



摘要
尽管Transformer架构已经成为自然语言处理任务的事实标准(de-facto standard),但其在计算机视觉领域的应用仍然有限。在视觉任务中,注意力机制(attention)通常与卷积网络(CNN)结合使用,或者仅用来替换卷积网络中的某些组件,同时保留CNN的整体结构。我们证明了,这种对CNN的依赖并非必要,直接将纯粹的Transformer应用于图像块(patch)序列,也能在图像分类任务中表现出色。
当在大规模数据上进行预训练,并迁移到多个中型或小型图像识别基准(如ImageNet、CIFAR-100、VTAB等)时,Vision Transformer(ViT) 在性能上与最先进的卷积网络相比表现优异,同时训练所需的计算资源显著减少。
1 INTRODUCTION
背景:Transformer在NLP中的成功
基于自注意力机制的架构,特别是Transformer(Vaswani等人,2017年提出),已经成为自然语言处理(NLP)领域的首选模型。主流方法是在大型文本语料库上进行预训练,然后在较小的任务特定数据集上进行微调(Devlin等人,2019年)。
得益于Transformer的计算效率和可扩展性,训练规模空前的模型成为可能,例如拥有超过1000亿参数的模型(Brown等人,2020年;Lepikhin等人,2020年)。随着模型规模和数据集的增长,模型性能尚未出现饱和的迹象。
在计算机视觉中的现状
在计算机视觉领域,卷积架构(CNN)仍然占据主导地位(LeCun等人,1989年;Krizhevsky等人,2012年;He等人,2016年)。
受NLP领域成功的启发,许多研究尝试将CNN与自注意力结合(Wang等人,2018年;Carion等人,2020年),甚至完全用自注意力替代卷积(Ramachandran等人,2019年;Wang等人,2020年a)。然而,这些模型在现代硬件加速器上由于使用了特殊的注意力模式,尚未被有效扩展。因此,在大规模图像识别任务中,经典的ResNet等架构(Mahajan等人,2018年;Xie等人,2020年;Kolesnikov等人,2020年)仍然是主流的最先进方法。
研究目标与方法
受Transformer在NLP中扩展成功的启发,我们尝试将一个标准的Transformer直接应用于图像任务,尽可能少地修改模型结构。
具体方法是,将图像分割成小块(patches),然后将这些图像块的线性嵌入序列作为输入提供给Transformer。
在这种设置下,图像块被视为与NLP任务中的“单词”(tokens)相同。我们以监督学习的方式对模型进行训练,用于图像分类。
初步实验结果
在中等规模的数据集(如ImageNet)上,使用不强正则化的情况下训练,这些模型的准确率比同等规模的ResNet低几个百分点。这种看似令人失望的结果是可以预期的,因为Transformer缺乏一些CNN固有的归纳偏置(如平移等变性和局部性),因此当训练数据不足时,泛化性能较差。
