





 本文介绍了一种基于立体视觉的方法,用于在动态自动驾驶场景中同时处理3D语义对象定位和相机自我运动的精确估计。通过2D物体检测、视点分类、特征匹配和多约束优化,系统能有效融合3D框预测、ego-motion跟踪以及车辆动力学约束。该方法不仅提升了性能,还在复杂场景中展示了鲁棒性。
本文介绍了一种基于立体视觉的方法,用于在动态自动驾驶场景中同时处理3D语义对象定位和相机自我运动的精确估计。通过2D物体检测、视点分类、特征匹配和多约束优化,系统能有效融合3D框预测、ego-motion跟踪以及车辆动力学约束。该方法不仅提升了性能,还在复杂场景中展示了鲁棒性。
语义视觉
Localizing dynamic objects and estimating the camera ego-motion in 3D space are crucial tasks for autonomous driving. Currently, these objectives are separately explored by end-to-end 3D object detection methods and traditional visual SLAM approaches. However, it is hard to directly employ these approaches for autonomous driving scenarios.
定位动态对象并估算3D空间中的相机自我运动是自动驾驶的关键任务。 当前,这些目标是通过端到端3D对象检测方法和传统的视觉SLAM方法分别探索的。 但是,很难将这些方法直接用于自动驾驶场景。
[1] propose a stereo vision-based approach for tracking the camera ego-motion and 3D semantic objects in dynamic autonomous driving scenarios.
[1]提出了一种基于立体视觉的方法,用于在动态自动驾驶场景中跟踪相机的自我运动和3D语义对象。
The entire system framework consists of three parts:
整个系统框架包括三个部分:
- 2D object detection and viewpoint classification, the target pose is solved through 2D-3D constraints; 2D物体检测和视点分类,通过2D-3D约束解决目标姿态;
- Feature extraction and matching of binocular front and rear frames, projects all the inferred 3D boxes to the 2D image to get the objects contour and occlusion masks. 双目前后框架的特征提取和匹配,将所有推断的3D框投影到2D图像,以获取对象的轮廓和遮挡蒙版。
- Ego-motion and object tracking, adding semantic information and feature quantities to optimization, and adding vehicle dynamics constraints to obtain smooth motion estimation. 自我运动和对象跟踪,添加语义信息和特征量以进行优化,并添加车辆动力学约束以获得平稳的运动估计。
They use Faster R-CNN on the left images for object detection and instead of the pure object classification in the original implementation , they add sub-categories classification in the final FC layers, which denotes object horizontal and vertical discrete viewpoints.
他们在左侧图像上使用Faster R-CNN进行对象检测,而不是原始实现中的纯对象分类,而是在最终FC层中添加了子类别分类,这表示对象水平和垂直离散视点。
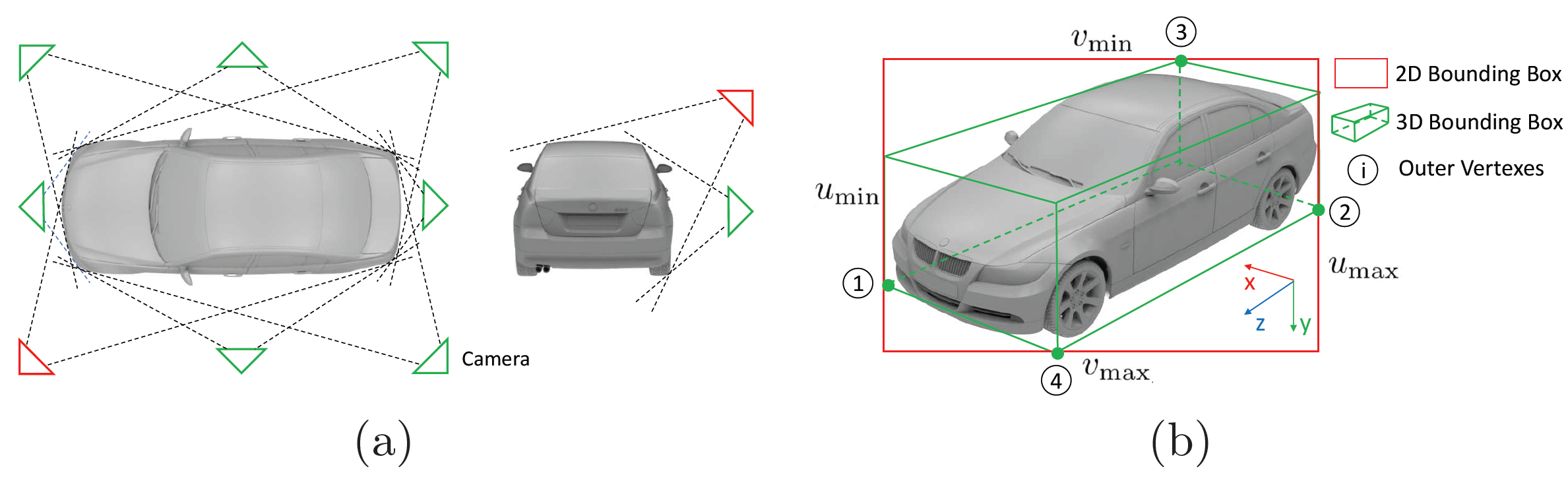
The horizontal field of view is divided into eight categories, and the vertical field of view is divided into two categories, totaling 16 categories.
