




【读论文06】-Predicting Landslides Using Locally Aligned Convolutional Neural Networks
摘要
摘要(Abstract)
滑坡是土壤和岩石在重力作用下的运动,每年都会造成重大的人身和经济损失。专家通常使用坡度、高程、土地覆盖、岩性、岩石年代和岩石类型等多种异构特征来预测滑坡。
为了处理这些特征,我们对卷积神经网络(CNN) 进行了改进,使其能够考虑相对空间信息来进行预测。传统 CNN 过滤器通常具有固定方向或旋转不变性,但在滑坡预测任务中,过滤器应当朝向上坡方向。然而,由于数据不足,模型难以自动学习“上坡”概念,因此我们将其作为先验知识提供给模型。
为此,我们提出了一种名为 Locally Aligned Convolutional Neural Network(LACNN) 的模型,该模型能够沿着地表在多个尺度上对齐,以预测某个单点的滑坡发生概率。
为了验证我们的方法,我们创建了一个标准化的地理参考数据集,包含多种异构特征作为输入,并与多个基线模型(线性回归、神经网络和普通卷积网络)进行比较。我们使用 负对数似然误差(log-likelihood error) 和 受试者工作特征曲线(ROC 曲线) 在测试集上评估模型性能。
实验结果表明,与其他基线模型相比,LACNN 在准确率方面提升了 2-7%,在负对数似然方面提升了 2-15%,证明了其在滑坡预测任务中的有效性。
1 引言
滑坡是地球物质在重力作用下向下移动的现象,是常见的破坏性现象。尽管有许多研究专注于滑坡制图 和滑坡空间和时间概率预测,有效的真实世界预测模型稀缺,山体滑坡每年都会造成重大的生命和经济损失。滑坡敏感性绘图有三种不同的方法:基于专家的方法、基于物理的方法和统计方法。基于专家的方法依赖于领域专家的定性判断,而基于物理的方法则根据岩土工程岩石和土壤特性等物理参数对边坡的稳定性进行建模,并计算不稳定因素和边坡强度之间的平衡,但通常需要比按比例尺获得的信息更多的信息。统计模型依赖于大型滑坡数据库的统计分析及其与景观属性的关系。环境属性通常包括斜坡的内部(例如斜坡角度、岩石类型等)和外部(例如降雨量)属性。然后使用这些数据来绘制边坡崩塌的空间和/或时间概率 。山体滑坡发生的空间概率通常称为易发性图。当还考虑幅度和时间分量(例如频率和触发因素)时,它被称为危险地图。
近年来,用于预测山体滑坡的统计方法显著增加。然而,他们主要应用线性逻辑回归、支持向量机 (SVM) 或神经网络等模型。在这项研究中,我们提出了一种新的卷积模型,我们称之为局部对齐卷积神经网络 (LACNN),用于生成磁化率图。卷积神经网络 (CNN) 构成了一类具有绑定参数的神经网络模型。具有池化层的 CNN 可以捕获图像的局部和全局特征,这已被证明在许多视觉任务中非常有用,例如对象识别、图像分类和对象检测。
