







 本文全面解析深度学习中的优化算法,包括SGD、Momentum、Adagrad、Adadelta、RMSprop、Adam、Adamax及Nadam等,探讨它们的工作原理、特点与适用场景,以及如何有效提升模型训练效率。
本文全面解析深度学习中的优化算法,包括SGD、Momentum、Adagrad、Adadelta、RMSprop、Adam、Adamax及Nadam等,探讨它们的工作原理、特点与适用场景,以及如何有效提升模型训练效率。
优化方法总结
参考
深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
An overview of gradient descent optimization algorithms
文章目录
1. SGD
3种不同的梯度下降方法,区别在于每次参数更新时计算的样本数据量不同。
1.1 Batch gradient descent
每进行1次参数更新,需要计算整个数据样本集:
θ
=
θ
−
η
∇
θ
J
(
θ
)
\theta=\theta-\eta \nabla_\theta J(\theta)
θ=θ−η∇θJ(θ)
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad
1.2 Stochastic gradient descent
每进行1次参数更新,只需要计算1个数据样本:
θ = θ − η ∇ θ J ( x i , y i ; θ ) \theta=\theta-\eta \nabla_\theta J(x^i,y^i;\theta) θ=θ−η∇θJ(xi,yi;θ)
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function, example, params)
params = params - learning_rate * params_grad
1.3 Mini-batch gradient descent
每进行1次参数更新,需要计算1个mini-batch数据样本:
θ = θ − η ∇ θ J ( x i : i + n , y i : i + n ; θ ) \theta=\theta-\eta \nabla_\theta J(x^{i:i+n},y^{i:i+n};\theta) θ=θ−η∇θJ(xi:i+n,yi:i+n;θ)
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=50):
params_grad = evaluate_gradient(loss_function, batch, params)
params = params - learning_rate * params_grad
【三种gradient descent对比】
Batch gradient descent的收敛速度太慢,而且会大量多余的计算(比如计算相似的样本)。
Stochastic gradient descent虽然大大加速了收敛速度,但是它的梯度下降的波动非常大(high variance)。
Mini-batch gradient descent中和了2者的优缺点,所以SGD算法通常也默认是Mini-batch gradient descent。
【Mini-batch gradient descent的缺点】
然而Mini-batch gradient descent也不能保证很好地收敛。主要有以下缺点:
-
选择一个合适的learning rate是非常困难的
学习率太低会收敛缓慢,学习率过高会使收敛时的波动过大。
-
所有参数都是用同样的learning rate
对于稀疏数据或特征,有时我们希望对于不经常出现的特征的参数更新快一些,对于常出现的特征更新慢一些。这个时候SGD就不能满足要求了。
-
sgd容易收敛到局部最优解,并且在某些情况可能被困在鞍点
