





 本文介绍了偏差、方差、欠拟合和过拟合的概念。偏差是训练数据的错误率,高偏差表示模型过于简单,可能导致欠拟合。方差是测试数据的错误率,高方差表示模型可能过拟合。模型的复杂度与偏差和方差之间存在权衡,理想的模型应同时在训练和测试数据上表现良好。
本文介绍了偏差、方差、欠拟合和过拟合的概念。偏差是训练数据的错误率,高偏差表示模型过于简单,可能导致欠拟合。方差是测试数据的错误率,高方差表示模型可能过拟合。模型的复杂度与偏差和方差之间存在权衡,理想的模型应同时在训练和测试数据上表现良好。
Assume you have a classification model, training data and testing data
假设您有一个分类模型,训练数据和测试数据
x_train , y_train // This is the training data
x_test , y_test // This is the testing data
y_predicted // the values predicted by the model given an inputThe error rate is the average error of value predicted by the model and the correct value.
误差率是模型预测的值和正确值的平均误差。
偏压 (Bias)
Let’s assume we have trained the model and are trying to predict values with input ‘x_train’. The predicted values are y_predicted. Bias is the error rate of y_predicted and y_train.
假设我们已经训练了模型,并尝试使用输入“ x_train”预测值。 预测值是y_predicted。 偏差是y_predicted和y_train的错误率。
In simple terms,think of bias as the error rate of the training data.
简而言之,可以将偏差视为训练数据的错误率。
When the error rate is high, we call it High Bias and when the error rate is low, we call it Low Bias
当错误率高时,我们将其称为高偏差;当错误率低时,我们将其称为低偏差
方差(Variance)
Let’s assume we have trained the model and this time we are trying to predict values with input ‘x_test’. Again, the predicted values are y_predicted. Variance is the error rate of the y_predicted and y_test
假设我们已经训练了模型,这次我们尝试使用输入“ x_test”预测值。 同样,预测值是y_predicted。 方差是y_predicted和y_test的错误率
In simple terms, think of variance as the error rate of the testing data.
简单来说,将方差视为测试数据的错误率。
When the error rate is high, we call it High Variance and when the error rate is low, we call it Low Variance
当错误率高时,我们称之为高方差;当错误率低时,我们称之为低方差。
不合身 (Underfitting)
When the model has a high error rate in the training data, we can say the model is underfitting. This usually occurs when the number of training samples is too low. Since our model performs badly on the training data, it consequently performs badly on the testing data as well.
当模型在训练数据中的错误率很高时,可以说该模型不适合。 这通常在训练样本数太少时发生。 由于我们的模型在训练数据上表现不佳,因此在测试数据上也表现不佳。
A high error rate in training data implies a High Bias, therefore
训练数据中的高错误率意味着较高的偏差,因此
In simple terms, High Bias implies underfitting
简而言之,高偏差意味着拟合不足
过度拟合(OverFitting)
When the model has a low error rate in training data but a high error rate in testing data, we can say the model is overfitting. This usually occurs when the number of training samples is too high or the hyperparameters have been tuned to produce a low error rate on the training data.
当模型的训练数据错误率低而测试数据的错误率高时,可以说该模型过度拟合。 这通常在训练样本的数量过多或超参数已调整为对训练数据产生低错误率时发生。
Think of a student who studied a certain set of questions and then gave a mock exam which contains those exact questions they studied. They might do well on the mock exam but on the real exam, which contains unseen questions, they might not necessarily do well. If the student gets a 95% in the mock exam but a 50% in the real exam, we can call it overfitting.
