






用Python开发的采集药师帮的数据。
(1)第一个文件需要用到云码,code_result.py :
class YdmVerify(object):
_custom_url = "http://api.jfbym.com/api/YmServer/customApi"
_token = "" #云码的token
_headers = {
'Content-Type': 'application/json'
}
def slide_verify(self, slide_image, background_image, verify_type="20101"):
payload = {
"slide_image": base64.b64encode(slide_image).decode(),
"background_image": base64.b64encode(background_image).decode(),
"token": self._token,
"type": verify_type
}
resp = requests.post(self._custom_url, headers=self._headers, data=json.dumps(payload))
print(resp.text)
return resp.json()['data']['data']
(2)采集文件,ysbs.py :
driver = webdriver.Chrome()
driver.maximize_window()
driver.get('https://dian.ysbang.cn/#/login?redirect=%2Fhome')
time.sleep(2)
name = driver.find_element(By.NAME, 'userAccount')
name.send_keys("") # 你的账号
pwd = driver.find_element(By.CSS_SELECTOR, "#password")
pwd.send_keys("") # 你的密码
login = driver.find_element(By.CLASS_NAME, 'btn')
login.click()
time.sleep(2)
Y = YdmVerify()
# ----------------------------
bg_src = driver.find_element(By.XPATH, '//*[@class="yidun_bg-img"]').get_attribute('src')
jigsaw_src = driver.find_element(By.XPATH, '//*[@class="yidun_jigsaw"]').get_attribute('src')
globalFunctions = GlobalFunctions()
globalFunctions.download_image_from_url(bg_src, "bg_src.png")
globalFunctions.download_image_from_url(jigsaw_src, "jigsaw_src.png")
bg_object = Image.open("bg_src.png")
width, height = bg_object.size
bg_width = width
print(bg_width)
with open("bg_src.png", 'rb') as f:
bg_src_content = f.read()
with open("jigsaw_src.png", 'rb') as f:
jigsaw_src_content = f.read()
resp = Y.slide_verify(jigsaw_src_content, bg_src_content)
