







【机器学习-13】-线性回归和逻辑回归(分类)正则化
以下是正则化线性回归与梯度下降的完整解析和标准解题流程:
一、核心公式解析
1. 正则化线性回归损失函数
J
(
w
,
b
)
=
1
2
m
∑
i
=
1
m
(
f
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
2
m
∑
j
=
1
n
w
j
2
J(\mathbf{w},b) = \frac{1}{2m} \sum_{i=1}^{m} (f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)})^2 + \frac{\lambda}{2m} \sum_{j=1}^{n} w_j^2
J(w,b)=2m1∑i=1m(fw,b(x(i))−y(i))2+2mλ∑j=1nwj2
• 组成部分:
• 数据拟合项:
1
2
m
∑
(
预测值
−
真实值
)
2
\frac{1}{2m} \sum (预测值-真实值)^2
2m1∑(预测值−真实值)2(MSE均方误差)
• L2正则化项:
λ
2
m
∑
w
j
2
\frac{\lambda}{2m} \sum w_j^2
2mλ∑wj2(惩罚大权重,防止过拟合)
• 参数说明:
• (m):样本数量
•
λ
\lambda
λ:正则化系数(控制惩罚强度)
• (n):特征维度
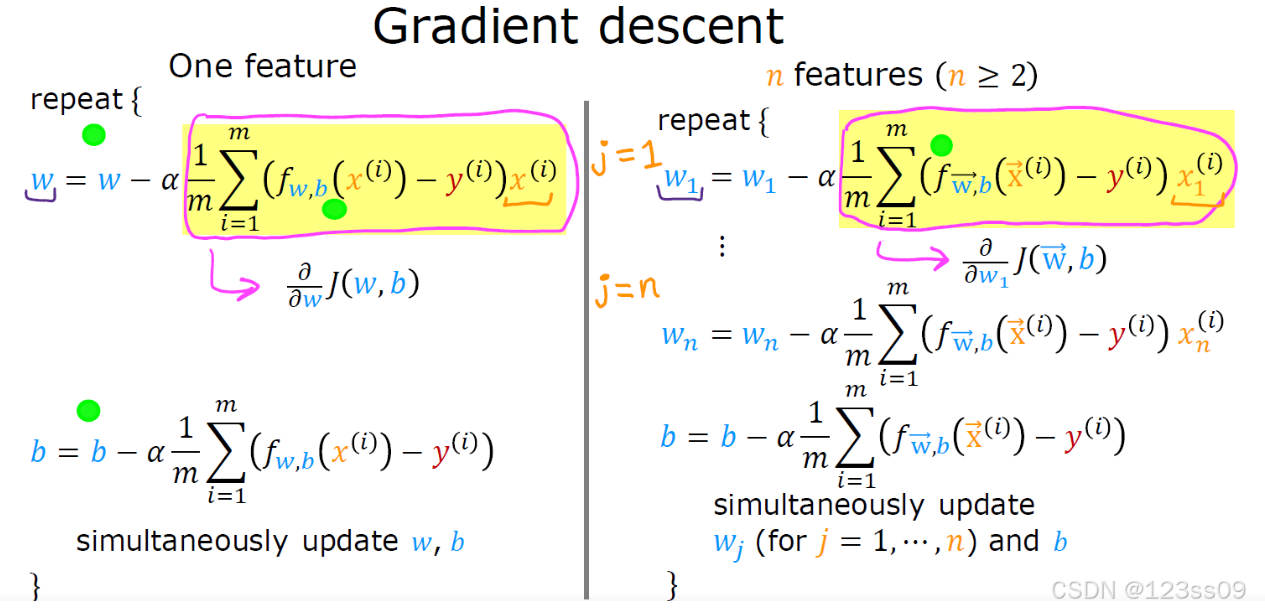
2. 梯度下降更新规则
• 权重更新:
w
j
:
=
w
j
−
α
[
1
m
∑
i
=
1
m
(
f
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
+
λ
m
w
j
]
w_j := w_j - \alpha \left[ \frac{1}{m} \sum_{i=1}^{m} (f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)})x_j^{(i)} + \frac{\lambda}{m} w_j \right]
wj:=wj−α[m1∑i=1m(fw,b(x(i))−y(i))xj(i)+mλwj]
• 偏置更新:
b
:
=
b
−
α
[
1
m
∑
i
=
1
m
(
f
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
]
b := b - \alpha \left[ \frac{1}{m} \sum_{i=1}^{m} (f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)}) \right]
b:=b−α[m1∑i=1m(fw,b(x(i))−y(i))]
• 关键区别:偏置 (b) 不参与正则化(因其不直接影响特征权重)
二、解题步骤与代码实现
步骤1:初始化参数
import numpy as np
def initialize_parameters(dim):
w = np.zeros(dim) # 权重初始化为0
b = 0 # 偏置初始化为0
return w, b
步骤2:计算正则化梯度
def compute_gradient(X, y, w, b, lambda_):
m = len(y)
f = np.dot(X, w) + b # 预测值
dw = (1/m) * np.dot(X.T, f-y) + (lambda_/m) * w # 含正则化的权重梯度
db = (1/m) * np.sum(f-y) # 偏置梯度(无正则化)
return dw, db
步骤3:梯度下降迭代
def gradient_descent(X, y, alpha, lambda_, num_iters):
w, b = initialize_parameters(X.shape[1])
for i in range(num_iters):
dw, db = compute_gradient(X, y, w, b, lambda_)
w -= alpha * dw
b -= alpha * db
return w, b
三、关键问题与解决方案
问题1:如何选择正则化系数 (\lambda)?
• 网格搜索法:
from sklearn.linear_model import Ridge
from sklearn.model_selection import GridSearchCV
params = {'alpha': [0.01, 0.1, 1, 10]} # alpha即λ
grid = GridSearchCV(Ridge(), param_grid=params, cv=5)
grid.fit(X_train, y_train)
best_lambda = grid.best_params_['alpha']
问题2:为什么偏置 (b) 不需要正则化?
• 数学解释:偏置仅影响输出平移,不参与特征权重分配,正则化会破坏模型的平移自由度。
问题3:梯度下降的收敛条件?
• 停止标准:
• 迭代次数达到预设值(如1000次)
• 损失函数变化量小于阈值(如 ( \Delta J < 10^{-6} ))
四、可视化验证方法
-
学习曲线监控:
plt.plot(range(num_iters), cost_history) plt.xlabel('Iterations') plt.ylabel('Loss') plt.title('Convergence Check')• 正常情况:损失单调递减至平稳
• 异常情况:震荡(需调小学习率 (\alpha)) -
权重分布直方图:
plt.hist(w, bins=30) plt.title('Weight Distribution (λ={})'.format(lambda_))• 理想效果:权重集中在0附近(L2正则化特性)
五、面试高频考点
-
L1 vs L2正则化:
• L1(Lasso):产生稀疏解,适合特征选择
• L2(Ridge):平滑解,适合共线性数据 -
学习率 (\alpha) 选择技巧:
• 尝试对数尺度(如0.001, 0.01, 0.1)
• 使用学习率调度器(如Adam优化器) -
数值稳定性技巧:
• 特征标准化(加速收敛)
• 梯度裁剪(防止梯度爆炸)
如果需要具体数学推导或实际项目案例,可进一步说明!


