 SQL Server覆盖索引设计与Key Lookup优化
SQL Server覆盖索引设计与Key Lookup优化




| INCLUDE 中是否包含字段 | 是否能提高查询性能 |
|---|---|
| 不包含任何字段 | 有可能提升性能,但可能需要回表(Key Lookup),效率有限 |
| 只包含主键或 ID | 可能不如预期,具体取决于查询语句 |
| 包含所有 SELECT 字段 | 最佳方案 —— 覆盖索引,避免 Key Lookup,性能最佳 |
什么是 INCLUDE 的作用?
在 SQL Server 中,CREATE NONCLUSTERED INDEX ... INCLUDE (...) 的作用是:
在索引中“附带”一些字段,这些字段不会作为排序依据(非键列),但可以直接从索引中获取数据,从而避免访问基表(Clustered Index 或 Heap)。
完全命中索引(Index Seek + Covering)
❌ 不需要再进行 Key Lookup(也叫 Bookmark Lookup)
情况一:索引不包含任何字段(仅用于查找)
- ✅ 可以快速定位到满足
del=0 AND city='北京'的记录; - ❌ 但要返回
dt,complete,money1这些字段,必须回表查 Clustered Index(Key Lookup); - ⚠️ 如果结果集很大,Key Lookup 会显著影响性能。
情况二:索引只包含 ID(比如聚集索引键)
id是聚集索引键,可用于回表;- ❌ 但仍然需要 Key Lookup 才能获取
dt,complete,money1; - ⚠️ 性能没有本质提升。
情况三:索引包含所有需要的字段(覆盖索引)
- 查询所需的所有字段都来自这个索引;
- ❌ 不需要 Key Lookup;
- ✅ 查询速度更快,效率更高。
什么时候可以不用 INCLUDE 所有字段?
有时候你并不需要将所有字段都包含进索引,这取决于你的查询模式:
场景 是否建议 INCLUDE 所有字段
查询字段少、过滤条件多 ✅ 只需 INCLUDE 需要的字段
查询字段多、常变化 ❌ INCLUDE 太多字段,维护成本高
查询只取主键用于关联其他表 ✅ 只 INCLUDE 主键即可
查询频繁执行且性能瓶颈明显 ✅ 建立覆盖索引(包含所有字段)
如何判断是否应该 INCLUDE 某些字段?
你可以通过以下方式辅助判断:
✅ 使用缺失索引视图(Missing Indexes)
SELECT
migs.avg_total_user_cost * migs.avg_user_impact AS improvement_measure,
mid.equality_columns,
mid.inequality_columns,
mid.included_columns
FROM
sys.dm_db_missing_index_groups mig
INNER JOIN
sys.dm_db_missing_index_group_stats migs ON migs.group_handle = mig.index_group_handle
INNER JOIN
sys.dm_db_missing_index_details mid ON mig.index_handle = mid.index_handle
WHERE
mid.database_id = DB_ID()
ORDER BY
improvement_measure DESC;
该视图会告诉你:
- 哪些字段适合作为等值列(equality)
- 哪些字段适合放在
INCLUDE - 提升幅度有多大
总结建议
| 情况 | 是否推荐 | 说明 |
|---|---|---|
INCLUDE 不包含字段 | ❌ 一般不够高效 | 需要 Key Lookup |
INCLUDE 包含 ID(主键) | ⚠️ 有时有用 | 可用于连接其他表,但仍需回表 |
INCLUDE 包含所有查询字段 | ✅ 推荐使用 | 覆盖索引,性能最佳 |
| 字段太多或经常变动 | ❌ 避免 INCLUDE 所有字段 | 维护成本高,得不偿失 |
实用技巧
优先将 WHERE 条件中的字段放在索引键列(ON (...));
将 SELECT 中需要返回的字段放在 INCLUDE;
对于大数据类型(如 VARCHAR(MAX)、TEXT),只能放在 INCLUDE;
针对高频慢查询,建立针对性的覆盖索引;
定期分析缺失索引和实际执行计划,优化索引结构。
Key Lookup 的工作原理
我们先了解几个基本概念:
| 名称 | 含义 |
|---|---|
| Clustered Index(聚集索引) | 表数据按此索引物理排序;一张表只能有一个 |
| Nonclustered Index(非聚集索引) | 独立于表数据的索引结构,可有多个 |
| Bookmark(书签) | 在非聚集索引中指向实际数据行的指针(即主键或RID) |
✅ 示例说明
假设你有一个表 app_payback_ext,其主键是 id,并且你创建了一个非聚集索引如下:
Sql
CREATE NONCLUSTERED INDEX IX_app_payback_ext_del_city ON app_payback_ext(del, city)
此时你运行一个查询:
Sql
SELECT id, dt, complete, money1
FROM app_payback_ext
WHERE del = 0 AND city = '北京';
查询执行过程:
SQL Server 使用 IX_app_payback_ext_del_city 索引快速找到满足条件的数据行(通过 del=0 AND city='北京');
但这个索引中没有 dt, complete, money1 字段;
所以 SQL Server 使用索引中的 id(因为每个非聚集索引默认都会包含主键)回到 Clustered Index 去查找这些字段;
这个“回去找”的操作就是 Key Lookup。
📉 Key Lookup 对性能的影响
虽然 Key Lookup 是 SQL Server 自动完成的操作,但它会带来以下性能问题:
影响 说明
❌ 性能下降 每次 Key Lookup 都是一次额外的 I/O 操作
⚠️ 高频使用时显著影响 如果结果集很大,会导致大量随机读取
📈 图形执行计划显示为红色警告 表示可能是性能瓶颈
📊 在执行计划中表现为高成本 实际执行时间变长
🛠 如何避免 Key Lookup?
