







Intro
强化学习中,如今实现动力学差异下的域自适应是重要研究课题。本文问题背景设定在源域和目标域之间存在动力学不匹,智能体可以获得足够的源主数据,但只能与目标域进行有限的交互。文章提出表征解耦的方法解决该问题,即只在目标域进行表征学习,源域则是利用表征后的差异作为惩罚项实现reward shaping。该过程有效的原因是策略在不同域之间的gap,是被两域表征差异upper bound。
method
表征学习部
鉴于定理 4.2 的启示,表征应该嵌入更多的目标域信息,而不是强调源域知识,这样表征偏差才能更好地代表动态变化。
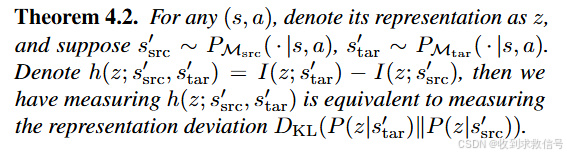
因此,只在目标领域训练状态编码器和状态-动作编码器,
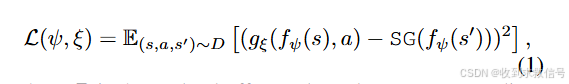
然后,源域的样本评估表征偏差。用计算出的偏差对源域重新进行惩罚,即将其奖励修改为:
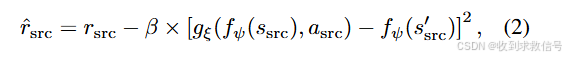
价值函数优化
采用SAC的方法对二域数据优化,注意源域要进行reward shaping
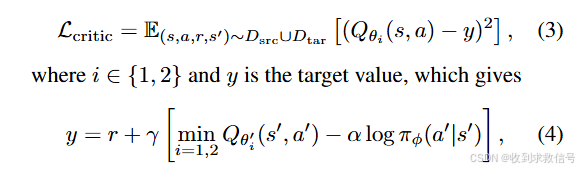
策略优化
在线策略优化
采用SAC中优化形式:
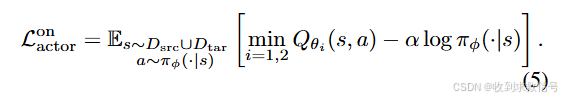
离线策略优化
根据理论4.5,gap的upper bound与策略差异有关

,因此采用类似TD3+BC中的BC正则:
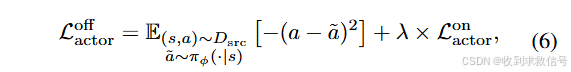
其中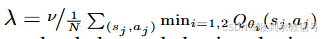
伪代码

结果
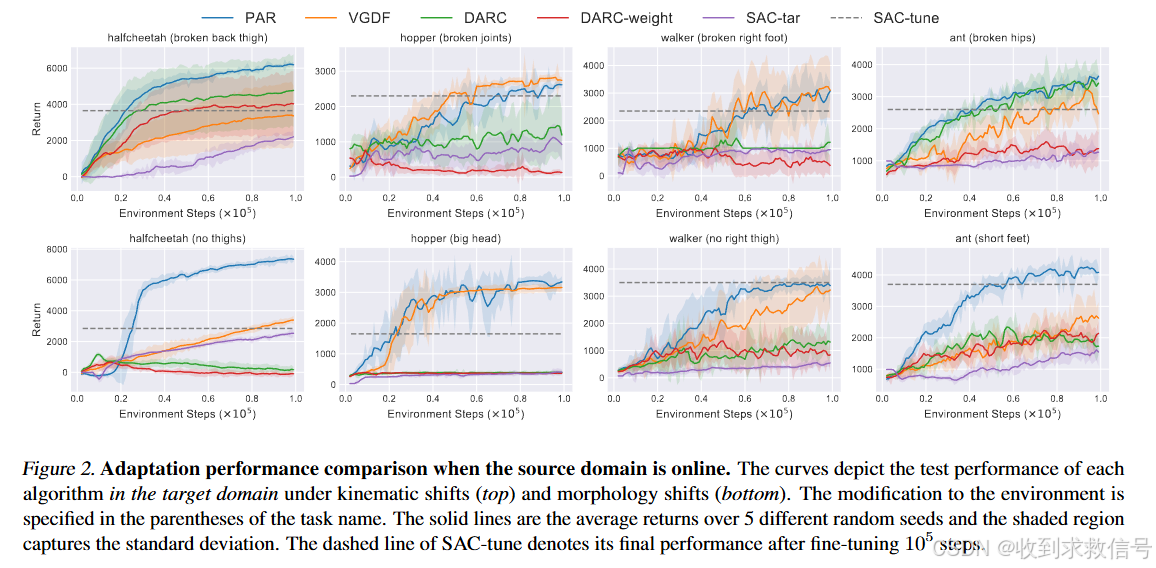
在线
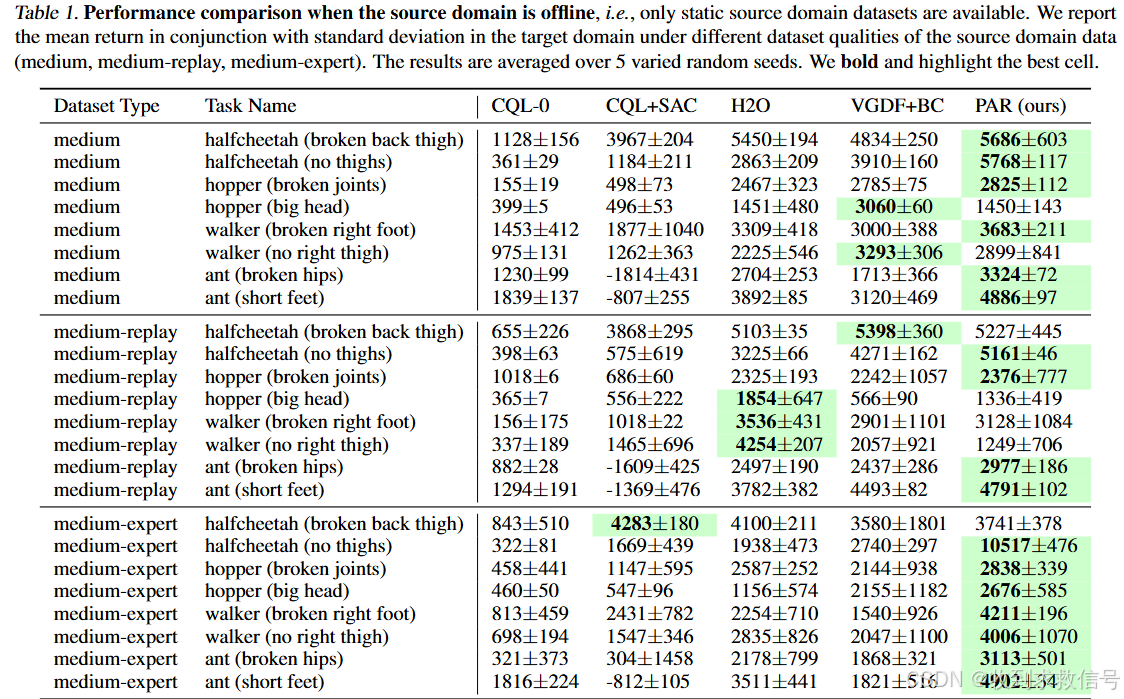
离线

















 1930
1930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









