







【注意力机制学习-01】-什么是语言模型中的注意力?
语言模型的一个重大障碍是当一个单词可以用于两种不同的上下文时。当遇到这个问题时,模型需要利用句子的上下文来判断该单词应采用哪种含义。而这正是自注意力(self-attention)模型所做的事情。
在前几章中,你学习了词和句子的嵌入(embedding)链接,以及它们之间的相似性链接。简而言之,词嵌入(word embedding) 是一种将单词与数字列表(向量)关联的方式,使得相似的单词对应的向量在空间上更接近,而不相似的单词对应的向量距离较远。句子嵌入(sentence embedding) 的原理类似,但它是为每个句子分配一个向量。相似性(similarity) 是一种衡量两个单词(或句子)相似程度的方法,相似的单词(或句子)会被赋予较大的数值,而不同的则对应较小的数值。
然而,词嵌入(word embeddings) 存在一个巨大的弱点:多义词。如果一个词嵌入模型为“bank”(银行/河岸)这样的单词分配了一个向量,那么无论“bank”是指金融机构还是河岸,它都会使用相同的向量。那么,如果你想在不同的上下文中使用这个单词,该怎么办呢?
这正是注意力机制(attention) 发挥作用的地方。自注意力(self-attention) 最早在开创性论文 Attention Is All You Need 中被提出,该论文的多位作者之一正是 Cohere 的联合创始人 Aidan Gomez。注意力机制是一种非常巧妙的方法,能够根据上下文区分单词的不同含义,从而将普通的词嵌入转换为“上下文相关的词嵌入”(contextualized word embeddings)。
同一个单词,不同的含义
为了理解注意力机制(attention),让我们来看以下两个句子:
- 句子 1:The bank of the river.(河岸)
- 句子 2:Money in the bank.(银行)
在这两个句子中,“bank” 这个单词有两种不同的含义:
- 在 句子 1 中,它指的是 河岸。
- 在 句子 2 中,它指的是 金融机构(银行)。
传统的词嵌入(word embeddings)会为 “bank” 分配相同的向量,无法区分它在不同上下文中的意义。而自注意力(self-attention) 机制能够理解句子结构,区分 “bank” 在不同场景下的含义,从而生成上下文相关的词嵌入(contextualized word embeddings)。
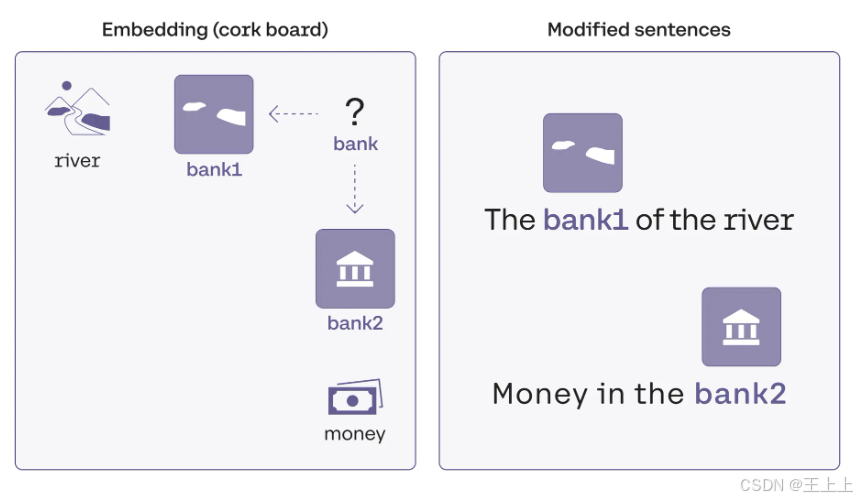
计算机如何知道第一个句子中的“bank”指的是自然环境,而第二个句子中的“bank”指的是金融环境呢?
其实,我们可以先问一个更简单的问题:人类是如何判断的?
你之所以能区分这两个不同的意思,可能是通过观察“bank”周围的单词。
- 在 第一个句子 中,“river” 暗示了“bank”指的是河岸(自然环境)。
- 在 第二个句子 中,“money” 让我们知道“bank”指的是银行(金融环境)。
总结:我们需要一种方法,让计算机能够利用句子中的其他单词来理解“bank”在不同语境下的含义。这正是注意力机制(attention) 的核心思想——它可以让模型关注句子中最相关的单词,以正确地理解单词的上下文。
这正是词嵌入(word embeddings) 发挥作用的地方。正如你在前面的章节中学到的,词嵌入是一种为每个单词分配向量(即一组数字)的方式。我喜欢从几何角度来想象这个过程。
想象一下,“bank”、“river” 和 “money” 都被钉在一块软木板上。而且,这块软木板包含了所有的单词,并且相似的单词(如“apple”和“pear”)会彼此靠近。
在这个“词的空间”中,“bank” 和 “river” 以及 “bank” 和 “money” 并不完全靠近。但我们可以做一个调整:
- 把“bank”向“river”移动一些,称之为 “bank₁”。
- 再把“bank”向“money”移动一些,称之为 “bank₂”。
现在,我们有了两个稍微不同的“bank”,并可以用它们来重写句子:
- 修改后的句子 1:The bank₁ of the river.