我们对预测地面上每个点的山体滑坡概率感兴趣。我们模型的输出是一个概率图,其分辨率与输入特征相同。为此,我们使用了一个完全卷积的模型。这些模型已广泛用于图像分割,通常由下采样和上采样阶段组成。此类别中流行的模型之一是 UNet,我们的架构基于它。下采样阶段由具有池化层的卷积组成,并尝试创建一组捕获输入特征的局部和全局属性的紧凑特征。上采样阶段通常由卷积转置层组成,这些层主要执行池化的逆作,但使用学习的参数。我们在模型中不使用卷积转置层,因为它们倾向于 arXiv:1911.04651v5 [cs.CV] 17 Jul 2020 在我们的实验中产生棋盘伪影,这也是文献中的常见问题[Aitken等人,2017 年]。相反,我们使用 interpolation 进行上采样。已经表明,在全卷积模型中添加跳跃连接可以提高其性能 [Drozdzal et al., 2016;毛等人,2016 年]。由于短 Skip 连接已被证明仅在非常深的网络中有效,因此我们只将长连接应用于我们的模型。
为了生成良好的滑坡敏感性图,我们提出了学习过滤器,这些过滤器可以跟踪地表并提取上坡方向的特征。为此,我们需要 CNN 模型来保留滑坡彼此的方向信息,但这无法使用传统技术,当过滤器要么旋转不变,要么向上、向下、向左和向右对齐时,这对应于北、南、东和西。我们在 CNN 模型中添加了一个预处理阶段,以在多个尺度上为每个像素找到最佳方向,然后根据这些方向学习隐藏特征。我们将此模型称为本地对齐 CNN,因为该模型首先将自身与一组特定的方向对齐,然后学习分类器。
我们论文的贡献是:
• 我们提供了一个标准化的数据集,以便其他人可以将他们的结果与我们的结果进行比较。此数据集根据来自各种来源的公共领域数据编译而成,包括 CORINE 土地覆盖清单 1、意大利国家地理门户网站 2 以及国家地球物理学和火山学研究所 3。该数据集由多个输入特征组成,例如坡度、海拔、具有年龄和家族的岩石类型、土地覆被,以及滑坡多边形形状的地面实况,可用于监督和无监督学习框架。
• 我们提出了一种使用深度卷积网络预测滑坡的新型统计方法。我们开发了一个模型,可以在多个不同范围内捕获每个像素的方向,以对滑坡进行分类。我们在模型中使用 30 米、100 米和 300 米的范围。可以使用交叉验证来优化这些尺度。
• 我们定义了几个代表当前技术水平的基线模型,以便进行比较。我们提供了五个不同的基线,包括 Naive 模型、线性逻辑回归 (LLR)、神经网络 (NN) 和没有任何卷积的局部对齐神经网络 (LANN) 模型,以将模型的性能与它们进行比较。这些基线也可以被视为我们模型的消融研究。
• 我们提供了一种使用具有异构数据集的 CNN 模型来预测滑坡的方法,而不仅仅是使用我们模型中的图像。
2 相关工作
