



引用论文 Large Language Models: A Survey [1]
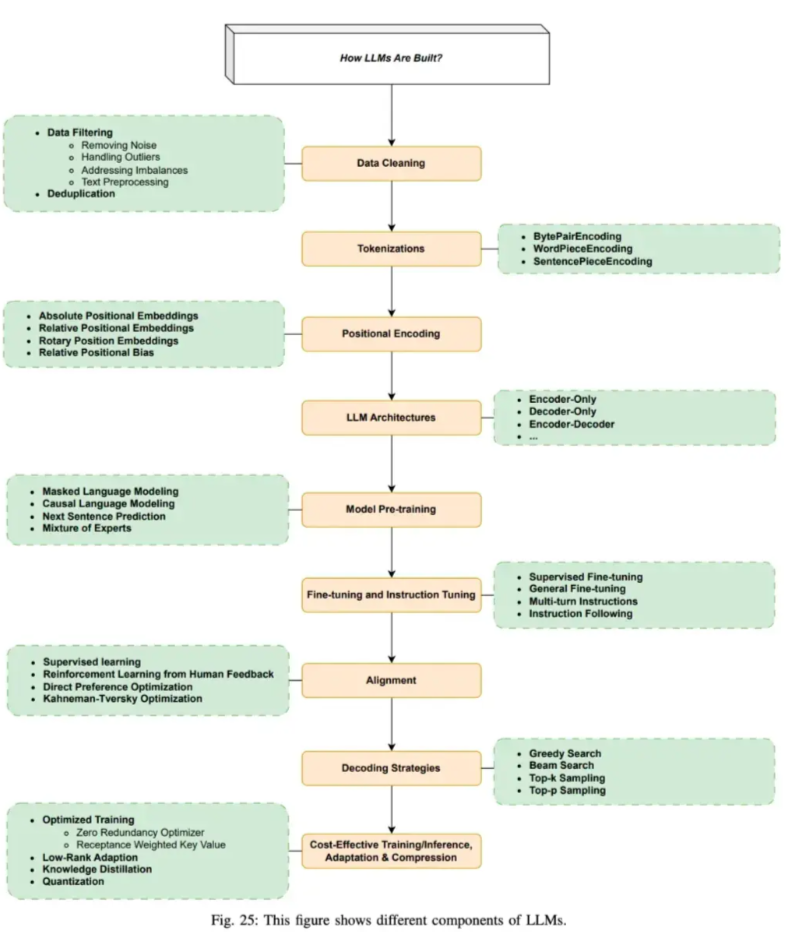
- Step 1: 准备数据和数据清洗。数据集源于网页、书籍、博客、知乎、百科等。
- Step 2: 分词,转化为模型可用于输入的token
- Step 3: 位置编码
- Step 4: 进行模型预训练,即输入文本,让模型做next token prediction等任务。

- Step 5: 通过SFT等手段微调和指令微调, 教会大模型如何对话和完成特定任务
- Step 6: 通过RLHF等手段进一步对齐人类偏好,引入人类反馈,指导模型优化方向,生成更加符合人类需求,缓解有害性和幻觉的问题
- Step 7: 通过贪心搜索等生成策略,逐步生成下一个词
- Step 8: 优化与加速训练推理过程
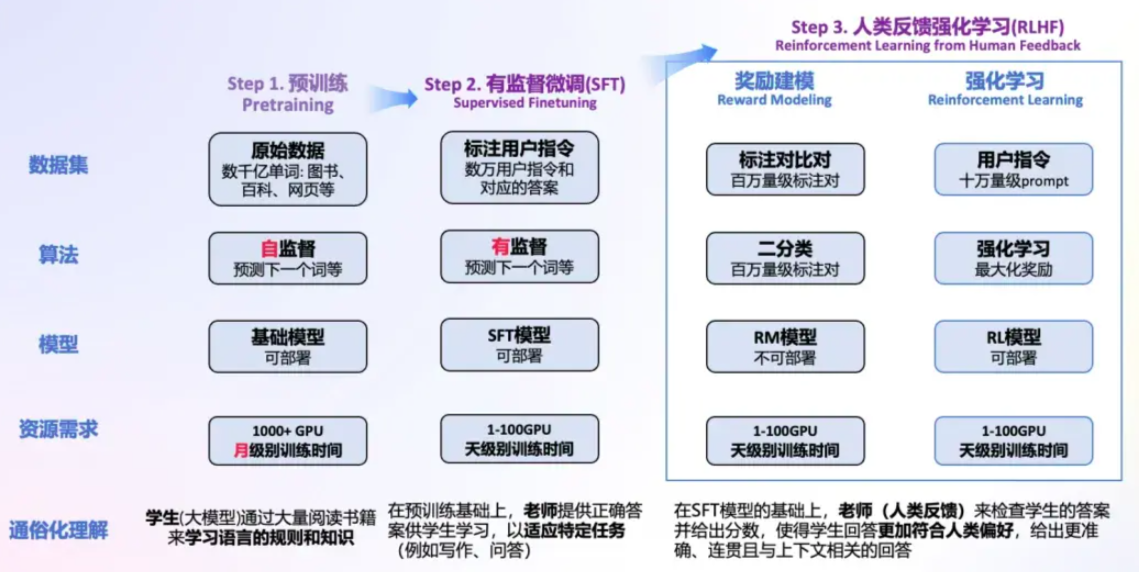
预训练,有监督微调和人类反馈强化学习
- 通用大模型: 适用于大多数任务,侧重于语言生成、上下文理解和自然语言处理,而不强调深度推理能力。此类模型通常通过对大量文本数据的训练,掌握语言规律并能够生成合适的内容,但缺乏像推理模型那样复杂的推理和决策能力。