- 修改后的句子 2:Money in the bank₂.
通过这种方式,我们为同一个单词在不同语境下创建了不同的嵌入,从而让模型能够更好地理解“bank”在不同上下文中的具体含义。这就是上下文相关词嵌入(contextualized word embeddings) 的概念,而自注意力(self-attention) 机制正是用于实现这一点的关键方法!
在这两个修改后的句子中,计算机现在对**“bank”**的上下文有了更多的理解,因为这个单词已经被拆分成了两个不同的版本:
- bank₁(更接近“river”的定义)
- bank₂(更接近“money”的定义)
这就是注意力机制(attention mechanisms) 的基本思想。然而,你可能还有许多疑问,例如:
1️⃣ “移动一个单词靠近另一个单词”是什么意思?
- 这指的是调整词嵌入的向量,让它在语义空间中更靠近与其相关的单词。
2️⃣ 为什么忽略了句子中的其他单词?
- 我们如何知道是“river”和“money”决定了“bank”的含义,而不是“the”、“in”或“of”?
- 人类可以自然地区分哪些词是重要的,但计算机一开始并不知道。
3️⃣ 计算机只能处理数字,如何用数字表达这些方法?
- 词嵌入如何转换成数值?
- 注意力机制如何通过数学计算来判断哪些词提供了更多上下文信息?
别担心!这些问题(甚至更多)将在接下来的部分中得到解答 🚀
在“软木板”上移动单词
首先,让我们深入理解**“将一个单词移动到另一个单词更近”**是什么意思。
一个直观的理解方式是——对两个单词的词嵌入进行加权平均。
比如,如果我们想把“bank”向“river”移动 10%,可以这样表示:
Bank₁
=
0.9
×
Bank
+
0.1
×
River
\text{Bank₁} = 0.9 \times \text{Bank} + 0.1 \times \text{River}
Bank₁=0.9×Bank+0.1×River
也就是说,Bank₁ 90% 仍然是“bank”,但 10% 变成了“river”。
同样,如果我们想把“bank”向“money”移动 20%,可以这样表示:
Bank₂
=
0.8
×
Bank
+
0.2
×
Money
\text{Bank₂} = 0.8 \times \text{Bank} + 0.2 \times \text{Money}
Bank₂=0.8×Bank+0.2×Money
即 Bank₂ 80% 是“bank”,但 20% 是“money”。
用具体数值来计算 Bank₁ 和 Bank₂
在之前的词嵌入(word embeddings)章节,我们学习到,每个单词都可以被表示为一个向量(一组数字)。在 Cohere 词嵌入模型中,每个单词都对应一个 4096 维向量。
为了便于理解,我们这里假设词嵌入是二维向量,并且这些单词的词向量如下:
- River:
[0, 5] - Money:
[8, 0] - Bank:
[6, 6]
在这个二维平面中,第一个数字代表横坐标,第二个数字代表纵坐标,可以想象它们是坐标点。
计算 Bank₁ 的词嵌入
Bank₁
=
0.9
×
Bank
+
0.1
×
River
\text{Bank₁} = 0.9 \times \text{Bank} + 0.1 \times \text{River}
Bank₁=0.9×Bank+0.1×River
=
0.9
×
[
6
,
6
]
+
0.1
×
[
0
,
5
]
= 0.9 \times [6, 6] + 0.1 \times [0, 5]
=0.9×[6,6]+0.1×[0,5]
=
[
5.4
,
5.4
]
+
[
0
,
0.5
]
= [5.4, 5.4] + [0, 0.5]
=[5.4,5.4]+[0,0.5]
=
[
5.4
,
5.9
]
= [5.4, 5.9]
=[5.4,5.9]
计算 Bank₂ 的词嵌入
Bank₂
=
0.8
×
Bank
+
0.2
×
Money
\text{Bank₂} = 0.8 \times \text{Bank} + 0.2 \times \text{Money}
Bank₂=0.8×Bank+0.2×Money
=
0.8
×
[
6
,
6
]
+
0.2
×
[
8
,
0
]
= 0.8 \times [6,6] + 0.2 \times [8,0]
=0.8×[6,6]+0.2×[8,0]
=
[
4.8
,
4.8
]
+
[
1.6
,
0
]
= [4.8, 4.8] + [1.6, 0]
=[4.8,4.8]+[1.6,0]
=
[
6.4
,
4.8
]
= [6.4, 4.8]
=[6.4,4.8]
关键问题:0.9 和 0.1 这些权重是怎么来的?
