







【机器学习-18】-神经网络构建、训练、损失函数和优化关键步骤
以下是基于6张图片核心内容的系统化解析与实现指南,涵盖神经网络构建、训练、损失函数和优化关键步骤:
核心流程:构建模型 → 定义损失 → 梯度下降(训练)优化。
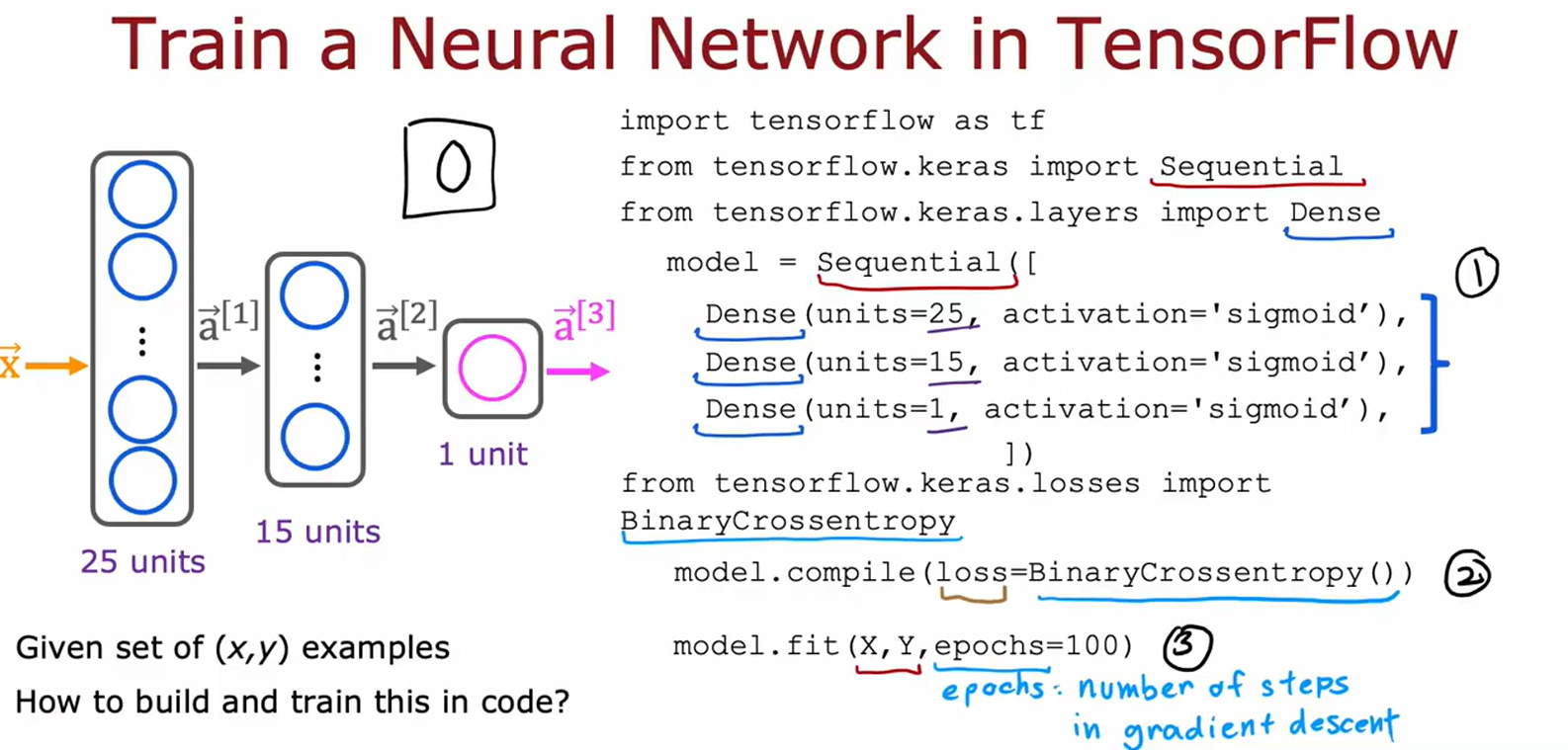
1. 神经网络构建与训练(图1, 图3)
核心代码实现
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
# 模型结构(图1, 图3)
model = Sequential([
Dense(units=25, activation='sigmoid'), # 输入层→隐藏层1
Dense(units=15, activation='sigmoid'), # 隐藏层2
Dense(units=1, activation='sigmoid') # 输出层(二分类)
])
# 编译模型(图1, 图4)
model.compile(loss=tf.keras.losses.BinaryCrossentropy())
# 训练模型(图1, 图5)
model.fit(X, y, epochs=100) # X: 输入数据, y: 标签
关键点
• 层设计:输入层维度需匹配数据特征数,输出层单元数由任务决定(如二分类用1个单元)。
• 激活函数:隐藏层常用ReLU或sigmoid,输出层根据任务选择(二分类用sigmoid)。
2. 模型训练三步骤(图2)
① 定义模型输出
• 逻辑回归:
f
w
,
b
(
x
)
=
1
1
+
e
−
(
w
⋅
x
+
b
)
f_{\mathbf{w},b}(\mathbf{x}) = \frac{1}{1+e^{-(\mathbf{w}\cdot\mathbf{x}+b)}}
fw,b(x)=1+e−(w⋅x+b)1
• 神经网络:通过Sequential和多层Dense自动计算。