在合适的初始化和step size的情况下,鞍点的影响没那么大。
正是因为SGD这些缺点,才有后续提出的各种算法。
2. Momentum
momentum利用了物理学中动量的思想,通过积累之前的动量 ( m t − 1 ) (m_t−1) (mt−1)来加速当前的梯度。
m
t
=
μ
∗
m
t
−
1
+
η
∇
θ
J
(
θ
)
θ
t
=
θ
t
−
1
−
m
t
m_t=μ∗m_{t−1}+η∇_θJ(θ) \\ θ_t=θ_{t−1}−m_t
mt=μ∗mt−1+η∇θJ(θ)θt=θt−1−mt
其中,
μ
μ
μ是动量因子,通常被设置为0.9或近似值。
【特点】
- 参数下降初期,加上前一次参数更新值;如果前后2次下降方向一致,乘上较大的μμ能够很好的加速。
- 参数下降中后期,在局部最小值附近来回震荡时,gradient→0gradient→0,μμ使得更新幅度增大,跳出陷阱。
- 在梯度方向改变时,momentum能够降低参数更新速度,从而减少震荡;在梯度方向相同时,momentum可以加速参数更新, 从而加速收敛。
总而言之,momentum能够加速SGD收敛,抑制震荡。
3. Nesterov
Nesterov在梯度更新时做一个矫正,避免前进太快,同时提高灵敏度。
Momentum并没有直接影响当前的梯度 ∇ θ J ( θ ) ∇_θJ(θ) ∇θJ(θ),所以Nesterov的改进就是用上一次的动量 ( − μ ∗ m t − 1 ) (−μ∗m_{t−1}) (−μ∗mt−1)当前的梯度 ∇ θ J ( θ ) ∇_θJ(θ) ∇θJ(θ)做了一个矫正。
m t = μ ∗ m t − 1 + η ∇ θ J ( θ − μ ∗ m t − 1 ) θ t = θ t − 1 − m t m_t=μ∗m_{t−1}+η∇_θJ(θ−μ∗m_{t−1})\\θ_t=θ_t−1−m_t mt=μ∗mt−1+η∇θJ(θ−μ∗mt−1)θt=θt−1−mt
所以,加上nesterov项后,梯度在大的跳跃后,进行计算对当前梯度进行校正。如下图:
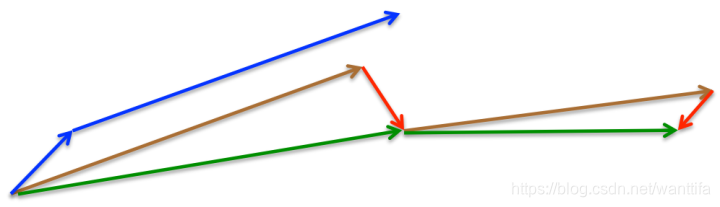
Momentum:蓝色向量
Momentum首先计算当前的梯度值(短的蓝色向量),然后加上之前累计的梯度/动量(长的蓝色向量)。
Nexterov:绿色向量
Nexterov首先先计算之前累计的梯度/动量(长的棕色向量),然后加上当前梯度值进行矫正后 ( − μ ∗ m t − 1 ) (−μ∗m_t−1) (−μ∗mt−1)的梯度值(红色向量),得到的就是最终Nexterov的更新值(绿色向量)。
Momentum和Nexterov都是为了使梯度更新更灵活。但是人工设计的学习率总是有些生硬,下面介绍几种自适应学习率的方法。
4. Adagrad
Adagrad是对学习率进行了一个约束。
g
t
=
∇
θ
J
(
θ
)
n
t
=
n
t
−
1
+
(
g
t
)
2
θ
t
=
θ
t
−
1
−
η
n
t
+
ϵ
∗
g
t
=
θ
t
−
1
−
η
∑
r
=
1
t
(
g
r
)
2
+
ϵ
∗
g
t
g_t=∇_θJ(θ)\\ n_t=n_{t−1}+(g_t)^2\\ θ_t=θ_{t−1}−\frac{η}{\sqrt {n_t+ϵ}}∗g_t=θ_{t−1}−\frac{η}{\sqrt{∑^t_{r=1}(g_r)^2+ϵ}}∗g_t
gt=∇θJ(θ)nt=nt−1+(gt)2θt=θt−1−nt+ϵη∗gt=θt−1−∑r=1t(gr)2+ϵη∗gt
这个
−
η
∑
r
=
1
t
(
g
r
)
2
+
ϵ
−\frac{η}{\sqrt{∑^t_{r=1}(g_r)^2+ϵ}}
−∑r=1t(gr)2+ϵη 是一个约束项regularizer,
η
η
η是一个全局学习率,
ϵ
ϵ
ϵ是一个常数,用来保证分母非 0。
【特点】
- 前期 n t n_t nt较小的时候,regularizer较大,能够放大梯度