水平视场分为八个类别,垂直视场分为两个类别,共16个类别。
Given the 2D box described by four edges in normalized image plane [u_min, v_min, u_max, v_max] and classified viewpoint, we aim to infer the object pose based on four constriants between 2D box edges and 3D box vertexes.
给定2D框由归一化图像平面中的四个边缘[u_min,v_min,u_max,v_max]和分类视点描述,我们旨在基于2D框边缘和3D框顶点之间的四个约束来推断对象姿态。
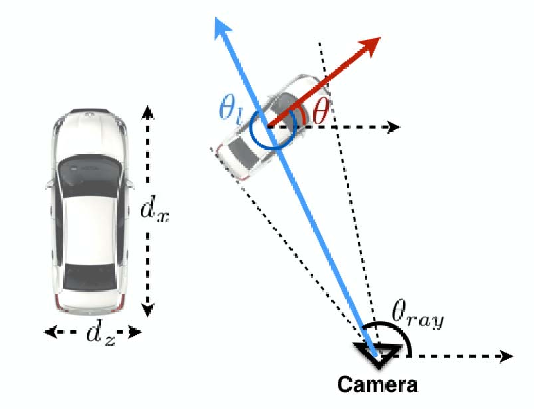
A 3D bounding box can be represented by its center position p = [x, y, z] and horizontal orientation θ respecting to camera frame and the dimensions prior [w, h, l] .At this time, we assume:
一个3D边界框可以用其中心位置p = [x,y,z]和相对于相机框架的水平方向θ以及尺寸[w,h,l]来表示。这时,我们假定:
- 2D frame is accurate; 2D画面准确;
- The size of each vehicle is the same. 每辆车的大小是相同的。
- The 2D frame can closely surround the 3D frame. 2D框架可以紧密围绕3D框架。
Under the above assumptions, we can obtain a 3D box, which is used as the initial value for subsequent optimization. In this perspective, four constraint equations can be obtained for the vertices of the four 3D boxes. The overturning process is:
在上述假设下,我们可以获得一个3D框,该框用作后续优化的初始值。 从这个角度来看,可以为四个3D盒子的顶点获得四个约束方程。 推翻过程是:
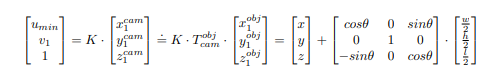
Where, K is the camera internal parameter, which is normalized and eliminated, T^{obj}_{cam} is the representation of the target center coordinate system in the camera coordinate system. Similarly, under this field of vision, we can be obtain:
其中,K是已标准化并消除的相机内部参数,T ^ {obj} _ {cam}是相机坐标系中目标中心坐标系的表示。 同样,在这个视野下,我们可以获得:

After normalizing the z direction, the final four constraints are further obtained:
将z方向归一化后,进一步获得了最后四个约束:
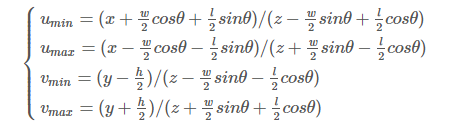
The above four equations can be solved in a closed form for the 3D box .This method decomposes the 3D box regression solution into 2D box regression, viewing angle classification, and the process of solving equations.
可以将上述四个方程以封闭形式求解3D盒子。该方法将3D盒子回归解决方案分解为2D盒子回归,视角分类和方程求解过程。
They project the inferred 3D object boxes to the stereo images to generate a valid 2D contour. They extract ORB features for both the left and right image in the visible area for each object and the background.Stereo matching is performed by epipolar line searching,since the distance and size of the target are known, it is only necessary to search and match the feature points in a certain small range.
他们将推断的3D对象框投影到立体图像以生成有效的2D轮廓。 他们为每个对象和背景在可见区域中提取左右图像的ORB特征。通过对极线搜索进行立体匹配,因为已知目标的距离和大小,所以仅需要搜索和匹配特征点在一定范围内。
For temporal matching, they first associate objects for successive frames by 2D box similarity score voting. The similarity score is weighted by the center distance and shape similarity of the 2D boxes between successive images after compensating the camera rotation.
对于时间匹配,它们首先通过2D框相似度评分投票将连续帧的对象相关联。 在补偿相机旋转之后,通过连续图像之间2D框的中心距离和形状相似度对相似度分数进行加权。
The object is treated as lost if its maximum similarity score with all the objects in the previous frame is less than a threshold. They subsequently match ORB features for the associated objects and background with the previous frame. Outliers are rejected by RANSAC with local fundamental matrix test for each object and background independently.