想像一下一个学生,该学生研究了一组特定的问题,然后进行了模拟考试,其中包含了他们所研究的确切问题。 他们可能会在模拟考试中表现不错,但在包含未解决问题的真实考试中,他们不一定会做得很好。 如果学生在模拟考试中获得95%但在真实考试中获得50%,我们可以称其为过拟合。
A low error rate in training data implies Low Bias whereas a high error rate in testing data implies a High Variance, therefore
训练数据中的低错误率意味着较低的偏差,而测试数据中的高错误率意味着较高的方差,因此
In simple terms, Low Bias and Hight Variance implies overfittting
简单来说,低偏差和高方差意味着过度拟合
过度拟合,回归拟合不足(Overfitting, Underfitting in Regression)
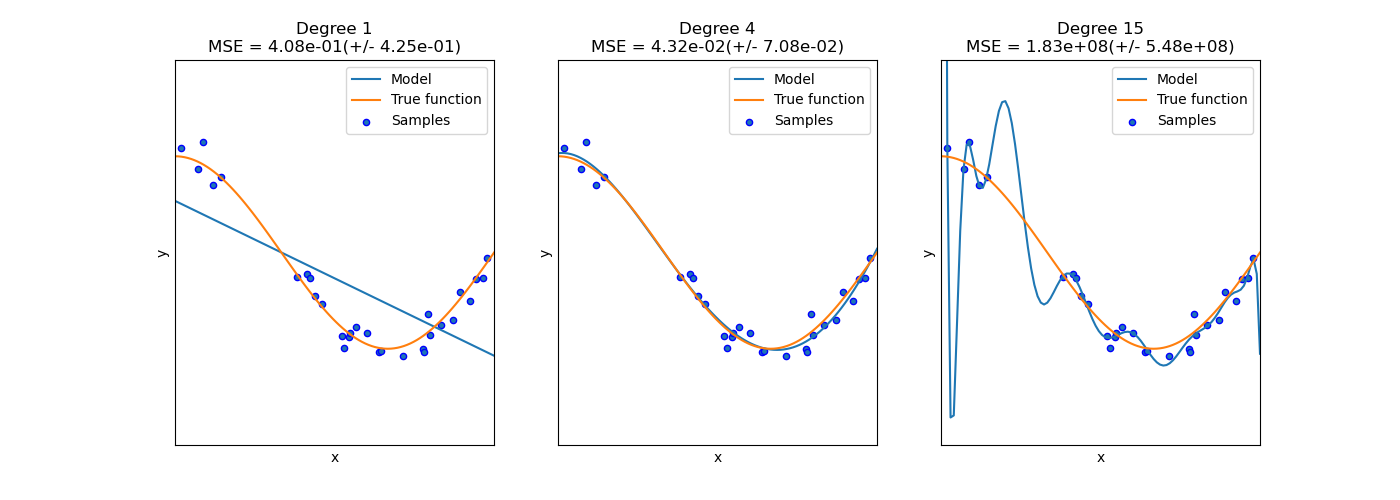
In the first image, we try to fit the data using a linear equation. The model is rigid and not at all flexible. Due to the low flexibility of a linear equation, it is not able to predict the samples (training data), therefore the error rate is high and it has a High Bias which in turn means it’s underfitting. This model won’t perform well on unseen data.
在第一张图片中,我们尝试使用线性方程拟合数据。 该模型是刚性的,而不是完全柔性的。 由于线性方程式的灵活性低,它无法预测样本(训练数据),因此错误率很高,并且具有较高的偏差,这又意味着拟合不足。 该模型在看不见的数据上表现不佳。
In the second image, we use an equation with degree 4. The model is flexible enough to predict most of the samples correctly but rigid enough to avoid overfitting. In this case, our model will be able to do well on the testing data therefore this is an ideal model.
在第二个图像中,我们使用一个度数为4的方程。该模型足够灵活以正确地预测大多数样本,但是足够刚性以避免过度拟合。 在这种情况下,我们的模型将能够很好地处理测试数据,因此这是一个理想的模型。
In the third image, we use an equation with degree 15 to predict the samples. Although it’s able to predict almost all the samples, it has too much flexibility and will not be able to perform well on unseen data. As a result, it will have a high error rate in testing data. Since it has a low error rate in training data (Low Bias) and high error rate in training data (High Variance), it’s overfitting.