- 后期 n t n_t nt较大的时候,regularizer较小,能够缩小梯度
- 中后期,分母上梯度平方的累加会越来越大,使 g r a d i e n t → 0 gradient→0 gradient→0,使得训练提前结束。
【缺点】
- 由公式可以看出,仍依赖于人工设置的一个全局学习率 η η η
- η η η 设置过大的话,会使regularizer过于敏感,对梯度调节太大。
- 最重要的是,中后期分母上的梯度平方累加会越来越大,使 g r a d i e n t → 0 gradient→0 gradient→0,使得训练提前结束,无法继续学习。
Adadelta主要就针对最后1个缺点做了改进。
5. Adadelta
Adadelta依然对学习率进行了约束,但是在计算上进行了简化。
Adagrad会累加之前所有梯度的平方,而Adadelata只需累加固定大小的项,并且也不直接存储这些项,仅仅是计算对应的近似平均值。
g
t
=
∇
θ
J
(
θ
)
n
t
=
υ
∗
n
t
−
1
+
(
1
−
υ
)
(
g
t
)
2
θ
t
=
θ
t
−
1
−
η
n
t
+
ϵ
∗
g
t
g_t=∇_θJ(θ)\\ n_t=υ∗n_{t−1}+(1−υ)(g_t)^2\\ θ_t=θ_t−1−\frac{η}{\sqrt{n_t+ϵ}}∗g_t
gt=∇θJ(θ)nt=υ∗nt−1+(1−υ)(gt)2θt=θt−1−nt+ϵη∗gt
在此处Adadelta还是依赖全局学习率的,然后作者又利用近似牛顿迭代法,做了一些改进:
E
[
g
2
]
t
=
ρ
∗
E
[
g
2
]
t
−
1
+
(
1
−
ρ
)
∗
(
g
t
)
2
Δ
θ
t
=
−
∑
r
=
1
t
−
1
Δ
θ
r
E
[
g
2
]
t
+
ϵ
E[g^2]_t=ρ∗E[g^2]_{t−1}+(1−ρ)∗(g_t)^2\\ Δθ_t=−\frac{∑^{t−1}_{r=1}Δθ_r}{\sqrt{E[g^2]_t+ϵ}}
E[g2]t=ρ∗E[g2]t−1+(1−ρ)∗(gt)2Δθt=−E[g2]t+ϵ∑r=1t−1Δθr
其中,E代表求期望。
此时可以看出Adadelta已经不依赖全局learning rate了。
【特点】
- 训练初中期,加速效果不错,很快。
- 训练后期,反复在局部最小值附近抖动。
6. RMSprop
RMSprop可以看做Adadelta的一个特例。
当 ρ = 0.5 ρ=0.5 ρ=0.5 时, E [ g 2 ] t = ρ ∗ E [ g 2 ] t − 1 + ( 1 − ρ ) ∗ ( g t ) 2 E[g^2]_t=ρ∗E[g^2]_{t−1}+(1−ρ)∗(g_t)^2 E[g2]t=ρ∗E[g2]t−1+(1−ρ)∗(gt)2就变为求梯度平方和的平均数。
如果再求根的话,就变成RMS(Root Mean Squared,均方根):
R
M
S
[
g
]
t
=
E
[
g
2
]
t
+
ϵ
RMS[g]_t=\sqrt{E[g^2]_t+ϵ}
RMS[g]t=E[g2]t+ϵ
此时,RMS就可以作为学习率
η
η
η的一个约束:
Δ
θ
t
=
−
η
R
M
S
[
g
]
t
∗
g
t
Δθ_t=−\frac{η}{\sqrt{RMS[g]_t}}∗g_t
Δθt=−RMS[g]tη∗gt
比较好的一套参数设置为:
η
=
0.001
,
γ
=
0.9
η=0.001,γ=0.9
η=0.001,γ=0.9
【特点】
- 其实RMSprop依然依赖于全局学习率
- RMSprop的效果介于Adagrad和Adadelta之间
- 适合处理非平稳目标——对于RNN效果很好。
7. Adam
Adam(Adaptive Moment Estimation)本质上时带有动量项的RMSprop。
m
t
=
μ
∗
m
t
−
1
+
(
1
−
μ
)
∗
g
t
n
t
=
v
∗
n
t
−
1
+
(
1
−
v
)
∗
(
g
t
)
2
m
^
t
=
m
t
1
−
μ
t