这些权重的计算方式涉及相似性(similarity),但我们稍后再深入探讨。**注意力机制(attention)**的核心任务就是计算这些权重,确保“bank”能够正确偏向“river”或“money”!
下一步,我们将探讨计算机是如何学习这些权重的 🚀
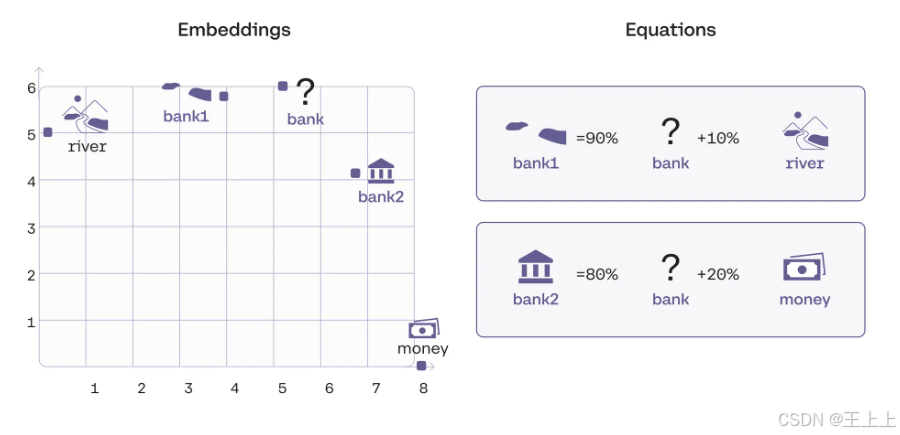
词向量的调整:Bank₁ 和 Bank₂ 的位置变化
正如你所看到的:
- Bank₁ 更接近 “river”
- Bank₂ 更接近 “money”
实际上,Bank₁ 在“bank”到“river”的连线上,距离“bank” 10% 的位置;而 Bank₂ 在“bank”到“money”的连线上,距离“bank” 20% 的位置。
这意味着,注意力机制成功地将“bank”拆分为两个不同的上下文版本,并在正确的句子中使用了对应的版本。 🚀
如何决定哪些词决定上下文?
换句话说,为什么选择 “river” 和 “money” 来决定 “bank” 的含义,而不是 “the”、 “of” 或 “in”?
显然,答案是:因为我是人类,我懂语言。 😆 但计算机如何做到这一点?
计算机可以依赖两种机制来判断:
1️⃣ 基于相似度(similarity)的方法 👉 这个你已经在前面章节学习过,我们会详细计算相似度分数。
2️⃣ 多头注意力(multi-head attention) 👉 我们会在本章后面介绍这个方法。
相似度(Similarity)方法
计算机在计算单词的上下文时,会考虑句子中的所有单词,包括 “the”、 “of”、 “in” 这些无关的词。
但是,它会根据不同单词与 “bank” 之间的相似度来决定“关注的程度”。
- 在良好的词嵌入模型中,“bank” 和 “the” 之间的相似度几乎为 0,因为它们是完全无关的。
- 但 “bank” 和 “river” 或 “bank” 和 “money” 的相似度会更高,所以模型会更加关注这些词。
这样,模型就能自动忽略无关的词,并关注那些对 “bank” 上下文更重要的词!🎯
举个例子:计算相似度
为了让这个概念更清楚,我们可以计算每个句子中所有单词与 “bank” 之间的相似度,看看哪些词真正决定了上下文。接下来,我们会用一些数值来说明这个过程! 💡
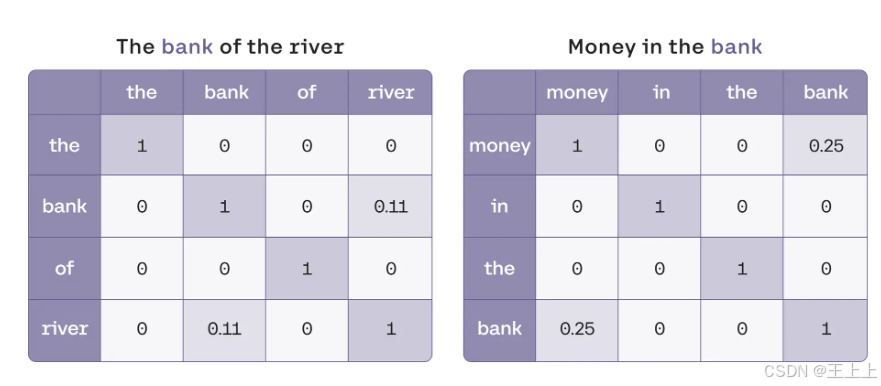
基于相似度的单词变换
我们已经知道,“bank” 在不同句子中的含义不同,而相似度可以帮助计算机判断哪些词对其含义影响更大。让我们来看看计算过程!🔢
单词之间的相似度
首先,我们假设以下相似度分数(基于语料统计):
| 词对 | 相似度 |
|---|---|
| the ↔ any word | 0 |