- 推理大模型: 在传统模型基础上,强化推理、逻辑分析和决策能力。

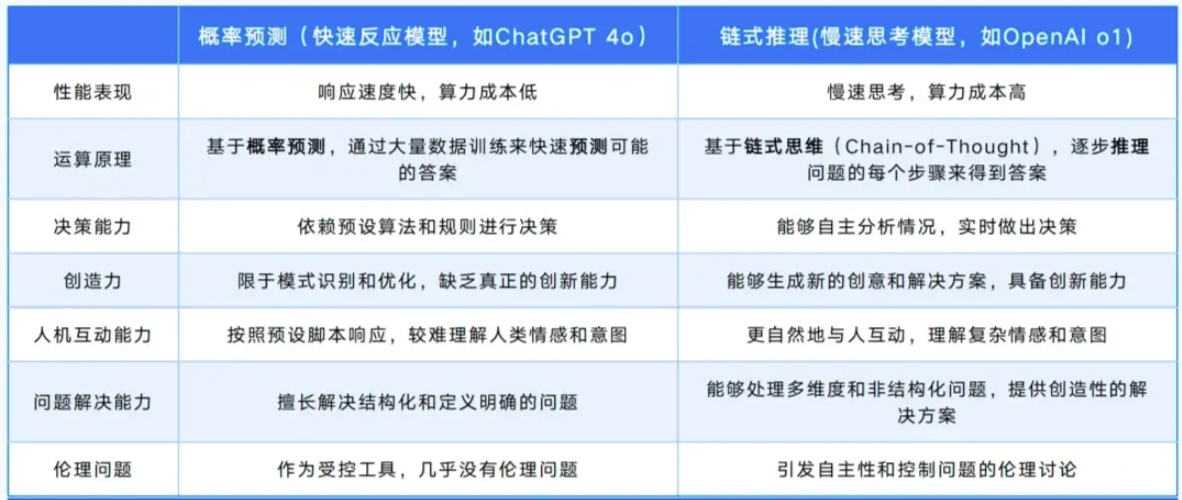
思维链(Chain of Thought, CoT)通过要求/提示模型在输出最终答案之前,显式输出中间逐步的推理步骤这一方法来增强大模型的算数、常识和推理的性能。从该角度,可以将大模型的范式分为两类: 概率预测(快速反应模型)和链式反应(慢速思考模型),前者适合快速反馈,处理即时任务,后者通过推理解决复杂问题。
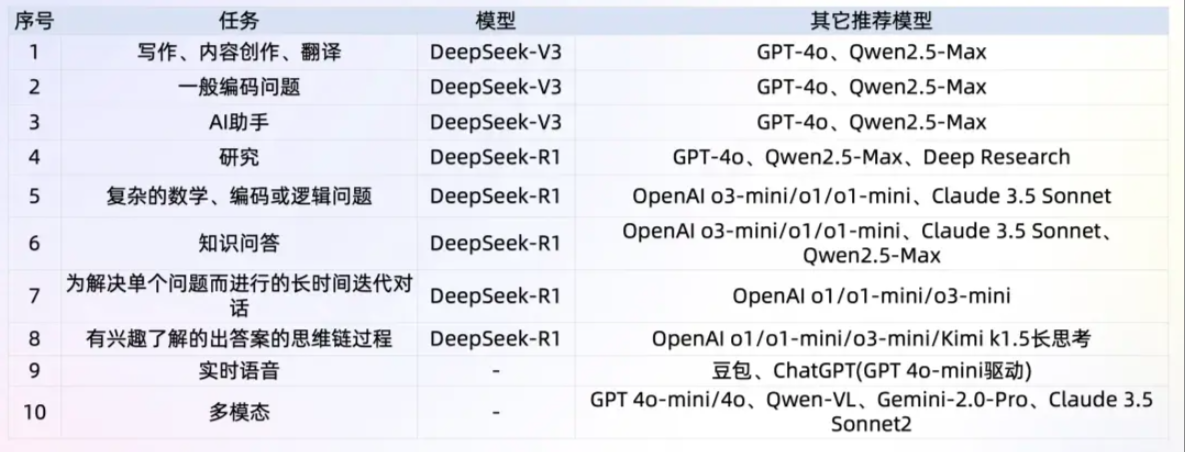
 DeepSeek可以做什么
DeepSeek可以做什么

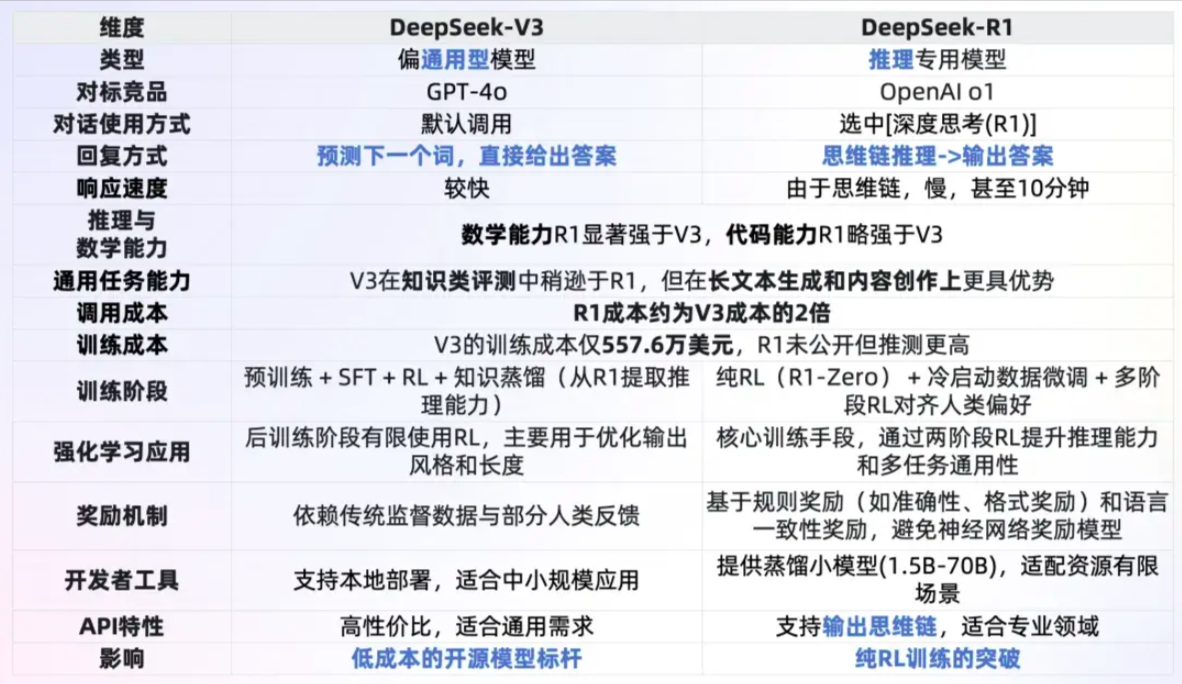
DeepSeekV3与DeepSeek-R1的对比
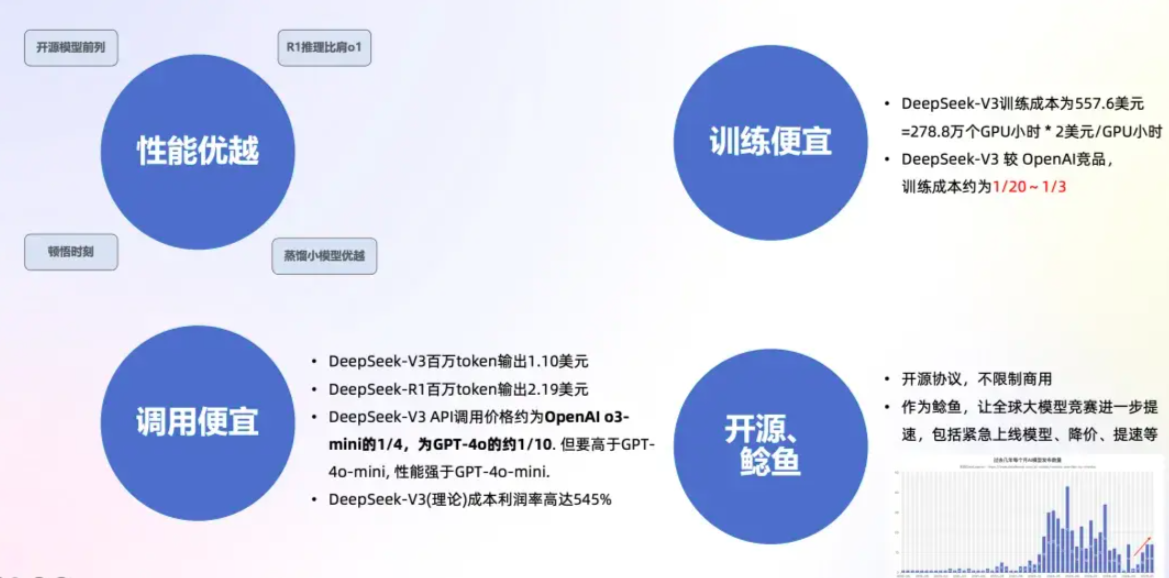
性能优越
顿悟(Aha)时刻: 单纯的RL(没有显式地提供CoT数据,而是告诉模型先思考,再回答)就可以激发模型产出带有长思维链(甚至是反思)的回复的能力,在DeepSeek-R1-zero训练过程中,在某个特定阶段,模型突然学会了重新评估自己的初始方法,并为复杂问题分配更多的思考时间。这个时刻不仅标志着模型能力的质的飞跃,也是研究者们的重大发现,它展示了强化学习在培养AI自主思考和问题解决能力方面的巨大潜力。
