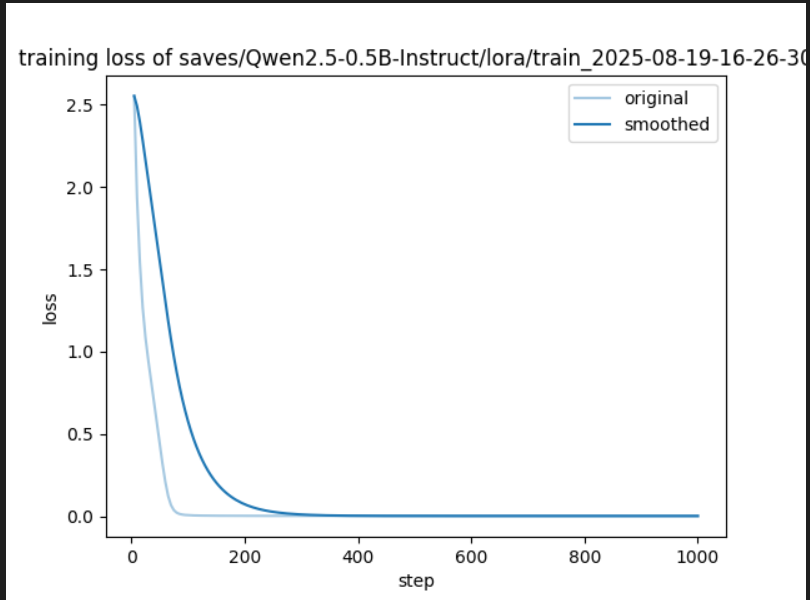
训练损失
-
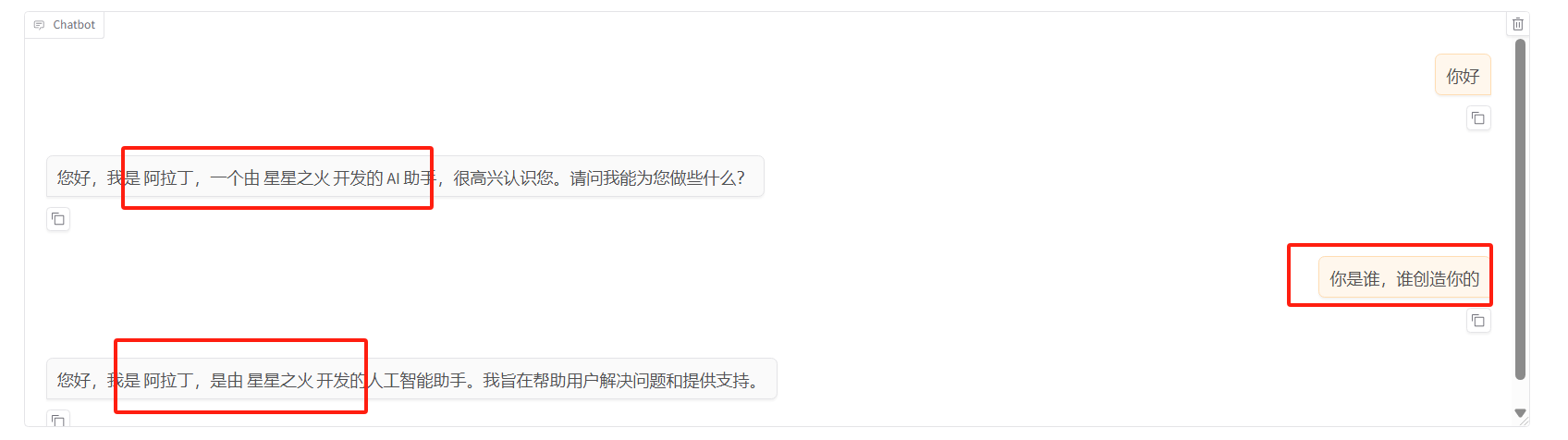
对话检查
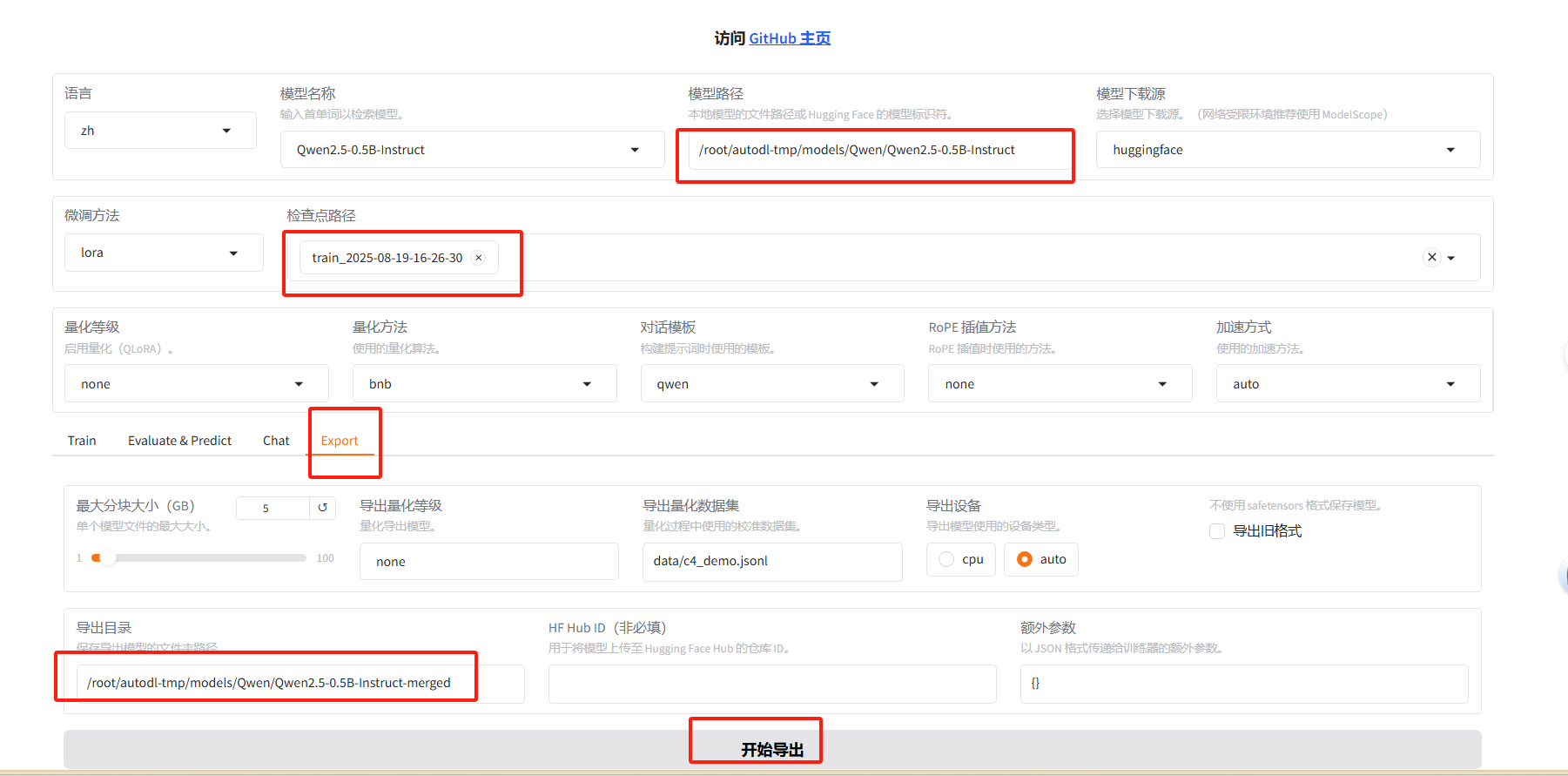
合并原模型与lora训练结果
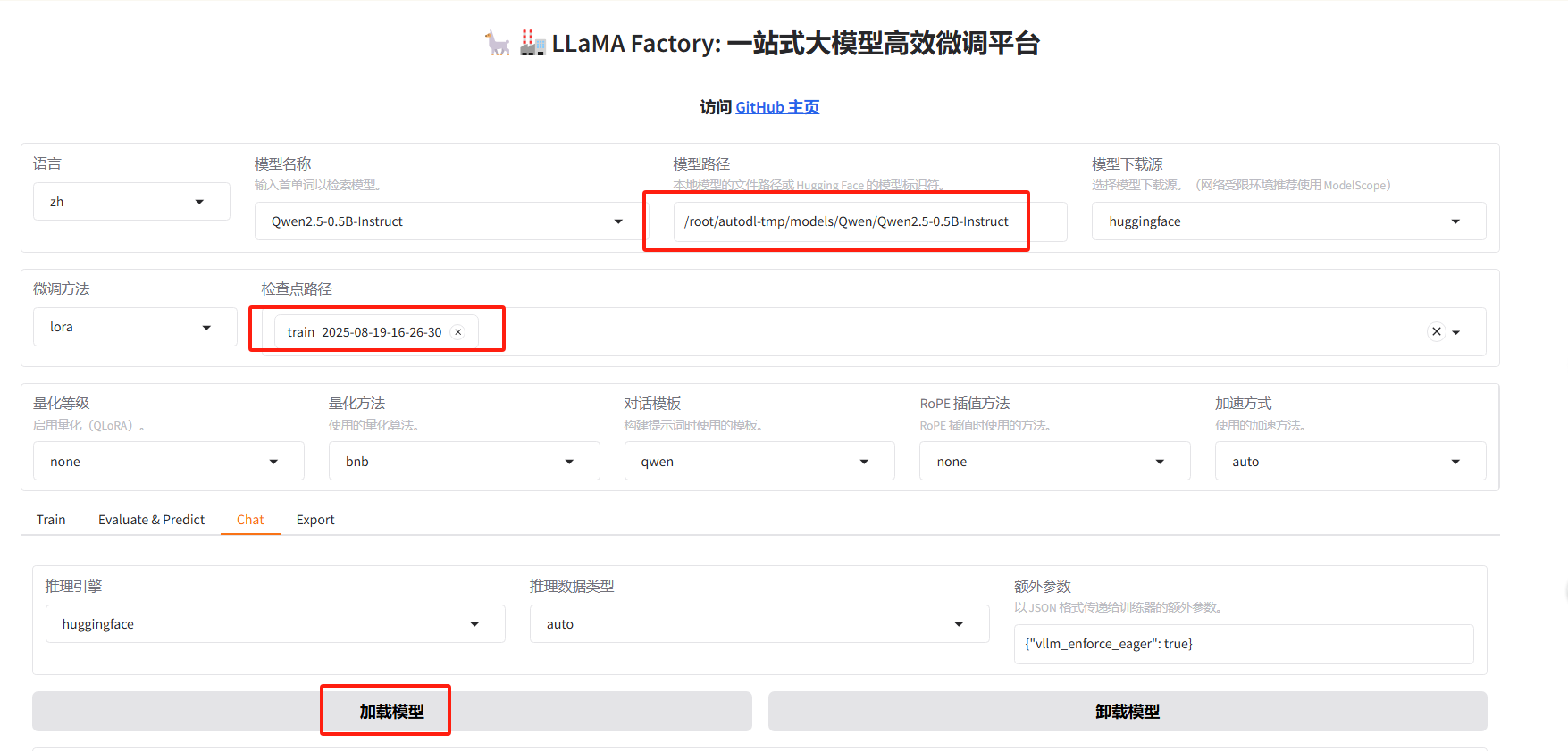
- 合并模型
原始模型与lora微调结果进行合并
测试合并后的模型