在第三张图片中,我们使用度数为15的方程式来预测样本。 尽管它能够预测几乎所有样本,但是它具有很大的灵活性,并且无法在看不见的数据上表现良好。 结果,它将在测试数据中具有较高的错误率。 由于它在训练数据中具有较低的错误率(低偏差),而在训练数据中具有较高的错误率(高方差),因此过拟合。
分类中的过拟合,欠拟合 (Overfitting, Underfitting in Classification)
Assume we have three models ( Model A , Model B , Model C) with the following error rates on training and testing data.
假设我们有三个模型(模型A,模型B,模型C),它们在训练和测试数据上的错误率如下。
+---------------+---------+---------+---------+
| Error Rate | Model A | Model B | Model C |
+---------------+---------+---------+---------+
| Training Data | 30% | 6% | 1% |
+---------------+---------+---------+---------+
| Testing Data | 45% | 8% | 25% |
+---------------+---------+---------+---------+For Model A, The error rate of training data is too high as a result of which the error rate of Testing data is too high as well. It has a High Bias and a High Variance, therefore it’s underfit. This model won’t perform well on unseen data.
对于模型A,训练数据的错误率太高,因此测试数据的错误率也太高。 它具有较高的偏差和较高的方差,因此不适合。 该模型在看不见的数据上表现不佳。
For Model B, The error rate of training data is low and the error rate ofTesting data is low as well. It has a Low Bias and a Low Variance, therefore it’s an ideal model. This model will perform well on unseen data.
对于模型B,训练数据的错误率低,测试数据的错误率也低。 它具有低偏差和低方差,因此是理想模型。 该模型将在看不见的数据上表现良好。
For Model C, The error rate of training data is too low. However, the error rate of Testing data is too high as well. It has a Low Bias and a High Variance, therefore it’s overfit. This model won’t perform well on unseen data.
对于模型C,训练数据的错误率太低。 但是,测试数据的错误率也太高。 它具有低偏差和高方差,因此过拟合。 该模型在看不见的数据上表现不佳。
偏差-偏差权衡 (Bias-Variance Tradeoff)
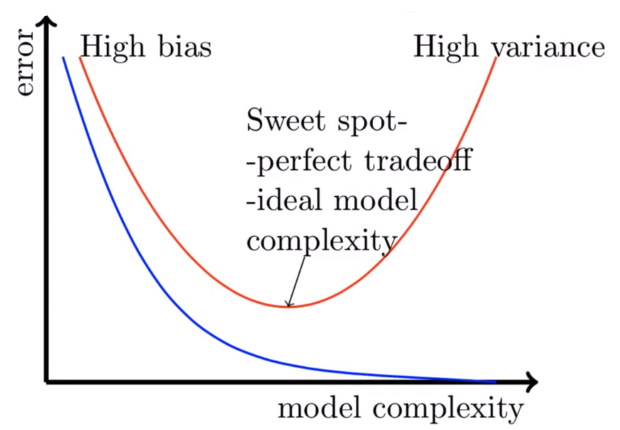
When the model’s complexity is too low, i.e a simple model, the model won’t be able to perform well on the training data nor the testing data, therefore it’s underfit
当模型的复杂度太低(即简单模型)时,该模型将无法在训练数据或测试数据上表现良好,因此不适合
At the sweet spot, the model has a low error rate on the training data as well as the testing data, therefore, that’s the ideal model
最棒的是,该模型在训练数据和测试数据上的错误率都很低,因此,这是理想的模型
As the complexity of the model increases, the model performs well on the training data but it doesn’t perform well on the testing data and therefore it’s overfit
随着模型复杂度的增加,模型在训练数据上的性能很好,但是在测试数据上的性能不好,因此过拟合
Thank You for reading the article. Please let me know if I made any mistakes or have any misconceptions. Always happy to receive feedback :)
感谢您阅读本文。 如果我有任何错误或任何误解,请告诉我。 总是很高兴收到反馈:)

















 6030
6030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









