








 超级会员免费看
超级会员免费看


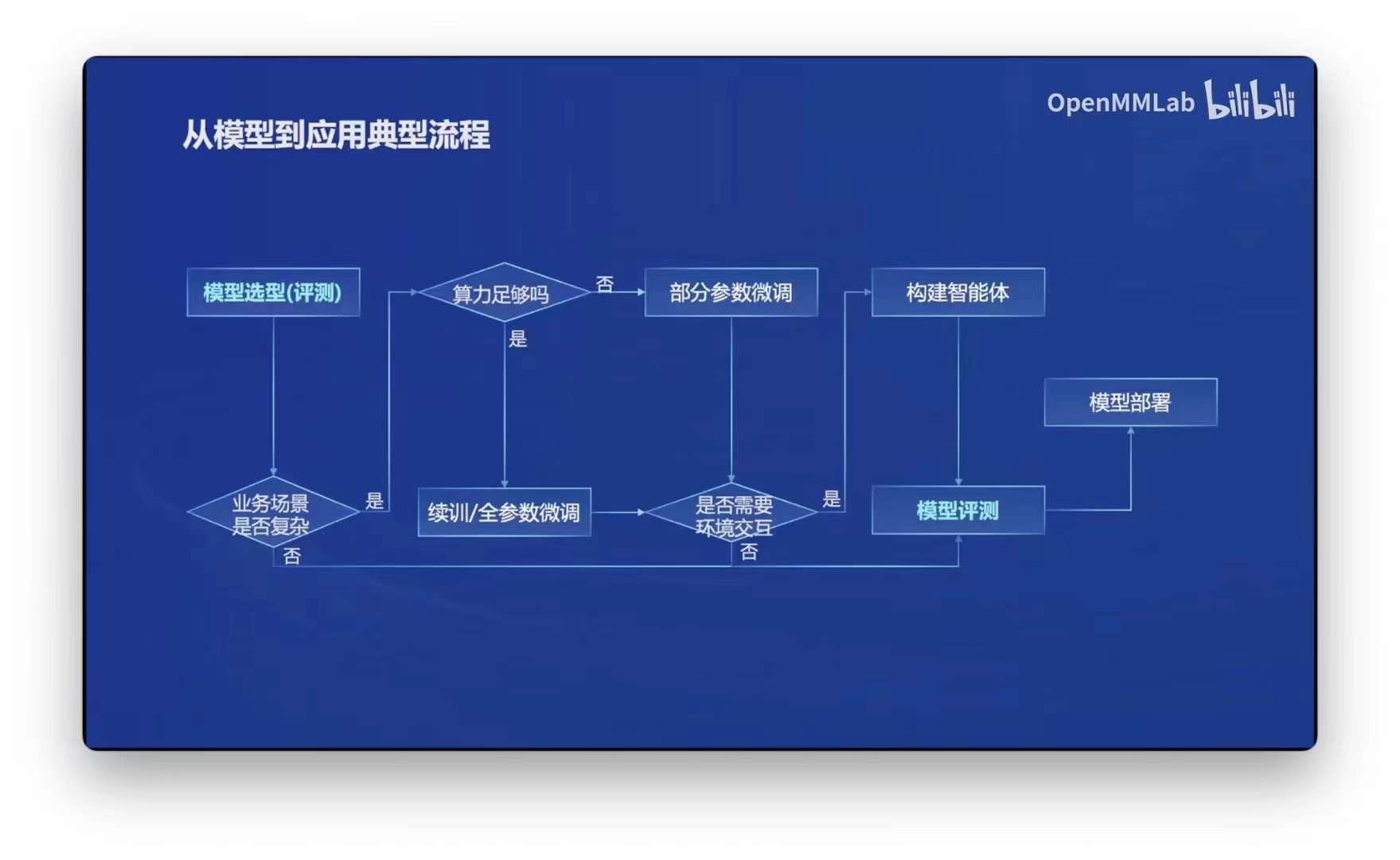
文章大纲
写这篇文章之前,我突然想起来21年我还写了这个类似RAG的专利卖给了一个创业公司:
一种基于结构信息检索文档的思路(html,pdf,html,xml,doc,ppt,这样的异构文档应该如何检索呢?)
RAG (Retrive,Augment,Generate)检索增强生成方案
简介
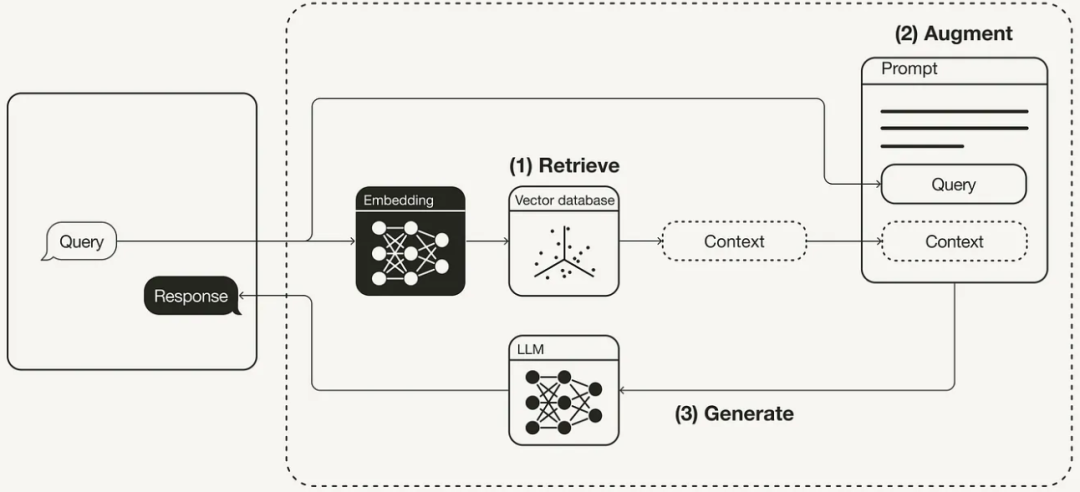
RAG 代表以下三个关键步骤
-
「检索(Retrive)」 根据用户请求从外部知识源检索相关上下文。为此,使用嵌入模型将用户查询嵌入到与向量数据库中的附加上下文相同的向量空间中。这允许执行相似性搜索,并返回矢量数据库中最接近的前 k 个数据对象。
-
「增强(Augment)」 用户查询和检索到的附加上下文被填充到提示模板中。
-
「生成(Generate)」 最后,检索增强提

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 5468
5468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