通过统计方法制作磁化率图在滑坡社区并不新鲜。许多人一直在使用逻辑回归、SVM 和随机森林等模型。Catani et al. [2013] 使用随机森林生成敏感度图,强调敏感性和缩放问题。Micheletti 等人 [2013] 和 Youssef 等人 [2014] 也使用随机森林模型来预测瑞士和沙特阿拉伯 Wadi Tayyah 盆地的山体滑坡。有些人开发了使用随机森林进行易感率映射的软件包 [Behnia 和 Blais-Stevens,2017]。Micheletti et al. [2013] 使用 SVM、随机森林和 Adaboost 生成了几个敏感性映射。Atkinson 和 Massari [1998]、Ayalew 和 Yamagishi [2005] 以及 Davis 等人 [2006] 专注于线性回归预测滑坡,因为它简单易行。在贝叶斯网络等概率框架中构建问题的有很多方法 [Heckmann et al., 2015;Lombardo等人,2018 年]。
神经网络和卷积模型是易感映射的最新方法之一。 Luo等。 [2019]和Bui等。 [2015]使用神经网络评估矿山滑坡的敏感性并预测浅滑坡危险。 Wang等。 [2019]对CNN进行了针对滑坡敏感性映射的比较研究,但它们的方法也不包含任何取向信息或对齐过滤器。现有的卷积模型通常不深,并且不使用任何合并层来考虑多种分辨率进行特征提取[Xiao L,2018]。这些模型中的大多数在滑坡易感性映射中都非常简单,并且不考虑任何方向。此外,他们的网络不包含可以在滑坡之间旋转或捕获方向的过滤器。我们提出的CNN架构更加复杂。这是一个完全卷积的网络,它以多种分辨率下图像图像,并学习可以使自己与上坡方向保持一致的过滤器。此外,我们的模型经过地理空间数据而不是卫星图像的培训。
3数据集
用于滑坡预测的数据集来自意大利的开源数据库,其中包含连续特征和分类特征,分别以栅格(raster) 和 矢量文件(vector files) 的形式存储。
- 连续特征(如坡度和DEM4)存在超出范围的数值。
- 分类特征(如岩石类型、土地覆盖、岩石年代和岩石类别)包含多个无数据点(no-data points)。
为了使这些数据适用于 CNN(卷积神经网络),我们采取了以下预处理步骤:
- 矢量数据转换:将所有矢量地图转换为栅格格式。
- 数据清理:移除无效数据点和超出范围的数值。
通过这些处理,我们确保数据格式统一,使其能够有效输入 CNN 进行滑坡预测。
为了构建适用于此类问题的基线框架(baseline framework),我们需要为分类数据确定一套标准特征集。我们根据Inspire术语选择了44种岩石类型,5种土地覆盖物,5个岩石类别和38个岩龄特征,作为我们的分类数据的单热编码。 INSPIRE(Infrastructure for Spatial Information in Europe) 是欧盟(EU)制定的空间数据标准化指令,旨在促进欧洲各国间地理空间数据的标准化。采用 INSPIRE 术语体系,可以确保我们的数据与其他研究和应用保持一致性,提高可比性和可复用性。