蒸馏小模型:在R1的发布中,同时探索了如何将大模型的推理能力高效地蒸馏到小模型中,使用DeepSeek-R1生成80万条训练样本,直接对开源的小模型(如Qwen和Llama系列)进行微调,开源了方便本地部署的一众蒸馏小模型。
缓存命中: 在大模型 API 的使用场景中,用户的输入有相当比例是重复的。举例说,用户的 prompt 往往有一些重复引用的部分;再举例说,多轮对话中,每一轮都要将前几轮的内容重复输入。启用上下文硬盘缓存技术,把预计未来会重复使用的内容,缓存在分布式的硬盘阵列中。如果输入存在重复,则重复的部分只需要从缓存读取,无需计算。该技术不仅降低服务的延迟,还大幅削减最终的使用成本。
DeepSeek-R1-Zero展示了自我验证、反射和生成长CoT等功能,这标志着研究界的重要里程碑。这是第一个验证的开发研究,可以纯粹通过RL来激励的LLMs推理能力,而无需SFT,解决了CoT数据获取困难的问题。
- DeepSeekMoE: 混合专家模型,推理时,仅动态激活部分专家(37B 参数),而非全模型参数(671B 参数),减少计算负担。
- 引入无辅助损失的自然负载均衡来解决不同专家的负载均衡问题。