print(resp)
el1 = driver.find_element(By.XPATH, '//*[@class="yidun_slide_indicator"]')
el2 = driver.find_element(By.XPATH, '//*[@class="yidun_control"]')
driver.implicitly_wait(2)
chains = webdriver.ActionChains(driver)
slide_distance = el2.size['width'] / bg_width * int(resp)
chains.drag_and_drop_by_offset(el1, slide_distance, 0)
chains.perform()
time.sleep(5)
def getData(page):
print(f"开始第{page}页数据获取")
encoded_text = urllib.parse.quote(searchkeyList[searchkeyIndex])
if page == 1:
driver.implicitly_wait(8)
time.sleep(8)
else:
driver.implicitly_wait(5)
time.sleep(5)
html = driver.page_source
parse = etree.HTML(html)
# 数据
all_tr = parse.xpath('//*[@id="wrapper"]/div[5]/div[3]/div')
i_04=0
for tr in all_tr:
i_04 = i_04 + 1
price2 = ''.join(tr.xpath('./div[2]/div[1]/div/span[2]/span/text()')).strip()
if len(price2) == 0:
price = ''.join(tr.xpath('./div[2]/div[1]/div/div/text()')).strip()
else:
price = ''.join(tr.xpath('./div[2]/div[1]/div/text()')).strip()
tr_data = {
'pzwh': searchkeyList[searchkeyIndex], # 号
'name': ''.join(tr.xpath('./div[2]/div[2]/span/text()')).strip(), # 名称
'price': price, # 价格
'price2': price2, # 折扣价
'commpany': ''.join(tr.xpath('./div[2]/div[4]/text()')).strip(), # 公司
'qjd': ''.join(tr.xpath('./div[3]/div[1]/span/a/text()')).strip(), # 旗舰店
'yxq': ''.join(tr.xpath('./div[1]/div/text()')).strip(), # 有效期
'img': ''.join(tr.xpath('./div[1]/img/@src')).strip(), # 图片
'page': page , # 页码
'xuhao': i_04 , # 序号
'url': f"https://dian.ysbang.cn/#/indexContent?page=1&pagesize=60&classify_id=&searchkey=" + encoded_text + \