n
^
t
=
n
t
1
−
v
t
Δ
θ
t
=
−
m
^
t
n
^
t
+
ϵ
∗
η
m_t=μ∗m_{t−1}+(1−μ)∗g_t\\ n_t=v∗n_{t−1}+(1−v)∗(g_t)^2\\ \hat m_t=\frac{m_t}{1−μ^t}\\ \hat n_t=\frac{n_t}{1−v^t} \\ Δθ_t=−\frac{\hat m_t}{\sqrt{\hat n_t}+ϵ}∗η
mt=μ∗mt−1+(1−μ)∗gtnt=v∗nt−1+(1−v)∗(gt)2m^t=1−μtmtn^t=1−vtntΔθt=−n^t+ϵm^t∗η
m
t
,
n
t
m_t,n_t
mt,nt 分别是梯度的一阶矩估计和二阶矩估计,可以看作对期望
E
[
g
]
t
,
E
[
g
2
]
t
E[g]_t,E[g^2]_t
E[g]t,E[g2]t的估计;
m ^ t , n ^ t \hat m_t,\hat n_t m^t,n^t分别是对 m t , n t m_t,n_t mt,nt 的校正,这样可以近似为对期望的无偏估计。
可以看出,直接对梯度的矩估计对内存没有额外的要求,而且可以根据梯度进行动态调整,而 − m ^ t n ^ t + ϵ −\frac{\hat m_t}{\sqrt{\hat n_t}+ϵ} −n^t+ϵm^t 对学习率形成一个动态约束,而且有明确范围。
作者提出的默认的参数设置为:
μ
=
0.9
,
v
=
0.999
,
ϵ
=
10
−
8
μ=0.9,v=0.999,ϵ=10−8
μ=0.9,v=0.999,ϵ=10−8
【特点】
- Adam梯度经过偏置校正后,每一次迭代学习率都有一个固定范围,使得参数比较平稳。
- 结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
- 为不同的参数计算不同的自适应学习率
- 也适用于大多非凸优化问题——适用于大数据集和高维空间。
8. Adamax
Adamax是Adam的一种变体,此方法对学习率的上限提供了一个更简单的范围。
n
t
=
m
a
x
(
v
∗
n
t
−
1
,
∣
g
t
∣
)
Δ
θ
t
=
−
m
^
t
n
t
+
ϵ
∗
η
n_t=max(v∗n_{t−1},|g_t|)\\ Δθ_t=−\frac{\hat m_t}{n_t+ϵ}∗η
nt=max(v∗nt−1,∣gt∣)Δθt=−nt+ϵm^t∗η
Adamax的学习率边界范围更简单
9. Nadam
Nadam类似于带有Nexterov动量项的Adam。
g
^
t
=
g
t
1
−
∏
i
=
1
t
+
1
μ
i
m
t
=
μ
t
∗
m
t
−
1
+
(
1
−
μ
t
)
∗
g
t
m
^
t
=
m
t
1
−
∏
i
=
1
t
+
1
μ
i
n
t
=
v
∗
n
t
−
1
+
(
1
−
v
)
∗
(
g
t
)
2
n
^
t
=
n
t
1
−
v
t
m
^
t
=
(
1
−
μ
t
)
∗
g
^
t
+
μ
t
+
1
∗
m
^
t
Δ
θ
t
=
−
m
^
t
n
t
+
ϵ
∗
η
\hat g_t^=\frac{g_t}{1−∏^{t+1}_{i=1}μ_i}\\ m_t=μ_t∗m_{t−1}+(1−μ_t)∗g_t\\ \hat m_t=\frac{m_t}{1−∏^{t+1}_{i=1}μ_i}\\ n_t=v∗n_{t−1}+(1−v)∗(g_t)^2\\ \hat n_t=\frac{n_t}{1−v^t}\hat m_t=(1−μ_t)∗\hat g_t+μ_{t+1}∗\hat m_t\\ Δθ_t=−\frac{\hat m_t}{\sqrt{n_t}+ϵ}∗η
g^t=1−∏i=1t+1μigtmt=μt∗mt−1+(1−μt)∗gtm^t=1−∏i=1t+1μimtnt=v∗nt−1+(1−v)∗(gt)2n^t=1−vtntm^t=(1−μt)∗g^t+μt+1∗m^tΔθt=−nt+ϵm^t∗η
