






Under review for TMLR 2025
离线强化学习 (RL) 旨在从静态数据集中学习有效的策略,而不需要进一步的智能体环境交互。然而,其在实践中的应用经常受到对显式奖励注释的需求的阻碍,这些注释的构建成本可能很高,或者难以追溯获得。为了解决这个问题,我们提出了 ReLOAD (Reinforcement Learning with Offline Reward Annotation via Distillation,即通过蒸馏进行离线奖励注释的强化学习),这是一个用于离线 RL 的新型奖励注释框架。与依赖复杂对齐程序的现有方法不同,我们的方法采用随机网络蒸馏 (RND),通过一种简单而有效的嵌入差异度量,从专家演示中生成内在奖励。首先,我们训练一个预测器网络,使其模仿一个固定的目标网络,该目标网络基于专家的状态转换进行嵌入。之后,这些网络之间的预测误差将作为静态数据集中每次转换的奖励信号。这种机制提供了一种结构化的奖励信号,而不需要手工制作的奖励注释。
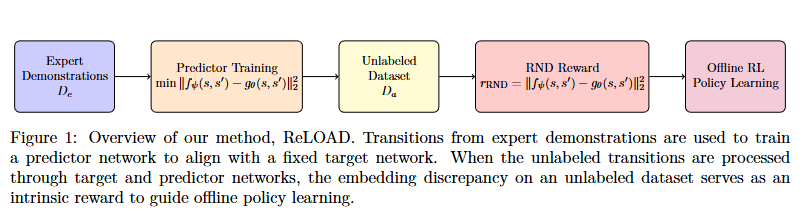
method
采用少量专家数据,基于RND网络预训练得到(s,s’)得状态表征差异。其中f是固定参数作为target。这里表明:与专家相似得无奖励标签样本在表征差异上具有相似性。
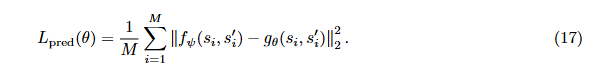
因此基于这个差异构建两种结构得奖励函数。
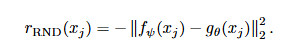
or
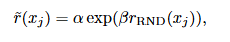
第二种方案经过在walker上的消融实验证明具备稳定性。

伪代码

文章给出理论性的证明,说明RND与离线下奖励构造目标上的一致性。
另外一篇ICML 2023关于RND的文章,但是关注的是(s,a),并作为价值函数的的惩罚项来避免估计问题:
Anti-Exploration by Random Network Distillation
本文在openreviwer种的rebuttal也提到了,基于(s,s’)的优势,以及连篇文章的区别。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









