




ICML 2025 poster
离线到在线强化学习 (RL) 旨在通过离线预训练智能体,然后通过在线交互对其进行微调,从而整合离线和在线 RL 的互补优势。然而,最近的研究表明,由于分布偏移导致的不准确的价值估计,离线预训练的智能体在在线微调期间通常表现不佳,在某些情况下,随机初始化被证明更有效。在这项工作中提出了一种新颖的方法,即用于离线到在线 RL 的在线预训练 (OPT),它被明确设计用于解决离线预训练智能体中不准确的价值估计问题。 OPT 引入了一个新的学习阶段,即在线预训练,它允许训练一个新的价值函数,该函数专门为有效的在线微调量身定制。在 TD3 和 SPOT 上实施 OPT 表明,在包括 MuJoCo、Antmaze 和 Adroit 在内的各种 D4RL 环境中,性能平均提高了 30%
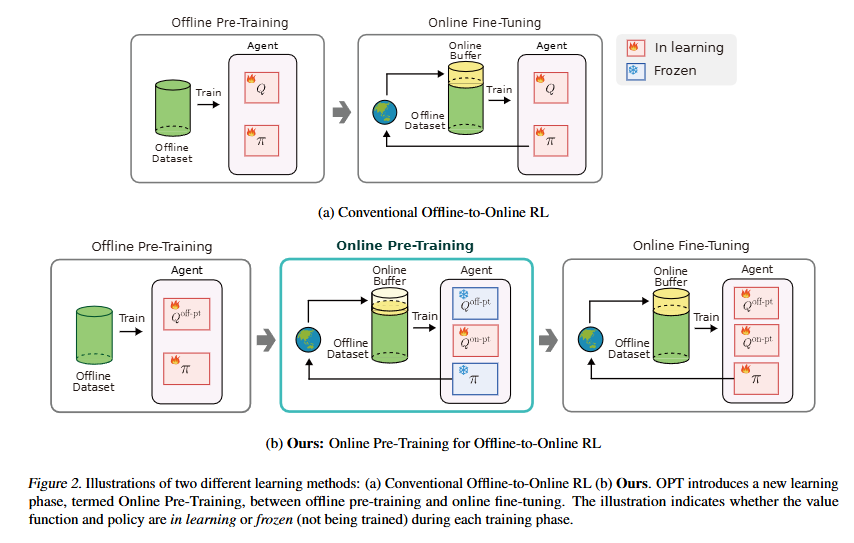
对比传统O2O的方法,中间引入了一个针对在线数据的Q学习,该过程中保留离线阶段Q与策略不参与更新,而是在第三阶段共同被更新。第二阶段的Q更新采用类似于OEMA的元更新
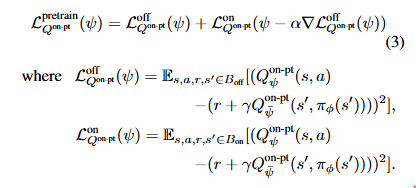
第三阶段的策略更新需要i同时用到这两个Q函数,因此采用一种加权模式
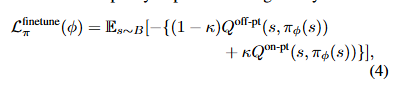
而各自的Q函数更新则回到原始均方bellman误差
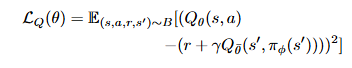
伪代码:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1110
1110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