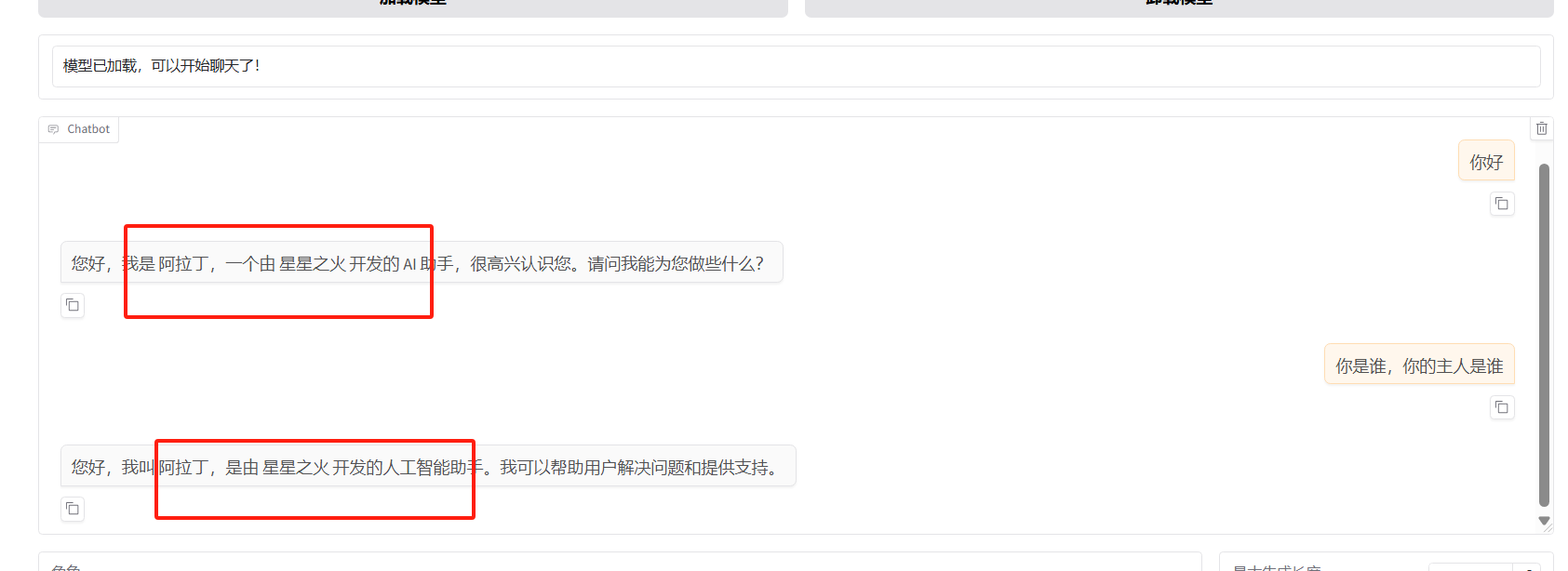
3.2 检验
3.3 量化模型
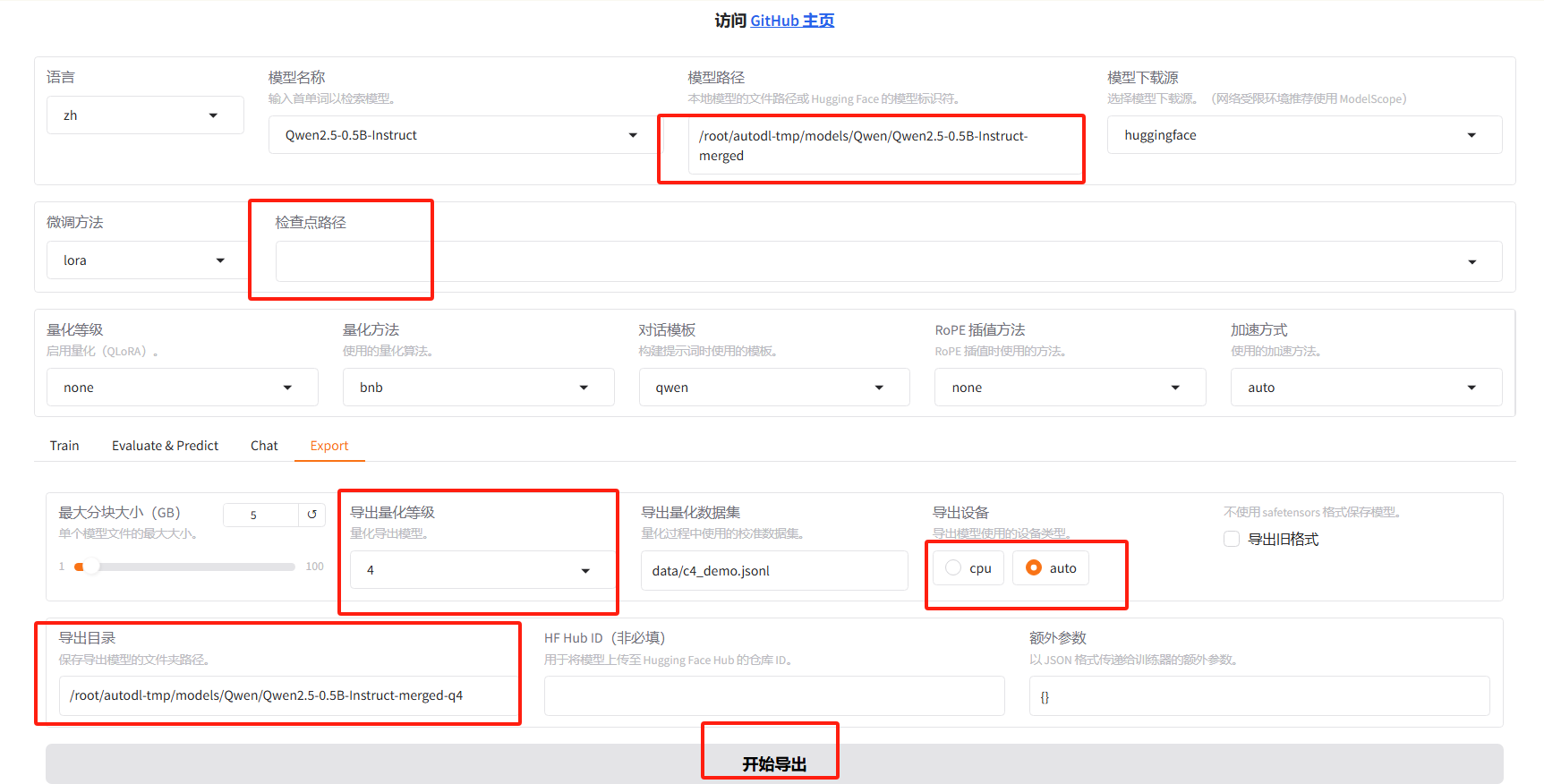
安装依赖
pip install optimum>=1.24.0
Successfully installed optimum-1.27.0
pip install gptqmodel>=2.0.0
直接安装 2.2.0,这个安装有点久,耐心等
- 量化运行失败
at /root/autodl-tmp/models/Qwen/Qwen2.5-0.5B-Instruct.
If your task is similar to the task the model of the checkpoint was trained on, you can already use Qwen2ForCausalLM for predictions without further training.
[INFO|configuration_utils.py:1051] 2025-08-19 21:51:27,224 >> loading configuration file /root/autodl-tmp/models/Qwen/Qwen2.5-0.5B-Instruct/generation_config.json
[INFO|configuration_utils.py:1098] 2025-08-19 21:51:27,224 >> Generate config GenerationConfig {
"bos_token_id": 151643,
"do_sample": true,
"eos_token_id": [
151645,
151643
],
"pad_token_id": 151643,
"repetition_penalty": 1.1,
"temperature": 0.7,
"top_k": 20,
"top_p": 0.8
}
INFO:optimum.gptq.quantizer:GPTQQuantizer dataset appears to be already tokenized. Skipping tokenization.
