






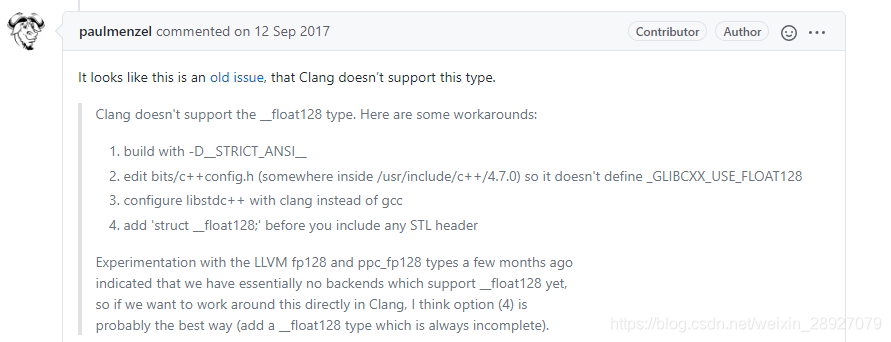
参照这哥们的方法,我采用了第三种方法,指定sysroot为ndk的std路径取代gcc的std头文件路径
修改makefile,根据你实际的makefile进行修改sysroot
CROSS_SYSROOT=/android-ndk-r14b/platforms/android-22/arch-arm64
编译通过

参照这哥们的方法,我采用了第三种方法,指定sysroot为ndk的std路径取代gcc的std头文件路径
修改makefile,根据你实际的makefile进行修改sysroot
CROSS_SYSROOT=/android-ndk-r14b/platforms/android-22/arch-arm64
编译通过

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 1232
1232