可以看出,Nadam对学习率有更强的约束,同时对梯度的更新也有更直接的影响。
一般而言,在使用带动量的RMSprop或Adam的问题上,使用Nadam可以取得更好的结果。
经验之谈
几种算法下降过程的可视化
算法的梯度下降过程对比:
可以看到:
Adagrad,Adadelta和RMSprop都是非常快到达右边的最优解,而这个时候Momentum和NAG才开始下降,而且刚开始的下降速度很慢。但是很快NAG就会找到正确的下降方向并且更加速的接近最优解。
SGD下降的最慢了,但是下降的方向总是最正确的。
在鞍点(saddle point)处的对比:

可以看到:
SGD被困在鞍点了,没法继续优化。
SGD,Momentum和NAG都在鞍点来回晃动,但最终Momentum和NAG逃离了鞍点。
但是与此同时,Adagrad,RMSprop和Adadelta很快的就离开了鞍点。
优化算法的选择
- 对于稀疏数据,尽量使用学习率可自适应的算法,不用手动调节,而且最好采用默认参数
- SGD通常训练时间最长,但是在好的初始化和学习率调度方案下,结果往往更可靠。但SGD容易困在鞍点,这个缺点也不能忽略。
- 如果在意收敛的速度,并且需要训练比较深比较复杂的网络时,推荐使用学习率自适应的优化方法。
- Adagrad,Adadelta和RMSprop是比较相近的算法,表现都差不多。
- 在能使用带动量的RMSprop或者Adam的地方,使用Nadam往往能取得更好的效果。
【学习率自适应的优化算法】:
Adagrad, Adadelta, RMSprop, Adam, Adamax, Nadam
优化SGD的其他策略
Shuffling and Curriculum Learning
Shuffling就是打乱数据,每一次epoch之后 shuffle一次数据,可以避免训练样本的先后次序影响优化的结果。
但另一方面,在有些问题上,给训练数据一个有意义的顺序,可能会得到更好的性能和更好的收敛。这种给训练数据建立有意义的顺序的方法被叫做Curriculum Learning。
Batch Normalization
为了有效的学习参数,我们一般在一开始把参数初始化成0均值和单位方差。但是在训练过程中,参数会被更新到不同的数值范围,使得normalization的效果消失,从而导致训练速度变慢或梯度爆炸等等问题(当网络越来越深的时候)。
BN给每个batch的数据恢复了normalization,同时这些对数据的更改都是可还原的,即normalization了中间层的参数,又没有丢失中间层的表达能力。
使用BN之后,我们就可以使用更高的学习率,也不用再在参数初始化上花费那么多注意力。
BN还有正则化的作用,同时也削弱了对Dropout的需求。
Early Stopping
在训练的时候我们会监控validation的误差,并且会(要有耐心)提前停止训练,如果验证集的error没有很大的改进。
Gradient noise
在梯度更新的时候加一个高斯噪声:
g
t
,
i
=
g
t
,
i
+
N
(
0
,
σ
t
2
)
g_{t,i}=g_{t,i}+N(0,σ^2_t)
gt,i=gt,i+N(0,σt2)
方差值的初始化策略是:
σ
t
2
=
η
(
1
+
t
)
γ
σ^2_t=\frac{η}{(1+t)^γ}
σt2=(1+t)γη
Neelakantan等人表明,噪声使得网络的鲁棒性更好,而且对于深度复杂的网络训练很有帮助。
他们猜想添加了噪声之后,会使得模型有更多机会逃离局部最优解(深度模型经常容易陷入局部最优解)
作者:sherine
来源:优快云
原文:https://blog.youkuaiyun.com/muyu709287760/article/details/62531509
版权声明:本文为博主原创文章,转载请附上博文链接!

















 175
175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