最有效的方法是使用 覆盖索引(Covering Index):
即:将查询中需要返回的所有字段都包含在非聚集索引中,这样就不再需要回表查找。
✅ 示例优化
原始查询:
Sql
SELECT id, dt, complete, money1
FROM app_payback_ext
WHERE del = 0 AND city = '北京';
原始索引(导致 Key Lookup):
Sql
CREATE NONCLUSTERED INDEX IX_app_payback_ext_del_city ON app_payback_ext(del, city)
优化后的索引(避免 Key Lookup):
Sql
CREATE NONCLUSTERED INDEX IX_app_payback_ext_del_city_covering
ON app_payback_ext(del, city)
INCLUDE (id, dt, complete, money1)
现在这个索引包含了查询所需要的所有字段,SQL Server 就不会再进行 Key Lookup,而是直接从非聚集索引中获取所有数据。
🔍 如何识别 Key Lookup?
你可以通过以下方式查看执行计划是否出现了 Key Lookup:
方法一:图形执行计划(SSMS)
在 SSMS 中执行查询后,点击“包括实际执行计划”按钮(⚡图标);
查看执行步骤中是否有 Key Lookup 图标;
可以看到它在整个查询成本中的占比。
方法二:XML 执行计划
在 XML 执行计划中搜索关键词:
Xml
<Lookup>
<Object ... />
</Lookup>
✅ 总结 Key Lookup 的含义和应对方法
内容 描述
🔹 Key Lookup 是什么? 当非聚集索引不包含查询所需字段时,SQL Server 回到聚集索引查找数据的过程
📉 是否会影响性能? 会,尤其是当返回行数多、Key Lookup 次数频繁时
✅ 如何避免? 创建 覆盖索引(Covering Index),将查询所需字段全部包含进索引
💡 覆盖索引建议 把 WHERE 条件字段放在索引键列,把 SELECT 字段放在 INCLUDE 中
🛠 推荐工具 使用缺失索引视图(sys.dm_db_missing_index_details)辅助发现推荐的索引结构
如果你提供具体的查询语句和索引结构,我可以帮你分析是否存在 Key Lookup,并给出优化建议。
=========================
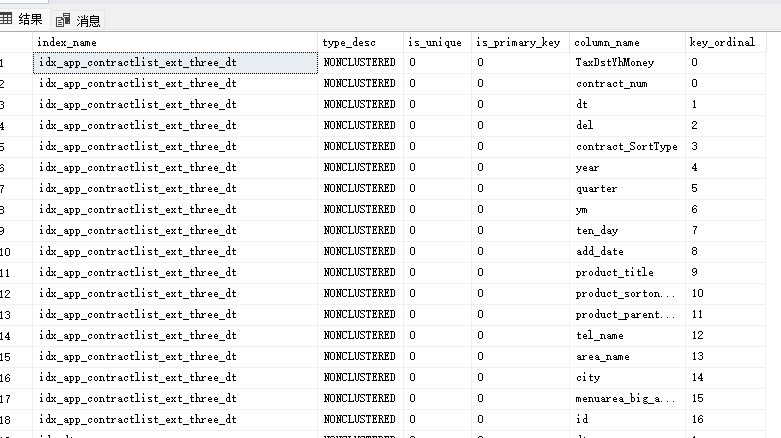
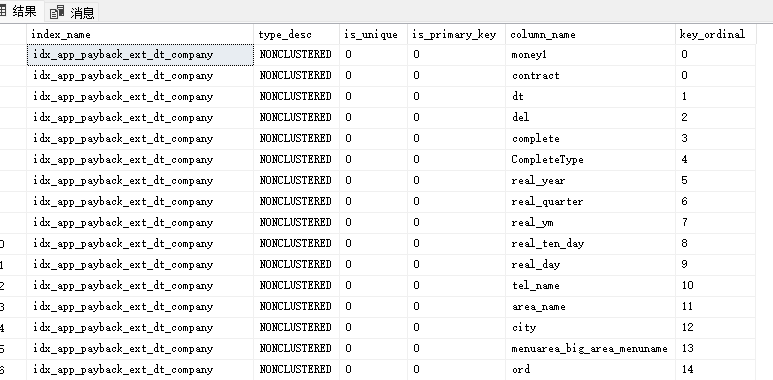
查看表的索引信息
SELECT
i.name AS index_name,
i.type_desc,
i.is_unique,
i.is_primary_key,
COL_NAME(ic.object_id, ic.column_id) AS column_name,
ic.key_ordinal
FROM sys.indexes i
JOIN sys.index_columns ic ON i.object_id = ic.object_id AND i.index_id = ic.index_id
WHERE i.object_id = OBJECT_ID('dbo.app_contractlist_ext_three')
ORDER BY i.name, ic.key_ordinal;

















 1005
1005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









