




ICLR 2024 Poster
paper
人类模仿学习过程是一个渐进的过程,不可能说当下的基础技能没学扎实,就模仿未来的目标。本篇文章便从这一个基本思想出发,通过自适应调整强化学习中折扣因子实现这一目标。实验环境设置在pixel-based observation-only 的演示下的模仿学习。
method
较小的折扣因子会让智能体注重当下但是却会表现得“短视”,因此需要随着训练的进行不断增加。算法通过一个过程识别器 Φ \Phi Φ输出一个0-T的整数k查询进度,以及一个单调递增函数 f γ ( k ) f_\gamma(k) fγ(k)更新 γ \gamma γ用于RL。
Φ \Phi Φ采用计算状态序列的最长单调递增子序列(LIS)。每当接收到最近收集的轨迹时,它就会考虑代理和演示轨迹的前 k + 1 步。如果代理与某些已演示轨迹之间的进度一致性与两个已演示专家轨迹之间的进度一致性相当,那就认为代理当前的策略可以在前 k 步中遵循演示。具体来说,如果下面的不等式成立,就将 k 增加1:
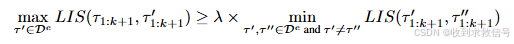
得到k后便是调整 γ \gamma γ : f γ ( k ) = α 1 / k f_\gamma(k) = \alpha^{1/k} f
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









