




目录
为什么要对大模型进行微调
2018年BERT问世后,NLP任务的主流范式已经变为预训练语言模型+微调。从大多数模型的自我对比来说,尺寸越大,效果越好。预训练语言模型的趋势为:大 → 更大 → 再大。BERT-Base只有0.1B,而现在意义上的大模型,起步就要6、7B,更大的模型带来了更好的性能,但是也带来了一些问题。
1.以传统微调的方式对模型进行全量参数更新会消耗巨大的计算与存储资源。
2.个人层面,很难拥有充足的资源进行训练
参数高效微调
在上述的情况下,参数高效微调(Parameter-efficient fine-tuning,PEFT)应运而生。
参数高效微调方法仅对模型的一小部分参数(这一小部分可能是模型自身的,也可能是外部引入的)进行训,便可以为模型带来显著的性能变化,一些场景下甚至不输于全量微调,颇有一种四两拨千斤的感觉。
由于训练一小部分参数,极大程度降低了训练大模型的算力需求,不需要多机多卡,单卡即可完成对一些大模型的训练,不仅如此,少量的训练参数对存储的要求同样降低了很多,大多数的参数高效微调方法只需要保存训练部分的参数,与动辄几十GB的原始大模型相比,几乎可以忽略。
参见的高效微调方法
高效微调技术可以粗略分为以下三大类:增加额外参数(A)、选取一部分参数更新(S)、引入重参数化(R)。而在增加额外参数这类方法中,又主要分为类适配器(Adapter-like)方法和软提示(Soft prompts)两个小类。
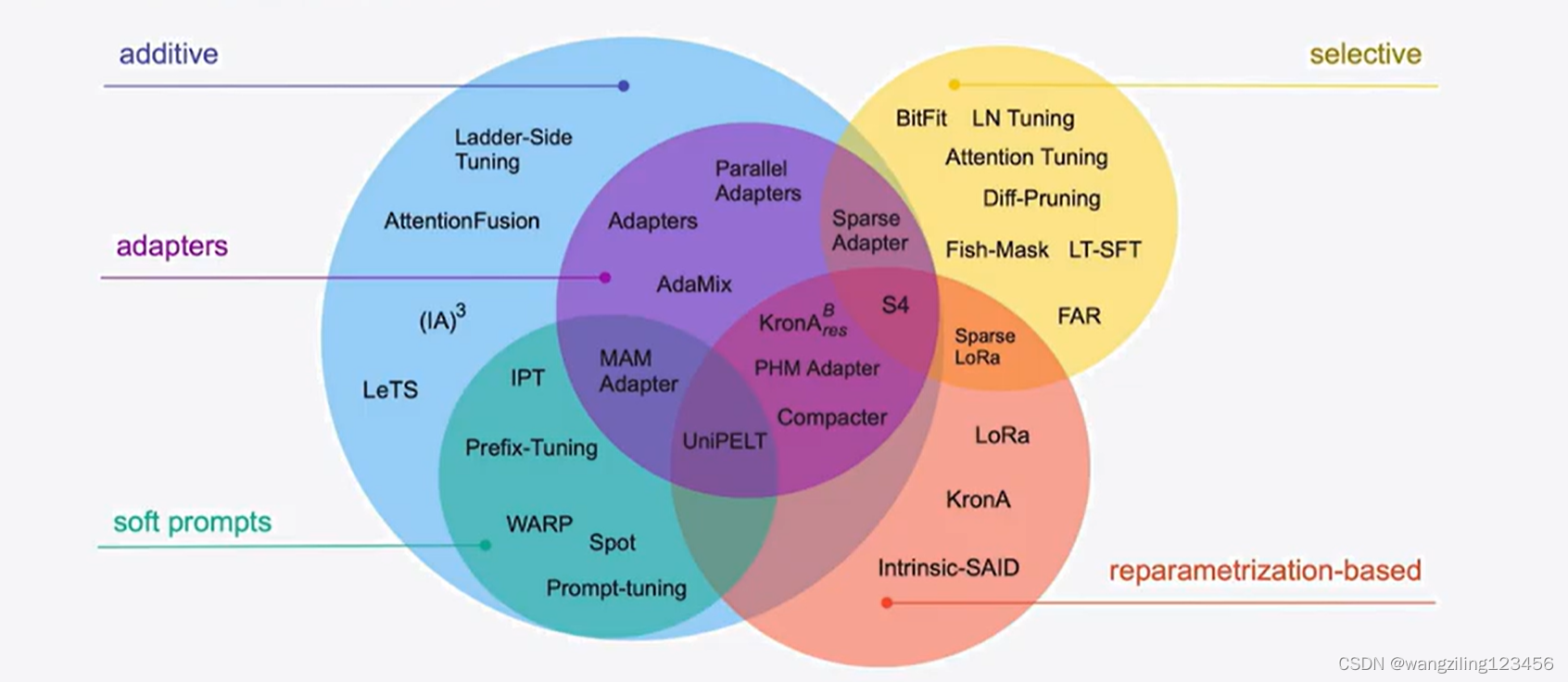
PEFT是什么
PEFT(Parameter-Efficient Fine-Tuning)是hugging face开源的一个参数高效微调大模型的工具,里面集成了4种微调大模型的方法,可以通过微调少量参数就达到接近微调全量参数的效果,使得在GPU资源不足的情况下也可以微调大模型。
常见的高效微调方法
1.BitFit
BitFit是一种稀疏的微调方法,它训练时只更新bias的参数或者部分bias参数。
对于Transformer模型而言,冻结大部分 transformer-encode
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