根据INSPIRE术语标准,我们最终确定了94个标准化输入特征。这些特征包括:
• 44个岩性特征(如片麻岩
g
n
e
i
s
s
gneiss
gneiss、云母片岩
m
i
c
a
-
s
c
h
i
s
t
mica\text{-}schist
mica-schist、花岗岩
g
r
a
n
i
t
e
granite
granite、粉砂岩
s
i
l
t
s
t
o
n
e
siltstone
siltstone等)
• 5个土地覆盖特征(农业区
a
g
r
i
c
u
l
t
u
r
a
l
a
r
e
a
s
agricultural\ areas
agricultural areas、人工表面
a
r
t
i
f
i
c
i
a
l
s
u
r
f
a
c
e
s
artificial\ surfaces
artificial surfaces、森林与半自然区
f
o
r
e
s
t
a
n
d
s
e
m
i
-
n
a
t
u
r
a
l
a
r
e
a
s
forest\ and\ semi\text{-}natural\ areas
forest and semi-natural areas、水体
w
a
t
e
r
b
o
d
i
e
s
water\ bodies
water bodies、湿地
w
e
t
l
a
n
d
s
wetlands
wetlands)
• 4个岩族特征(变质岩
m
e
t
a
m
o
r
p
h
i
c
metamorphic
metamorphic、沉积岩
s
e
d
i
m
e
n
t
a
r
y
sedimentary
sedimentary、深成岩
p
l
u
t
o
n
i
c
plutonic
plutonic、火山岩
v
o
l
c
a
n
i
c
volcanic
volcanic)
• 38个岩龄特征(如古生代旋回
p
a
l
e
o
z
o
i
c
c
y
c
l
e
paleozoic\ cycle
paleozoic cycle、白垩纪-侏罗纪旋回
c
r
e
t
a
c
e
o
u
s
-
j
u
r
a
s
s
i
c
c
y
c
l
e
cretaceous\text{-}jurassic\ cycle
cretaceous-jurassic cycle、三叠纪平均旋回
a
v
e
r
a
g
e
t
r
i
a
s
s
i
c
c
y
c
l
e
average\ triassic\ cycle
average triassic cycle等)
• 数字高程模型
d
i
g
i
t
a
l
e
l
e
v
a
t
i
