




 本文介绍了优化函数在机器学习中的作用,重点讲解了批量、随机和小批量梯度下降方法,以及动态优化策略如momentum、nesterovNAG、adagrad、RMSProp、Adam、NAdam和AdamW等,讨论了它们的优缺点和适用场景。
本文介绍了优化函数在机器学习中的作用,重点讲解了批量、随机和小批量梯度下降方法,以及动态优化策略如momentum、nesterovNAG、adagrad、RMSProp、Adam、NAdam和AdamW等,讨论了它们的优缺点和适用场景。
优化函数的作用
优化函数是用来最小化损失函数的
损失函数是衡量模型输出与真实值的偏差,这个差值越小,模型训练效果越好
如果损失是一个凸函数,求最小值比较简单,直接求导就好:但是复杂的神经网络一般都不是凸函数,优化函数就是在这种情况下最小化损失函数的
梯度下降
1.批量梯度下降
使用全部数据计算梯度,进而更新参数
因为要遍历整个数据集在更新参数,所以更新参数速度慢。
缺点:不适合大数据集,不能实时更新参数
优点:训练稳定
2.随机梯度下降
每计算一个样本,更新一次参数
因为频繁更新参数,参数方差大,会使目标函数剧烈抖动,一方面能更快的是目标函数跳到局部极小值,一方面会使目标函数在最小值附近上下波动
3。小批量梯度下降
计算一个batch内的样本,更新参数,这个方法参数更新快,方差小,使用内存小,n通常取2的指数
动态优化
1.momentum
引入一阶动量,momentum是各个时刻梯度的指数移动平均值
momentum将过去的时间梯度添加到当前的时间梯度,是一种有助于抑制SGD振荡并加速SGD向最小值收敛的方法。

简单理解是
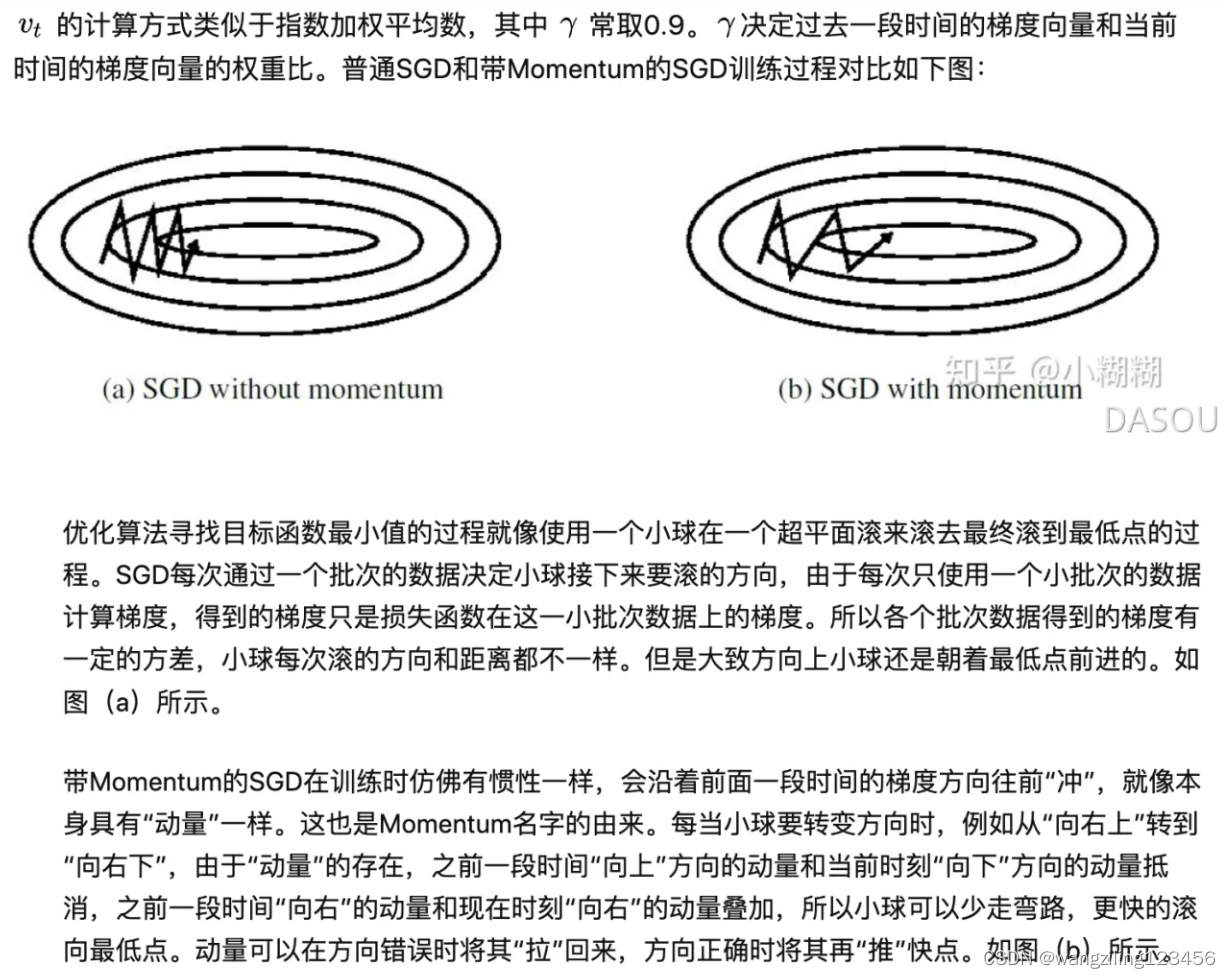
2.nesterovNAG
现根据当前的动量往前走一步,然后到达下一个点,计算此时的梯度更新
取决于此时的动量和下一个时刻的梯度
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