如果该对象与前一帧中所有对象的最大相似性分数小于阈值,则将其视为丢失。 随后,它们将关联对象和背景的ORB功能与前一帧相匹配。 RANSAC通过对每个对象和背景分别进行局部基本矩阵测试来排除异常值。
The vehicle motion state estimation can be done under the traditional SLAM framework. The difference is that the feature points in the dynamic obstacle are removed. After having the pose of the vehicle, the motion state of the dynamic obstacle is estimated.
车辆运动状态估计可以在传统的SLAM框架下完成。 不同之处在于动态障碍中的特征点已删除。 在具有车辆的姿势之后,估计动态障碍物的运动状态。
Given the observations of the feature points in the background area of the current and subsequent frames on the left, the state of the vehicle can be estimated by maximum likelihood estimation that can be transformed into a nonlinear least squares problem, which is the process of Bundle Adjustment, which is a typical SLAM problem. The error equation given as :
给定在左侧当前帧和后续帧的背景区域中的特征点的观察结果,可以通过最大似然估计来估计车辆的状态,该最大似然估计可以转换为非线性最小二乘问题,这是一个过程捆绑包调整,这是一个典型的SLAM问题。 误差方程式为:
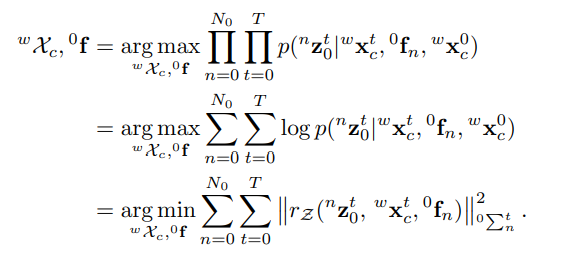
That needs to be solved is the position of the vehicle and the coordinates of the background feature points. This is the posterior probability, which can be solved by the likelihood function, and then transformed into a nonlinear optimization problem.
需要解决的是车辆的位置和背景特征点的坐标。 这是后验概率,可以通过似然函数求解,然后转化为非线性优化问题。
After obtaining the pose of the camera of the vehicle, the state estimation of the moving target can be obtained by the maximum posterior probability estimation. Similarly, it can be turned into a nonlinear optimization problem to solve, and jointly optimize the pose , size , speed , steering wheel angle , and 3D position of all feature points of each vehicle . There are four loss items:
在获得车辆的摄像机的姿势之后,可以通过最大后验概率估计来获得运动目标的状态估计。 同样,可以将其转化为非线性优化问题,以解决并共同优化每辆车所有特征点的姿态,大小,速度,方向盘角度和3D位置。 有四个损失项目:
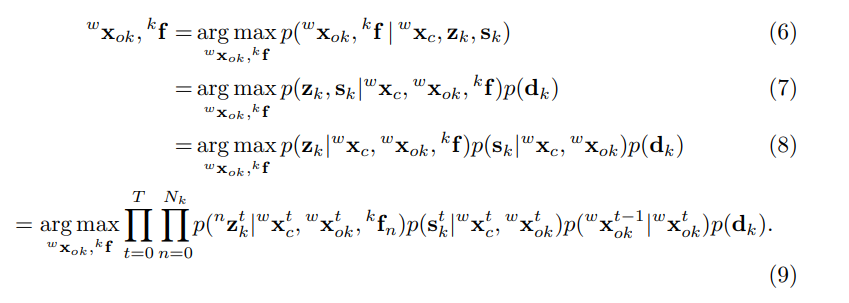
Similar to the equation above, we convert the MAP to a nonlinear optimization problem:
类似于上面的公式,我们将MAP转换为非线性优化问题:
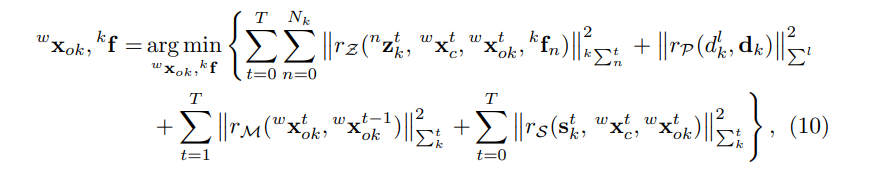
The performance of the proposed method is capable of performing robust ego-motion estimation and 3D object tracking in diverse scenarios.
所提出的方法的性能能够在各种情况下执行鲁棒的自我运动估计和3D对象跟踪。
It can be seen from the experiment that Sparse Feature Observation and Point Cloud Alignment can improve performance significantly, and Motion Model can improve performance in difficult scenarios.
从实验中可以看出,稀疏特征观察和点云对齐可以显着提高性能,而运动模型可以在困难的情况下提高性能。
翻译自: https://towardsdatascience.com/stereo-vision-based-semantic-3d-object-c901e38f9878
语义视觉


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