o
n
m
o
d
e
l
digital\ elevation\ model
digital elevation model地图(贡献2个特征)
此外,岩族特征包含未知类别
u
n
k
n
o
w
n
c
l
a
s
s
unknown\ class
unknown class,并增加坡度图
s
l
o
p
e
m
a
p
slope\ map
slope map,最终构成94维特征空间。
我们选择了意大利的威尼托(Veneto)地区作为研究区域,因为该地区既包括山区,也有接近海岸的平坦地区。 我们准备的数据集中的每个像素具有10米分辨率,图像大小为 21005×19500 像素,覆盖的区域大约为 210 km(宽度) 和 195 km(高度)。 该地区的滑坡比例低于 1%,因此数据集极为不平衡。威尼托的滑坡包括山区和较为平缓的地区,这对于训练我们的模型非常有益。 然而,滑坡数据通常不包含发生日期的信息。这些特性使得该数据集从机器学习的角度来看,具有很大的挑战性。
关于如何访问该数据的说明,可以在以下链接找到供其他研究者参考: VenetoItaly 数据集。
4 Locally Aligned Convolutional Neural Network (LACNN)
**坡度(slope)**是预测滑坡的主要影响因素之一。我们训练的 LLR 基线 模型也验证了这一点,因为坡度的权重位居前五名。
传统的卷积神经网络(CNN)滤波器在图像中通常是垂直方向对齐的,但对于滑坡预测,上坡和下坡的方向才是最为重要的。因此,我们提出了一个Locally Aligned CNN(LACNN) 模型,其滤波器根据上坡方向对齐,并在该方向上提取特征。
具体来说,对于每个像素,我们考虑三个不同的范围,并选择每个范围内的最高海拔值,并在这些点上提取相关特征(见图1)。
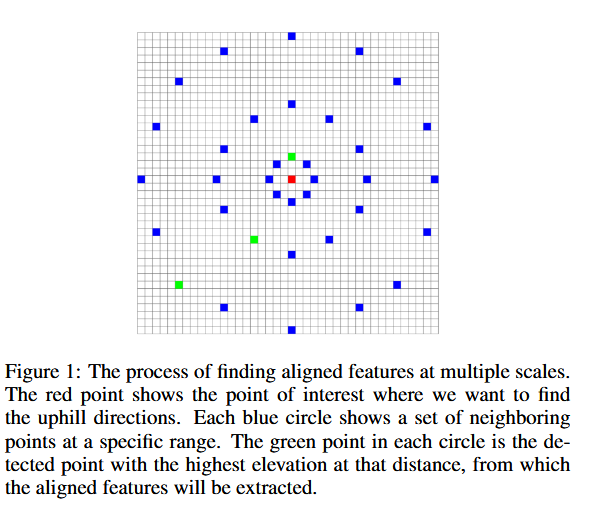
考虑到空间限制,我们选择了一个包含22个特征的子集来进行此操作。选取这些特征是基于我们训练得到的 LLR 基线模型。我们选择的特征是:其逻辑回归权重的绝对值大于等于 0.2的特征。
4.1体系结构
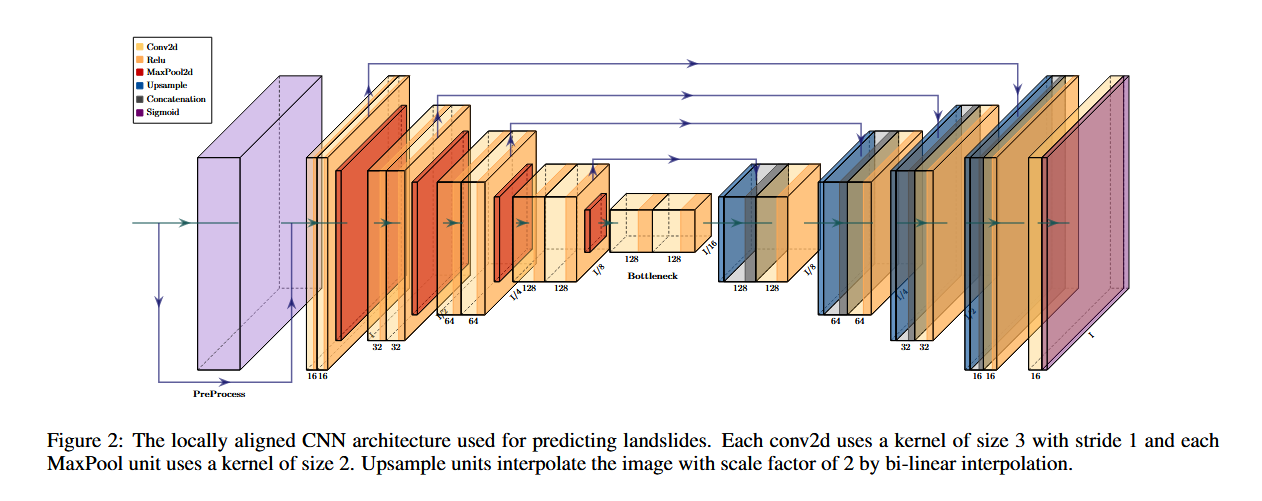
我们的局部对齐 CNN(LACNN) 架构由一个预处理模块以及四层下采样和上采样组成,如图 2 所示。
-
预处理模块:
- 该模块接收高程图以及数据集中的其他输入特征,并输出针对不同观察距离对齐的 22 维特征。
- 在实验中,我们选择30 米、100 米和 300 米作为观察距离,但该参数也可以作为超参数,通过交叉验证进行优化。
- 预处理模块最终输出 66 维对齐特征,并将其与原始的 94 维特征一起输入到卷积网络中。
-
LACNN 结构:
