




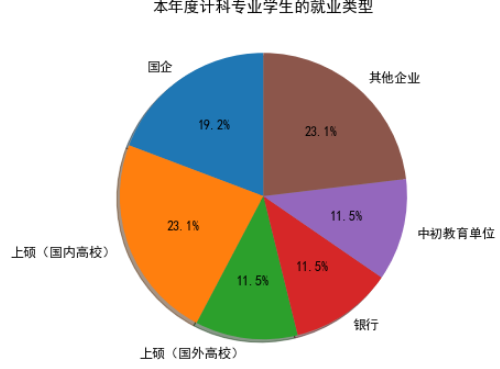
3、读取文件“jiuye.xlsx”中本年度某高校计科专业学生的就业数据,绘制就业类型和占比的饼状图,运行结果如下图所示。
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['font.size']=12
data=pd.read_excel("C:\\Users\\Administrator\\Desktop\\jiuye.xlsx")
plt.figure(figsize=(6, 6))
plt.title("本年度计科专业学生的就业类型")
plt.pie(data["所占比例"],labels=data["就业类型"],startangle=90,shadow=True,autopct='%.1f%%')
plt.show()
4、绘制如下不规则子图。
第一个子图为折线图,x为np.arange(1,100),y为x的平方值。
第二个图为散点图,x为np.arange(0,10),ynp.random.rand(10)。
第三个图为条形图,x和y的值分别是[20,10,30,25,15]和[25,15,35,30,20],
运行结果如图所示。提示:第一行的2个图占了221和222的位置,如果想在下面只放一个图,需把第3个子图所在的行两列当成一列,即2行1列第2个位置。
import numpy as np
plt.figure(figsize=(10, 7))
plt.subplot2grid((2,2),(0,0))
x=np.arange(1,100)
plt.plot(x,x**2)
plt.subplot2grid((2,2),(0,1))
x=np.arange(0,10)
y=np.random.rand(10)
plt.scatter(x,y)
plt.subplot2grid(( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1015
1015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