| bank ↔ bank | 1 |
| bank ↔ river | 0.11 |
| bank ↔ money | 0.25 |
可以看到:
- “bank” 和 “money” 的相似度比 “bank” 和 “river” 更高(0.25 > 0.11),因为“bank”更常在金融语境下使用。
- “the” 等停用词和其他词的相似度几乎为 0,因此不会影响“bank” 的语义。
计算新的单词(归一化处理)
我们希望调整句子中的单词,使它们更具上下文信息。为此,我们将每个单词与句子中所有单词的相似度相加,并进行归一化(使总权重等于 1)。
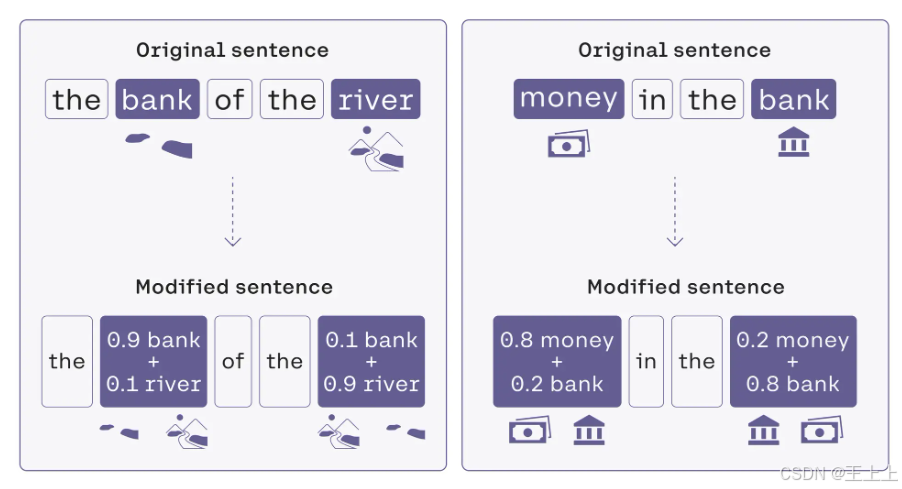
例子 1:句子 “The bank of the river”
处理 “bank”:
- 变换前:
bank - 变换方式:
bank1 = 1*bank + 0.11*river - 归一化: 总权重 =
1 + 0.11 = 1.11 - 最终变换:
bank1 = (1/1.11)*bank + (0.11/1.11)*river = 0.9*bank + 0.1*river
📌 结果:
“bank1” 在嵌入空间中更接近 “river”,反映出它的“河岸”含义。
例子 2:句子 “Money in the bank”
处理 “money”:
- 变换前:
money - 变换方式:
money2 = 1*money + 0.25*bank - 归一化: 总权重 =
1 + 0.25 = 1.25 - 最终变换:
money2 = (1/1.25)*money + (0.25/1.25)*bank = 0.8*money + 0.2*bank
📌 结果:
“money2” 更接近 “bank”,表明它的金融语境。
总结:最终的注意力机制改写句子
1️⃣ 原始句子:
- The bank of the river.
- Money in the bank.
2️⃣ 使用注意力机制调整后的句子:
- The bank₁ of the river. (
bank₁ = 0.9*bank + 0.1*river) - Money in the bank₂. (
bank₂ = 0.8*money + 0.2*bank)
总结
📌 通过注意力机制,模型能够自动调整词向量,使相同的单词“bank”在不同句子中的语义不同。
📌 这种方法避免了传统词嵌入(word2vec, GloVe)的缺陷,使模型能够理解上下文!
📌 这正是自注意力(self-attention)的核心思想!💡


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