- 在 LACNN 体系结构中,我们在每个采样层之间应用了长跳跃连接(skip connections)。
- 每个下采样层由两个卷积层(带有 ReLU 非线性激活函数)和一个**最大池化层(max-pooling)**组成。
- 每个上采样层包括一个上采样模块(用于数据插值)、卷积层和 ReLU 激活函数。
- 最后,我们对模型输出应用Sigmoid 函数,以获得概率结果。
4.2 训练过程
由于数据集中栅格(raster)图像尺寸过大,无法适配 TitanXP GPU 的 12GB 显存,因此我们将每个栅格(即输入特征)划分为 500×500 像素的小图像,称为patches(图像块),并以小批量(minibatches)形式输入模型进行训练。
为了生成整个区域的连贯概率图,我们使用重叠的图像块。具体来说,我们对每个图像块的四周填充 64 像素,使其最终尺寸达到 628×628,以确保图像块之间的重叠部分大于网络的感受野。
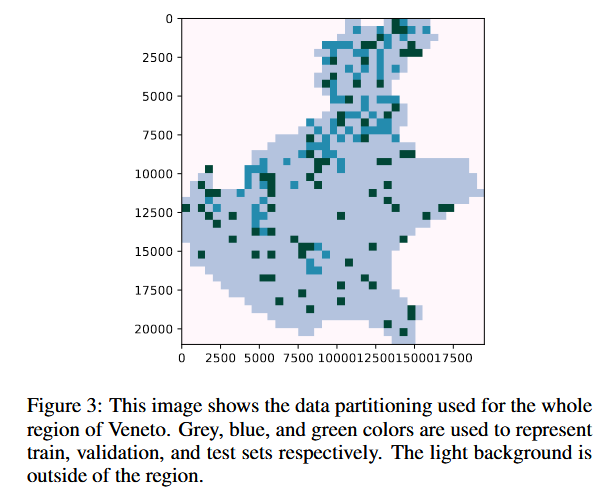
我们将这些图像块划分为训练集、测试集和验证集,并采用随机分割的方式,其中 80% 用于训练,10% 用于测试,10% 用于验证(见图 3)。
损失函数与数据不平衡处理
- 我们采用 负对数似然损失(negative log-likelihood loss) 进行模型训练。
- 由于训练数据极度不均衡,我们使用过采样(oversampling) 来一定程度上平衡数据。
- 具体做法是优先过采样包含至少一个正样本(滑坡像素点)的图像块,从而同时增加滑坡区域和非滑坡区域的样本数量。
- 经过处理后,滑坡像素点的比例仍然低于 1%。
- 该过采样方法也可视为一种数据增强(data augmentation),可为模型提供更多训练样本。
- 在实验中,我们使用了 5 倍的过采样比率。
4.3 超参数(Hyper-Parameters)
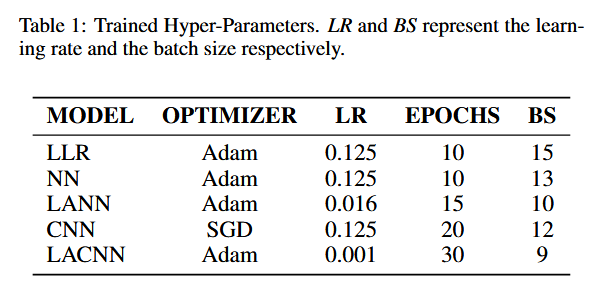
表 1 展示了用于训练各模型的超参数。我们通过 5 折交叉验证(5-fold cross-validation) 对 学习率(learning rate) 和 优化器(optimizer) 进行优化,并在**一个训练周期(epoch)**内选择最佳参数。
- 批量大小(batch size):根据显存容量,选择能适应最大数量图像块的批量大小。
- 训练周期(epochs):选择足够的训练周期,以确保模型充分训练。
- 学习率调整:
- 在每个训练周期进行模型验证(validation)。
- 如果验证误差(validation error)连续Patience 个周期上升,则减少学习率,以防止过拟合(overfitting)。
- 我们在实验中设定 Patience = 2。
- 正则化:使用 L2 正则化(L2 regularization),正则化系数(lambda)设定为 0.001。
