




 本文详细介绍了常见的代价函数(如二次代价函数和交叉熵),以及损失函数(针对回归和分类的绝对值、平方、对数和交叉熵等)。强调了不同函数在梯度、收敛速度和鲁棒性方面的特性,并解释了为何在回归和分类问题中选择特定损失函数的原因。
本文详细介绍了常见的代价函数(如二次代价函数和交叉熵),以及损失函数(针对回归和分类的绝对值、平方、对数和交叉熵等)。强调了不同函数在梯度、收敛速度和鲁棒性方面的特性,并解释了为何在回归和分类问题中选择特定损失函数的原因。
一、常见的代价函数
1、二次代价函数
J=1/2nΣ||a(x)-y(x)||^2
对于一个样本而言,J=(y-a)/2

激活函数的梯度越大,权值w和b大小调整的越快,训练收敛的越快
假使激活函数是sigmoid函数,当使用二次代价函数时,很可能会出现梯度消失,使用sigmoid函数在饱和区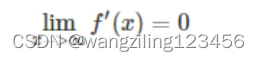 即x过大或者过小时,梯度是接近于0
即x过大或者过小时,梯度是接近于0
2.交叉熵代价函数
J=-1/nΣ[yln(a)+(1-y)ln(1-a)]
更适合搭配sigmoid激活函数
二、常见的损失函数
1.用于回归
绝对值损失函数和平方损失函数
绝对值损失函数MAE

平方损失函数MSE
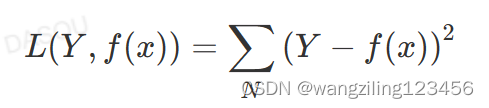
MSE比MAE可以更快的收敛,当使用梯度下降算法时,MSE梯度下降是变化的,MAE梯度损失是均匀不变的,梯度不发生改变不利于模型的训练(调节学习率)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







