




 文章介绍了Transformer模型如何通过在输入嵌入中添加位置编码来处理序列中的单词顺序,展示了不同编码方式(如Tensor2Tensor实现的交织方法),强调了这种技术对于处理变长序列的重要性。
文章介绍了Transformer模型如何通过在输入嵌入中添加位置编码来处理序列中的单词顺序,展示了不同编码方式(如Tensor2Tensor实现的交织方法),强调了这种技术对于处理变长序列的重要性。
Representing The Order of The Sequence Using Positional Encoding
正如我们到目前为止所描述的那样,模型中缺少的一件事是解释输入序列中单词顺序的方法。
为了解决这个问题,transformer 在每个输入嵌入中添加一个矢量。这些向量遵循模型学习的特定模式,这有助于它确定每个单词的位置,或序列中不同单词之间的距离。这里的直觉是,将这些值添加到嵌入中,一旦它们投射到Q/K/V矢量中,并在点积 attention 期间,嵌入向量之间会提供有意义的距离。

如果我们假设嵌入的维数为4,那么实际的位置编码将是这样的

这个模式会是什么样子呢?
在下面的图中,每一行对应一个向量的位置编码。所以第一行就是我们对输入序列中第一个单词的嵌入加上的向量。每行包含512个值,每个值在1到-1之间。我们对它们进行了颜色编码,这样图案就可以看到了。
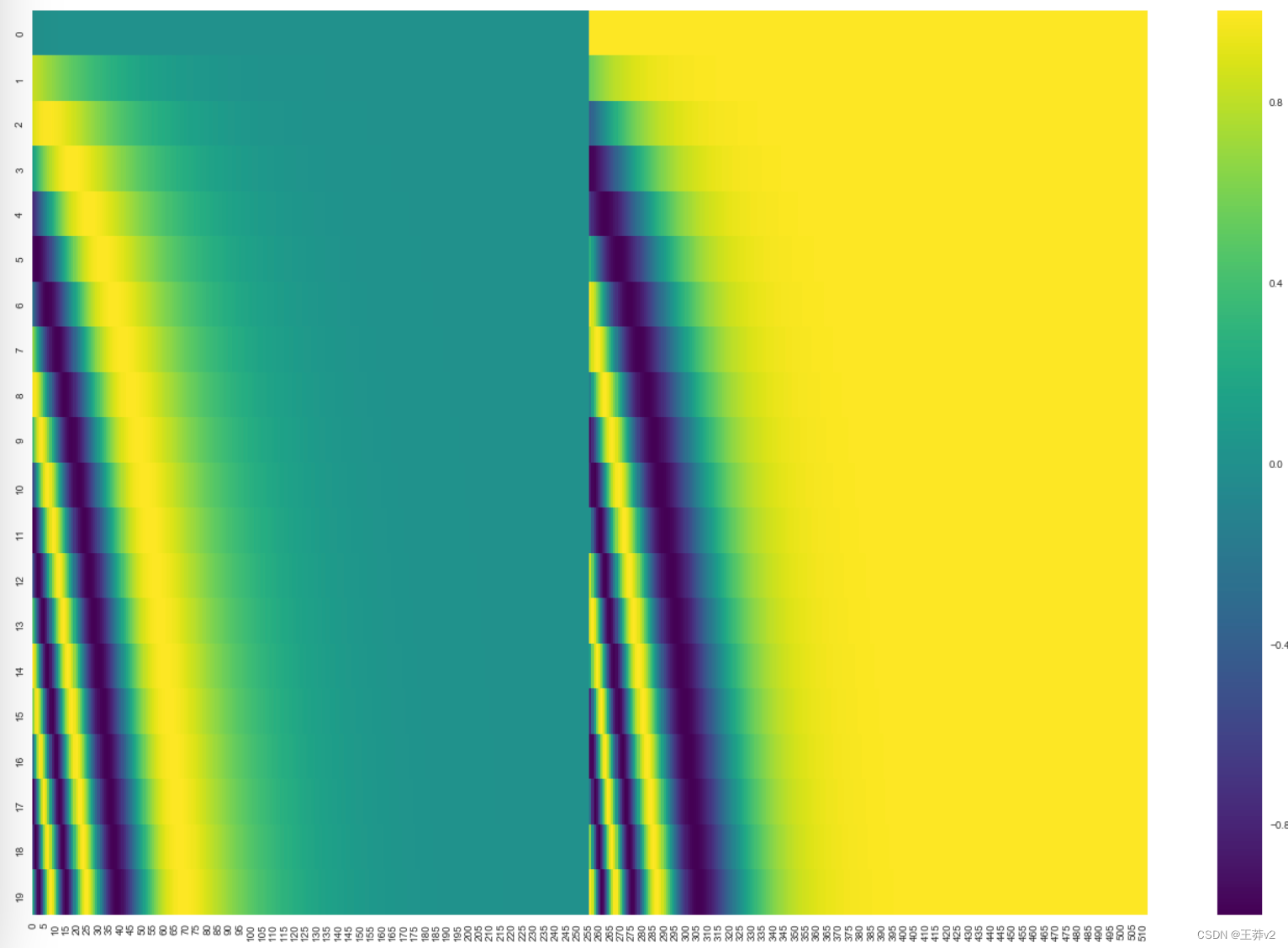
本文描述了位置编码的公式(第3.5节)。您可以在 get_timing_signa
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2727
2727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