我们的代码已公开,链接如下:
GitHub 仓库:LandslidePrediction
4.4 基线模型(Baselines)
我们提出了一个Naive 基线模型,其预测值在整个图像中均为 0.013(即训练集中滑坡像素点的比例)。
- 根据负样本(0 标签)与正样本(1 标签) 的比例,我们可以计算 Naive 基线模型在训练集和测试集上的期望负对数似然损失(negative log-likelihood error):
- 训练集误差约为 0.069
- 测试集误差约为 0.065
- 我们将其他基线模型的训练误差和测试误差与 Naive 模型进行对比,以确保学习到的模型比 Naive 模型表现更优(见表 2)。
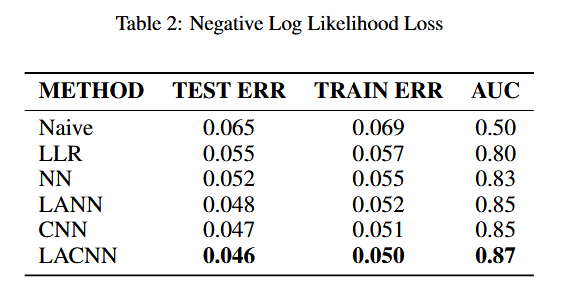
比较模型
为了分析 LACNN 模型的核心特性,我们引入了多个基线模型:
- CNN 基线(仅使用卷积):
- 该模型不考虑上坡方向,仅通过卷积层来预测滑坡。
- LANN 基线(仅提取上坡方向特征):
- 该模型不使用卷积,但会从上坡方向提取特征。
- NN(简单神经网络):
- 该模型既不使用卷积,也不提取上坡特征。
- LLR(线性逻辑回归模型):
- 作为一个线性基线模型,与其他方法进行对比。
这些模型可以看作是对 LACNN 进行的消融实验(ablation study),用于验证局部对齐滤波器(locally aligned filters)在卷积框架中的有效性。
此外,这些基线模型也代表了滑坡预测领域当前主流的方法。
5 结果(Results)
我们展示了 LACNN 模型 生成的最终滑坡易发性(susceptibility)地图,并在 图 4a 和 4b 中与真实标签(ground truth) 进行对比。
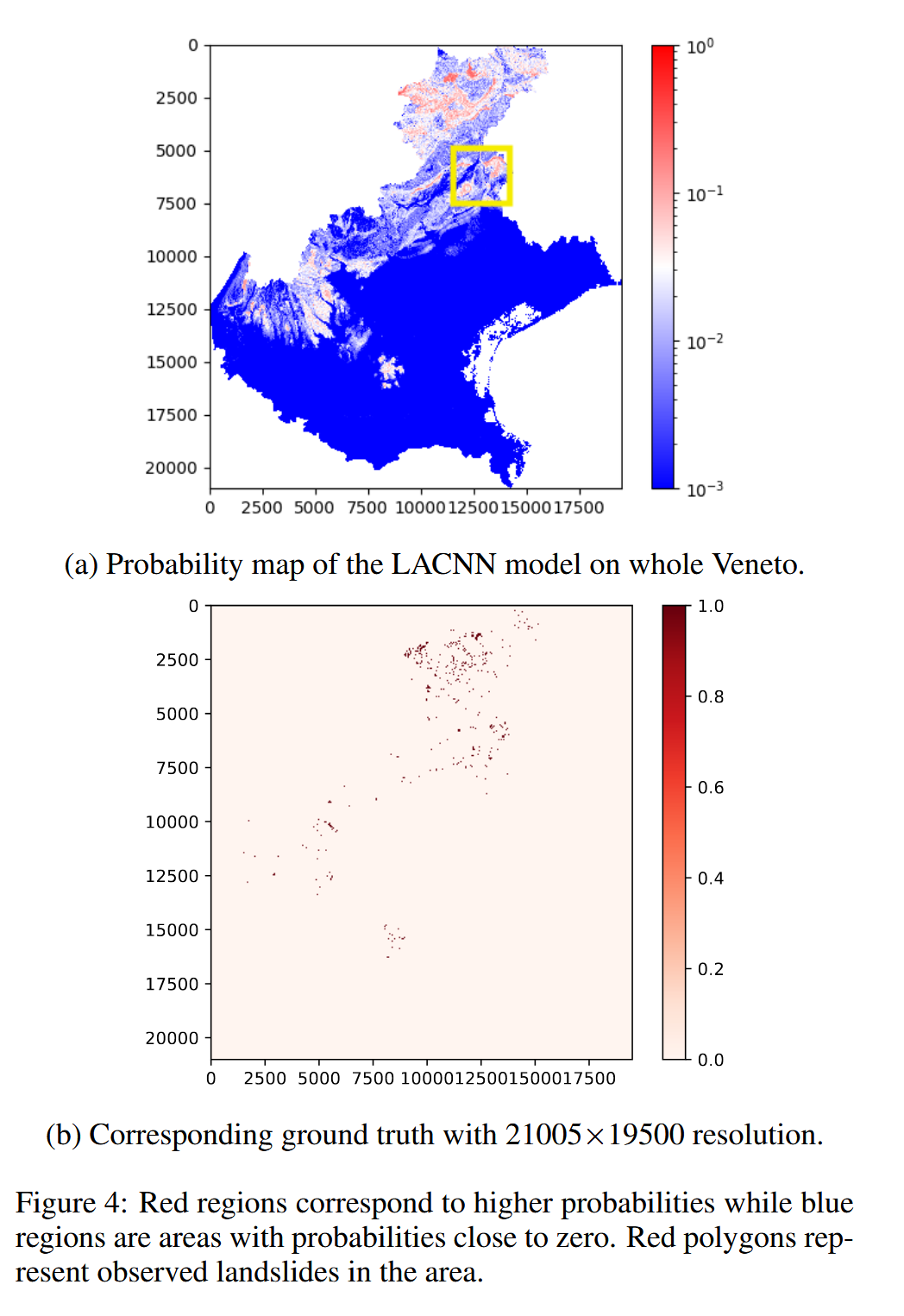
- 该易发性地图覆盖整个 Veneto 地区。
- 生成的概率图包含丰富的细节,能够识别出滑坡周围的高易发区域。
- 由于滑坡事件没有具体的时间尺度,模型输出的概率对应的是未定义时间段的相对易发性,应当仅作为相对风险参考。
模型对比分析
为了更详细地对比不同模型的表现,我们在图 5 中展示了 Veneto 地区的一个较小区域的预测结果。
- 图 4a 中的黄色矩形表示该区域在整个地图中的位置。
- 该区域包含滑坡区域和非滑坡区域,同时具有丰富的地形变化。
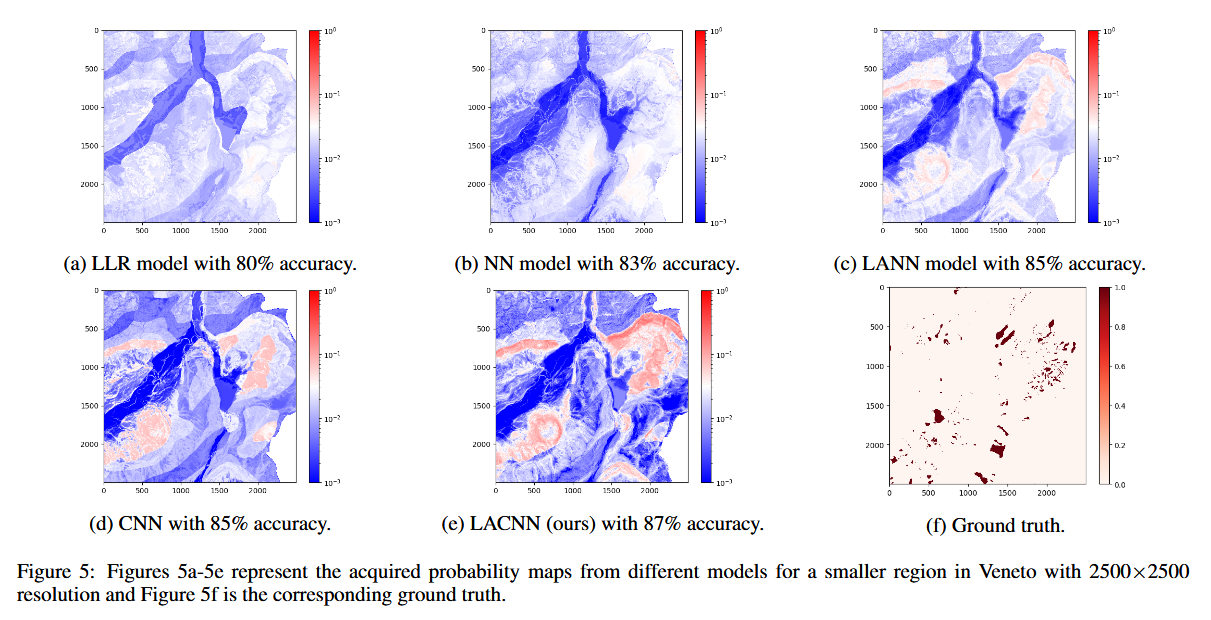
分析结果:
- 图 5a-5e 显示,随着模型参数数量增加、复杂度提高,生成的易发性地图变得更加详细。
- 不同模型的预测概率范围有所不同,复杂模型的预测方差更大,表现出更高的预测置信度。
