




 文章介绍了一种新的方法SpanProto,针对Few-shotner问题,通过span-based的两阶段学习,关注实体边界信息,并使用边际损失减少假阳性的错误。研究者提出原型学习和基于边界的分类策略,以提高在少量标注数据下的实体识别性能。
文章介绍了一种新的方法SpanProto,针对Few-shotner问题,通过span-based的两阶段学习,关注实体边界信息,并使用边际损失减少假阳性的错误。研究者提出原型学习和基于边界的分类策略,以提高在少量标注数据下的实体识别性能。
原文链接:
https://aclanthology.org/2022.emnlp-main.227.pdf
EMNLP 2022
介绍
问题
Few-shot ner之前的方法都是基于对token进行分类,忽略了实体边界的信息,同时大量的负样本(non-entity)也会影响模型的性能。
IDEA
作者提出了一个span-based的two-stage原型网络(SpanProto)来解决Few-shot ner问题;在span提取阶段,将序列tag转化为一个全局的边界矩阵,使得模型能够注意到准确的边界信息。在分类阶段,对每个实体类别计算原型(prototype)embedding,并利用原型学习在语义空间中调整span的表征。另外,为了解决false positive问题,作者设计了一种margin-based损失,来增大false positive和所有原型之间的语义距离。
方法
模型的整体结构如下所示:
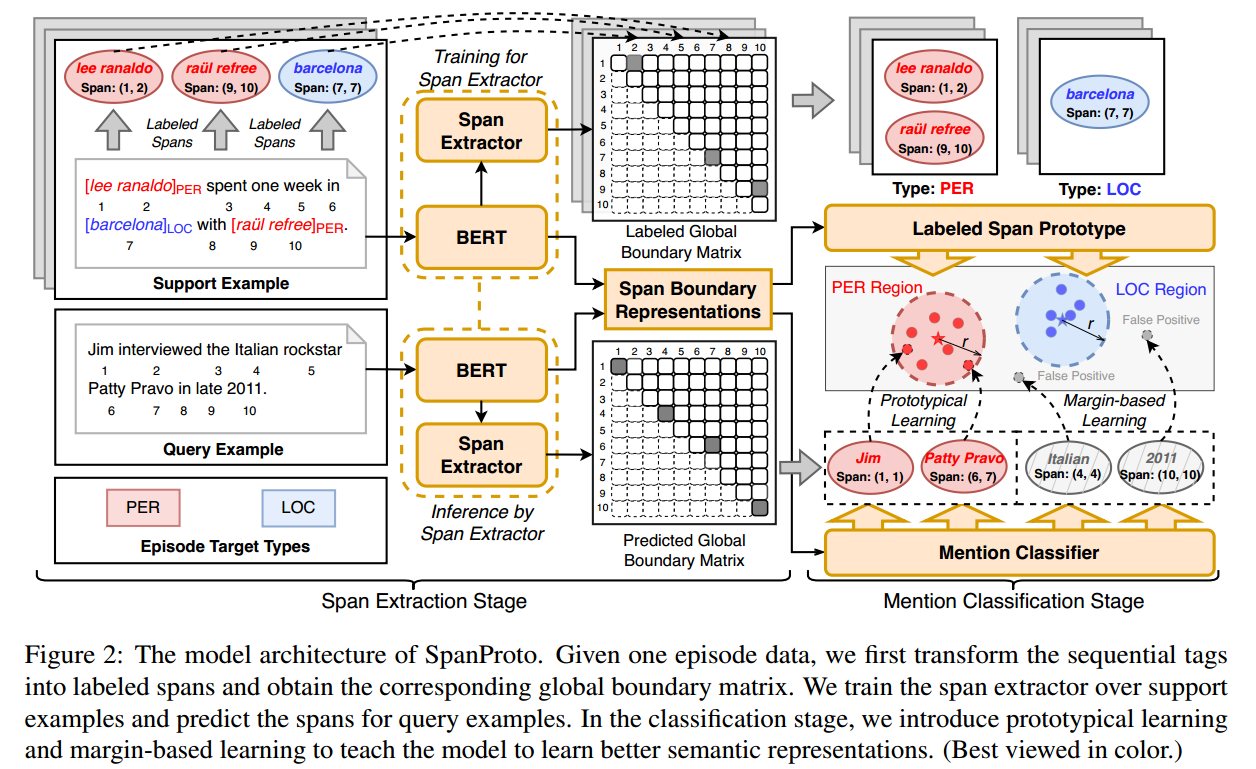
一个训练步的数据,分别表示support set、query set和实体类型集合。对于每个样本
,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