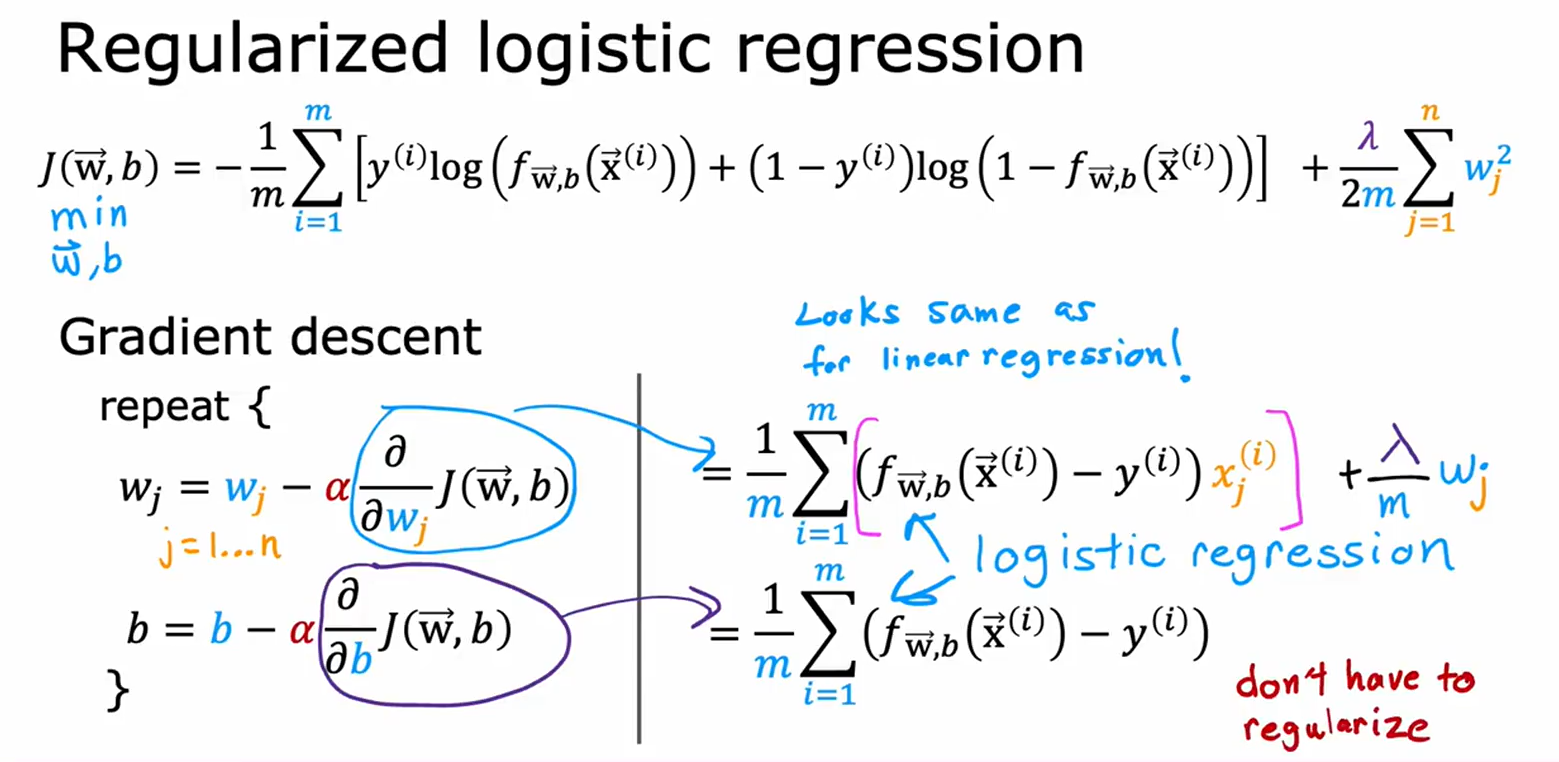
未正则化的链接
逻辑回归正则化


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