- 基线模型(LLR 和 NN) 代表了当前主流方法的大部分能力,但无法对滑坡给出高置信度的预测,而更复杂的模型能更好地刻画数据分布。
关于模型置信度(confidence)和准确性(accuracy):
- 低置信度并不意味着低准确率。
- 例如,即使是简单的 LLR 模型,在足够小的阈值下,也可以得到满意的预测结果。
- 但如果目标是生成高质量的滑坡易发性地图,并精准刻画数据分布,则需要更复杂、置信度更高的模型。
5.1 评估指标(Evaluation Metrics)
我们使用受试者工作特征曲线(ROC 曲线)在测试集上评估 LACNN 模型 与其他基线模型的表现,并发现 LACNN 取得了最佳结果,其性能比其他模型高出 2% 至 7%(见图 6)。
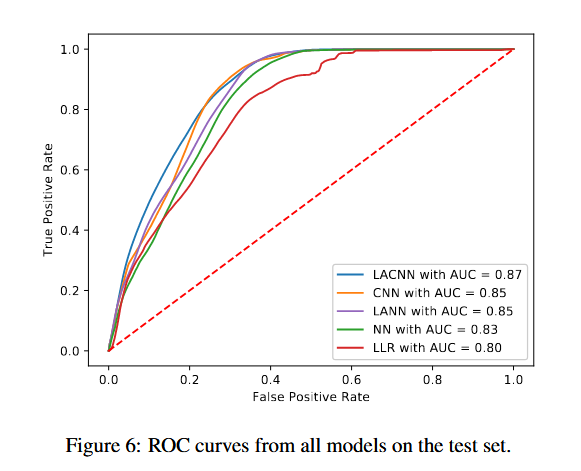
关键观察
- LANN 模型的表现与 CNN 模型相似,这非常有趣。
- LANN 不使用卷积,而仅基于上坡方向(30、100、300 米)提取特征进行预测。
- 这表明:特征对齐(alignment)在滑坡预测中的作用非常重要。
负对数似然损失(Negative Log-Likelihood Error)
- 为了进一步评估模型,我们计算了训练集和测试集的负对数似然误差。
- 表 2 展示了所有基线模型的结果。
- LACNN 在训练集和测试集上均取得最低误差,比基线模型降低 2% 至 15%。
这些结果表明,LACNN 通过局部对齐的卷积操作,有效提升了滑坡预测的准确性。
6 结论(Conclusion)
滑坡是由于重力作用引起的地面运动,是一种常见的自然现象,可能导致严重的人员伤亡和经济损失。为了减少滑坡的影响,研究人员提出了多种易发性分析方法,包括:
- 基于专家经验的方法(expert-based methods)
- 基于物理的模型(physics-based methods)
- 统计方法(statistical methods)
然而,这些方法各有局限性,且缺乏统一的特征标准。因此,我们提供了一个标准化的开源数据集,其术语与 INSPIRE 体系一致,以便研究人员可以使用相同的标准术语与我们的基线模型进行对比。
此外,我们提出了一种新的统计方法,结合机器学习进行滑坡预测,并引入了一种深度卷积模型——LACNN。该模型的核心特点是:
- 能够沿着地表对齐,与地形等高线保持一致,以提取相关特征。
- 通过ROC 曲线和负对数似然误差(negative log-likelihood error) 进行评估,并在测试集中优于所有基线模型。
最终,我们的研究结果表明,这种统计方法在生成滑坡易发性地图方面是有效的,并且有潜力减少滑坡带来的人员和经济损失。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