大规模数据的影响
然而,当模型在更大规模的数据集(1400万至3亿张图像)上训练时,情况发生了变化。我们发现大规模训练可以弥补归纳偏置的不足。
经过足够规模的预训练后,ViT在数据较少的任务上迁移时表现出色。当在公共ImageNet-21k数据集或内部JFT-300M数据集上预训练时,ViT在多个图像识别基准上达到了或超过了当前的最先进水平。
具体结果:
- ImageNet:88.55% 准确率
- ImageNet-ReaL:90.72%
- CIFAR-100:94.55%
- VTAB(19个任务):77.63%
2 RELATED WORK
Transformer在NLP与视觉中的差异
Transformer在NLP中的成功主要依赖于文本的离散性和序列性。然而,在图像处理中,直接应用自注意力会导致计算成本过高,因为图像像素数量远远多于语言中的单词或字符。
自注意力的优化方法
研究者通过引入局部注意力、稀疏注意力和块状注意力等近似方法,减少全局计算量。这些方法虽然有效,但实现复杂度较高,且对硬件加速器的适配存在困难。
ViT的创新点
- ViT在方法上相比Cordonnier等人的研究更简单,直接使用较大的图像块(而非2×2像素块)并应用全局自注意力。
- ViT通过大规模数据预训练,实现了在多个基准数据集上的竞争力甚至超越CNN的表现。
与iGPT的对比
iGPT在降分辨率和色彩空间缩减后的图像上进行无监督训练,而ViT直接处理原始分辨率的图像块,并采用有监督的分类任务。这使得ViT在高分辨率图像分类任务中具有更好的适用性和性能。
大规模数据的重要性
ViT的成功依赖于大规模预训练数据(如ImageNet-21k和JFT-300M)。大数据集不仅能够弥补Transformer缺乏归纳偏置的缺陷,还能够在迁移学习中展现强大的泛化能力。
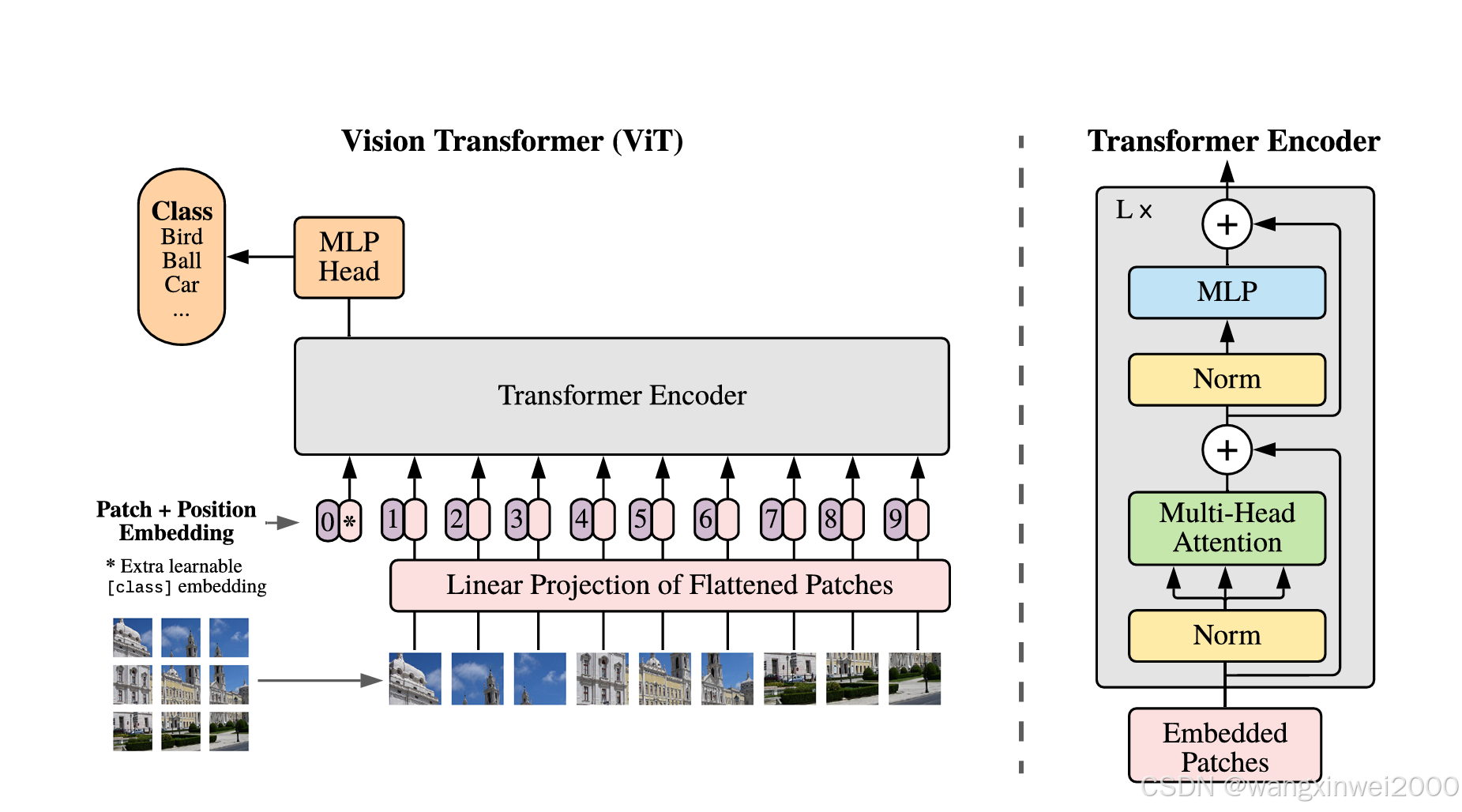
图1:模型概览
我们将图像分割为固定大小的图像块,对每个图像块进行线性嵌入,添加位置嵌入(position embeddings),然后将生成的向量序列输入到标准的Transformer编码器中。
为了进行分类,我们采用标准方法,在序列中添加一个可学习的“分类标记”(classification token)。
Transformer编码器的示意图受Vaswani等人(2017年)的启发。
3 METHOD
在模型设计上,我们尽可能紧密地遵循原始Transformer(Vaswani等人,2017年)的设计。
这种有意保持简单的设置有一个优势:可以几乎直接使用现有的可扩展NLP Transformer架构及其高效的实现方式。
3.1 VISION TRANSFORMER (VIT)


















 3544
3544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