② 指定损失函数(图4)
• 二分类:二元交叉熵(Binary Crossentropy)
L
(
f
(
x
)
,
y
)
=
−
[
y
log
(
f
(
x
)
)
+
(
1
−
y
)
log
(
1
−
f
(
x
)
)
]
L(f(\mathbf{x}), y) = -[y\log(f(\mathbf{x})) + (1-y)\log(1-f(\mathbf{x}))]
L(f(x),y)=−[ylog(f(x))+(1−y)log(1−f(x))]
• 回归:均方误差(Mean Squared Error)。
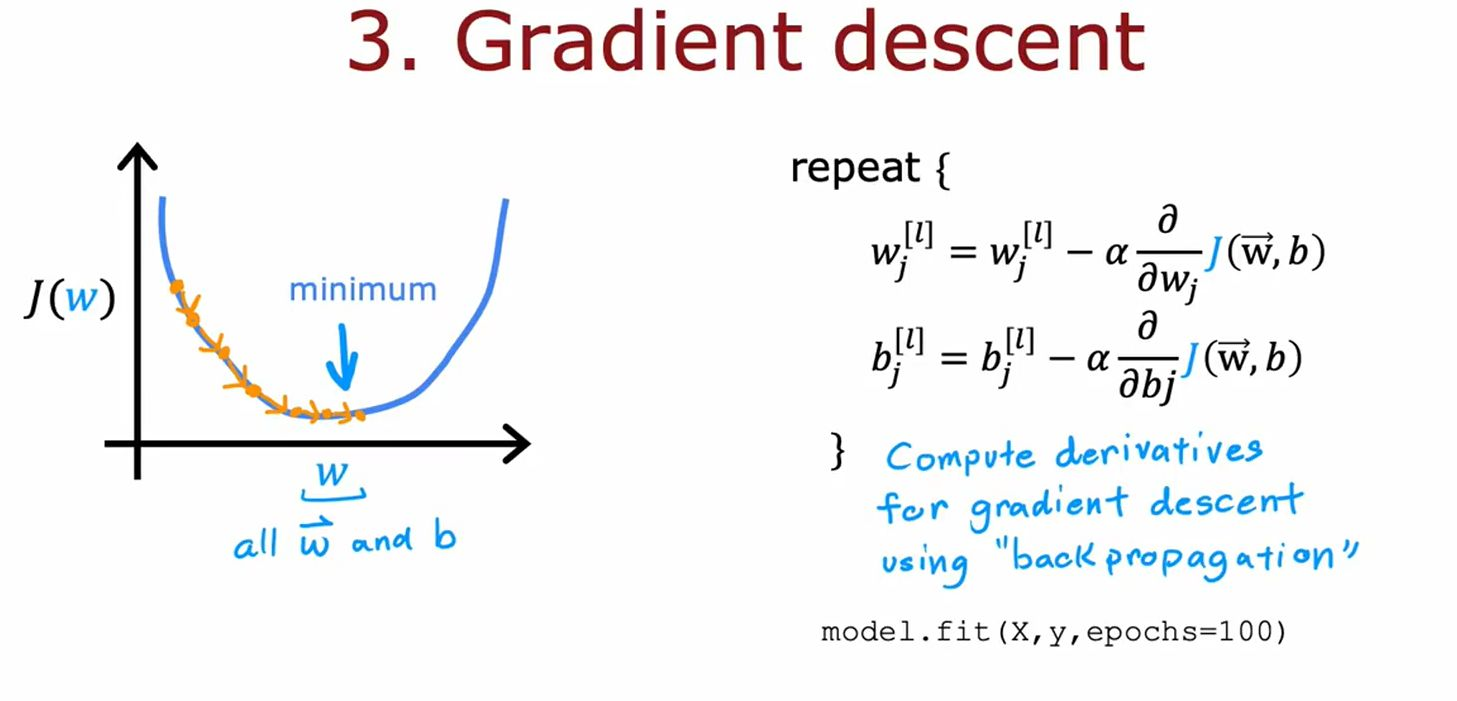
③ 训练优化(图5)
• 梯度下降公式:
w
j
[
l
]
=
w
j
[
l
]
−
α
∂
J
∂
w
j
[
l
]
w_j^{[l]} = w_j^{[l]} - \alpha \frac{\partial J}{\partial w_j^{[l]}}
wj[l]=wj[l]−α∂wj[l]∂J
b
j
[
l
]
=
b
j
[
l
]
−
α
∂
J
∂
b
j
[
l
]
b_j^{[l]} = b_j^{[l]} - \alpha \frac{\partial J}{\partial b_j^{[l]}}
bj[l]=bj[l]−α∂bj[l]∂J
• 代码实现:通过model.fit自动完成反向传播和参数更新。
3. 梯度下降与反向传播(图5)
核心原理
• 目标:最小化损失函数 ( J(\mathbf{w}, b) )。
• 步骤:
- 前向传播计算预测值。
- 反向传播计算梯度(
tf.GradientTape自动实现)。 - 更新参数:
w = w - learning_rate * gradient。
学习率(α)选择
• 过大:可能无法收敛;过小:训练缓慢。
• 建议:初始尝试0.01,通过观察损失曲线调整。
4. 神经网络库选择(图6)