"&onlyTcm=0&operationtype=1&provider_filter=&qualifiedLoanee=0&factoryNames=&specs=&drugId=-1&tagId=&showRecentlyPurchasedFlag=true&onlyShowRecentlyPurchased=false&onlySimpleLoan=false&sn=&deliverFloor=0&purchaseLimitFloor=0&validMonthFloor=12&buttons=%5Bobject%20Object%5D&synonymId=0&activityType=%5B%5D&providerSelectList=%5B%5D&factorySelectList=%5B%5D&gradeNameSelectList=%5B%5D&exeStandardSelectList=%5B%5D&specSelectList=%5B%5D&classItem_0=null&classItem_1=null&classItem_2=null&tagName=&_t=1724147114984&_isReplace=true&trafficType=1", # 网页
}
# 表格
with open('ysb.csv', 'a', encoding='utf_8_sig', newline='') as fp:
fieldnames = ['pzwh','name', 'price', 'price2', 'commpany', 'qjd', 'yxq', 'img','page','xuhao','url']
writer = csv.DictWriter(fp, fieldnames)
writer.writerow(tr_data)
if len(all_tr) == 60:
return True
print(f"该号所有数据获取完成===========================")
# 创建csv文件
with open('ysb.csv', 'a', encoding='utf_8_sig', newline='') as fp:
header = ['批准文号','名称', '价格', '折扣价', '公司', '旗舰店', '有效期', '图片','页码','序号','网页']
writer = csv.writer(fp)
writer.writerow(header)
# 1.由于刚才已经关闭了数据库连接,需要重新创建Connection对象和Cursor对象
host = "xxx.xxx.xxx.xxx"
user = "sa"
pwd = "********"
db = "my_db"
con = pyodbc.connect(host=host,user=user,password=pwd,database=db,charset="utf8",DRIVER="ODBC Driver 17 for SQL Server")
cursor=con.cursor()
c = cursor.execute("select mch from T_ysbbj ")
# 2.查询结果保存到list_re
list_re=cursor.fetchall()
#print('result:===== ', list_re)
if len(list_re) <= 0:
tkinter.messagebox.showinfo('提示',""+'没检索到号!')
else:
print('result_name: ', list_re[0][0])
#数据成功提取出来了
con.close()
searchkeyList = []
for i_03 in range(len(list_re)):
searchkeyList.append(list_re[i_03][0])
# 打印结果
print("Data from database---------------:")
print(searchkeyList[0])
# 搜索关键字
#searchkeyList = ["复方丹参滴丸"]