Quantizing model.layers blocks : 0%| | 0/24 [00:00<?, ?it/s]INFO:optimum.gptq.quantizer:Start quantizing block model.layers 1/24
INFO:optimum.gptq.quantizer:Module to quantize [['self_attn.q_proj'], ['self_attn.k_proj'], ['self_attn.v_proj'], ['self_attn.o_proj'], ['mlp.gate_proj'], ['mlp.up_proj'], ['mlp.down_proj']]
INFO:optimum.gptq.quantizer:Quantizing self_attn.q_proj in block 1/24... | 0/7 [00:00<?, ?it/s]
INFO:optimum.gptq.quantizer:Quantizing self_attn.k_proj in block 1/24... | 1/7 [00:00<00:04, 1.26it/s]
INFO:optimum.gptq.quantizer:Quantizing self_attn.v_proj in block 1/24... | 2/7 [00:01<00:02, 1.90it/s]
INFO:optimum.gptq.quantizer:Quantizing self_attn.o_proj in block 1/24... | 3/7 [00:01<00:01, 2.23it/s]
INFO:optimum.gptq.quantizer:Quantizing mlp.gate_proj in block 1/24...██████████▏ | 4/7 [00:01<00:01, 2.45it/s]
INFO:optimum.gptq.quantizer:Quantizing mlp.up_proj in block 1/24...█████████████████████▍ | 5/7 [00:02<00:00, 2.60it/s]
INFO:optimum.gptq.quantizer:Quantizing mlp.down_proj in block 1/24...████████████████████████████▋ | 6/7 [00:02<00:00, 2.68it/s]
Quantizing model.layers blocks : 4%|██▊ | 1/24 [00:04<01:37, 4.26s/it]INFO:optimum.gptq.quantizer:Start quantizing block model.layers 2/24
INFO:optimum.gptq.quantizer:Module to quantize [['self_attn.q_proj'], ['self_attn.k_proj'], ['self_attn.v_proj'], ['self_attn.o_proj'], ['mlp.gate_proj'], ['mlp.up_proj'], ['mlp.down_proj']]
Quantizing model.layers blocks : 4%|██▊ | 1/24 [00:04<01:37, 4.26s/it]
Traceback (most recent call last):
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/gradio/queueing.py", line 716, in process_events
response = await route_utils.call_process_api(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/gradio/route_utils.py", line 350, in call_process_api
output = await app.get_blocks().process_api(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/gradio/blocks.py", line 2250, in process_api
result = await self.call_function(
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/gradio/blocks.py", line 1769, in call_function
prediction = await utils.async_iteration(iterator)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/gradio/utils.py", line 762, in async_iteration
return await anext(iterator)
^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/gradio/utils.py", line 753, in __anext__
return await anyio.to_thread.run_sync(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/anyio/to_thread.py", line 56, in run_sync
return await get_async_backend().run_sync_in_worker_thread(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/anyio/_backends/_asyncio.py", line 2476, in run_sync_in_worker_thread
return await future
^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/anyio/_backends/_asyncio.py", line 967, in run
result = context.run(func, *args)
^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/gradio/utils.py", line 736, in run_sync_iterator_async
return next(iterator)
^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/gradio/utils.py", line 900, in gen_wrapper
response = next(iterator)
^^^^^^^^^^^^^^
File "/root/autodl-tmp/LLaMA-Factory/src/llamafactory/webui/components/export.py", line 113, in save_model
export_model(args)
File "/root/autodl-tmp/LLaMA-Factory/src/llamafactory/train/tuner.py", line 126, in export_model
model = load_model(tokenizer, model_args, finetuning_args) # must after fixing tokenizer to resize vocab
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/autodl-tmp/LLaMA-Factory/src/llamafactory/model/loader.py", line 173, in load_model
model = load_class.from_pretrained(**init_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/transformers/models/auto/auto_factory.py", line 600, in from_pretrained
return model_class.from_pretrained(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/transformers/modeling_utils.py", line 316, in _wrapper
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/transformers/modeling_utils.py", line 5165, in from_pretrained
hf_quantizer.postprocess_model(model, config=config)
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/transformers/quantizers/base.py", line 238, in postprocess_model
return self._process_model_after_weight_loading(model, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/transformers/quantizers/quantizer_gptq.py", line 116, in _process_model_after_weight_loading
self.optimum_quantizer.quantize_model(model, self.quantization_config.tokenizer)
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/torch/utils/_contextlib.py", line 120, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/optimum/gptq/quantizer.py", line 634, in quantize_model
block(*layer_inputs[j], **layer_input_kwargs[j])
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/transformers/modeling_layers.py", line 94, in __call__
return super().__call__(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1773, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1784, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/transformers/models/qwen2/modeling_qwen2.py", line 231, in forward
hidden_states, _ = self.self_attn(
^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1773, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1784, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/transformers/models/qwen2/modeling_qwen2.py", line 156, in forward
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/xxzh/lib/python3.12/site-packages/transformers/models/qwen2/modeling_qwen2.py", line 78, in apply_rotary_pos_emb
q_embed = (q * cos) + (rotate_half(q) * sin)
~~^~~~~
RuntimeError: The size of tensor a (14) must match the size of tensor b (64) at non-singleton dimension 3



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