| 库 | 特点 | 适用场景 |
|---|---|---|
| TensorFlow | 静态图为主,生产部署成熟 | 工业级应用、移动端部署 |
| PyTorch | 动态图灵活,研究社区活跃 | 学术研究、快速原型开发 |
调试建议
• 理解底层实现:如手动实现前向/反向传播,便于调试NaN损失或梯度爆炸问题。
• 工具使用:
• TensorBoard(可视化训练过程)
• PyTorch的autograd检查梯度。
5. 综合解题思路
题目示例
“构建一个神经网络对手写数字进行二分类(如是否为数字5),并训练模型。”
解答步骤
-
数据准备:
• 输入X:标准化像素值(0-1)。
• 标签y:1(是5),0(非5)。 -
模型构建:
model = Sequential([ Dense(64, activation='relu', input_shape=(784,)), # 输入层(28x28图像展平) Dense(1, activation='sigmoid') ]) -
编译与训练:
model.compile(optimizer='adam', loss='BinaryCrossentropy', metrics=['accuracy']) model.fit(X_train, y_train, epochs=10, validation_data=(X_val, y_val)) -
调优:
• 若验证准确率低:增加层数/单元数,或调整学习率。
• 若过拟合:添加Dropout层或正则化。
总结
• 核心流程:构建模型 → 定义损失 → 梯度下降优化。
• 关键技巧:
• 使用高级API(如tf.keras)简化代码,但需理解数学原理以便调试。
• 监控训练损失/准确率曲线判断模型表现。






















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