searchkeyIndex = 0
encoded_text = urllib.parse.quote(searchkeyList[searchkeyIndex])
url = f"https://dian.ysbang.cn/#/indexContent?page=1&pagesize=60&classify_id=&searchkey=" + encoded_text + "&onlyTcm=0&operationtype=1&provider_filter=&qualifiedLoanee=0&factoryNames=&specs=&drugId=-1&tagId=&showRecentlyPurchasedFlag=true&onlyShowRecentlyPurchased=false&onlySimpleLoan=false&sn=&deliverFloor=0&purchaseLimitFloor=0&validMonthFloor=12&buttons=%5Bobject%20Object%5D&synonymId=0&activityType=%5B%5D&providerSelectList=%5B%5D&factorySelectList=%5B%5D&gradeNameSelectList=%5B%5D&exeStandardSelectList=%5B%5D&specSelectList=%5B%5D&classItem_0=null&classItem_1=null&classItem_2=null&tagName=&_t=1724147114984&_isReplace=true&trafficType=1"
print(url)
driver.get(url)
def circulate():
page = 1
for i in range(0, 999):
if getData(page):
page += 1
nextBtn = driver.find_element(By.CLASS_NAME, 'pagination-next')
nextBtn.click()
else:
global searchkeyIndex
if searchkeyIndex == len(searchkeyList) - 1:
driver.quit()
break
else:
searchkeyIndex += 1
searchInput = driver.find_element(By.ID, 'searchKey')
searchInput.send_keys(Keys.CONTROL, 'a')
searchInput.send_keys(Keys.DELETE)
searchInput.send_keys(searchkeyList[searchkeyIndex])
pzwh=searchkeyList[searchkeyIndex]
print("searchkeyList[searchkeyIndex]====" , searchkeyList[searchkeyIndex] )
searchBtn = driver.find_element(By.CLASS_NAME, 'search-btn')
searchBtn.click()
# print("searchBtn searchkeyIndex ", searchkeyIndex )
circulate()
break
circulate()
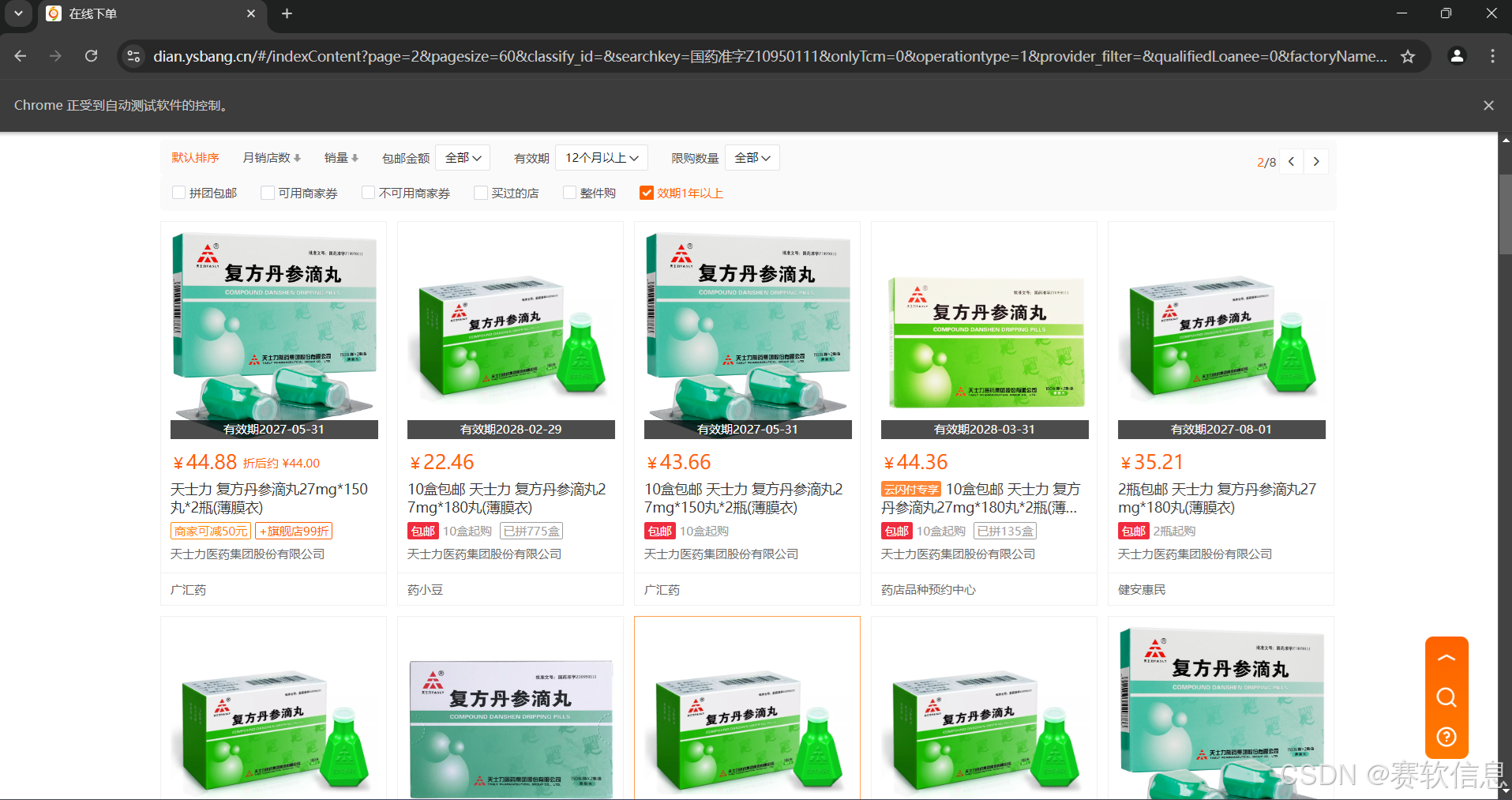
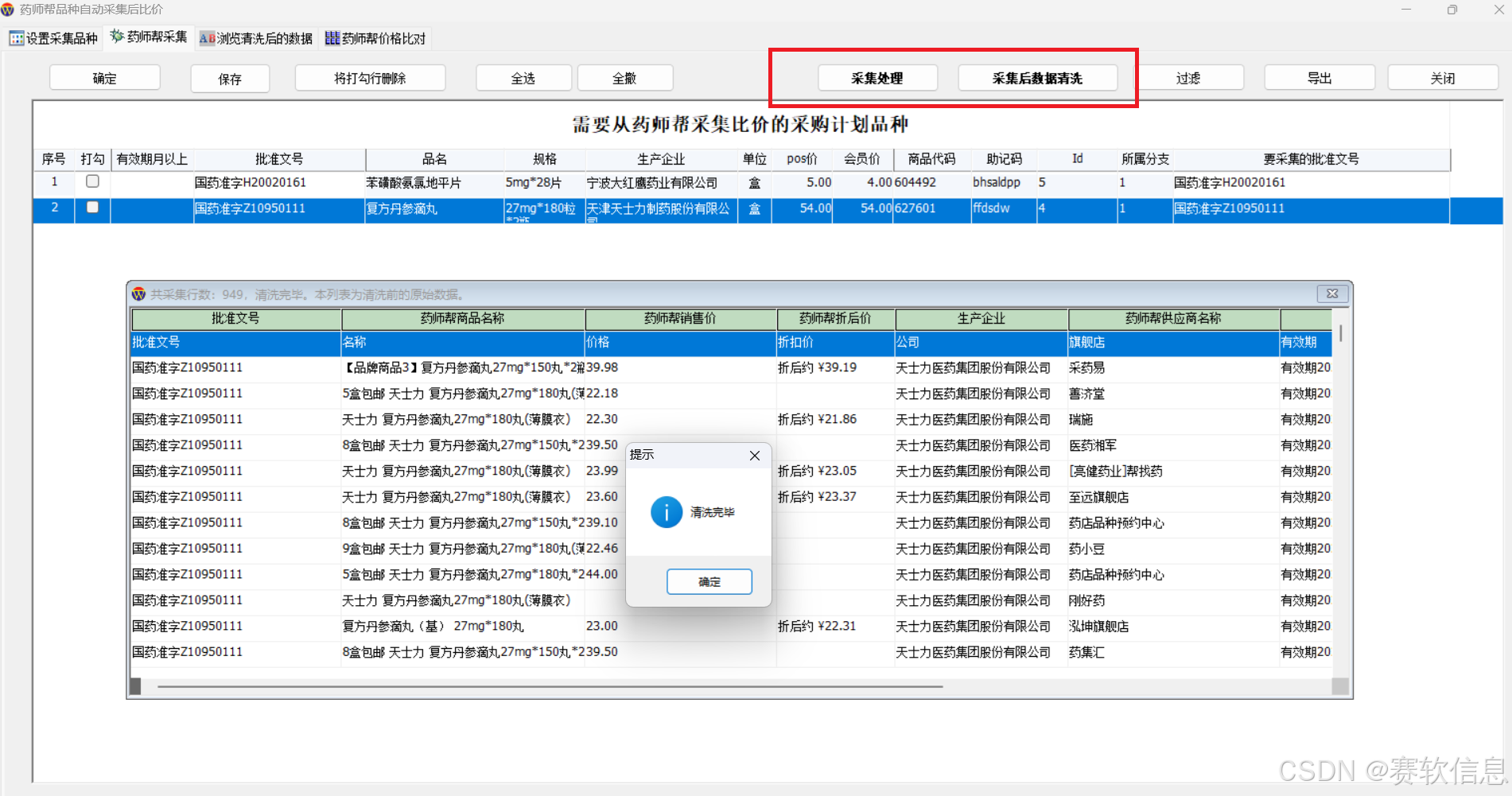
(3)效果图:

















 1479
1479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