- 采用MLA (Multi-Head Latent Attention)架构,扩展了传统的多头注意力机制,引入潜向量(latent variables),可以动态调整注意力机制,捕捉任务中不同的隐含语义。在训练中减少内存和计算开销,在推理中降低KV缓存占用空间,把显存占用降为MHA架构的5%~13%。
- 采用多步token预测 MTP(Multi-Token Prediction)。一般LLM一次生成1个token,DeepSeek在特定场景下能同时预测多个token,来提高信号密度。一方面能够减少上下文漂移、逻辑更连贯,也能减少一些重复中间步骤,在数学、代码和文本摘要场景能提升效率。
- 采用了GRPO(Group Relative Policy Optimization)的强化学习算法。核心思想是:对于每个问题,从旧策略中采样多个输出,然后根据这些输出的奖励计算相对评分来优化新策略。跳过传统RL中与策略模型等规模的critic网络,减少开销。
- 模型结构和训练方法上: 好
- Cot:Chain of thought。将复杂的问题拆分成小步的中间逻辑,细分逻辑链条。在训练阶段,DeepSeek-R1用标注的Long CoT数据微调模型,让模型生成更清晰的推理步骤,在强化学习中用CoT设计奖励优化,增强长链推理能力,并且在此过程中观察到了模型的反思(回溯推理路径)、多路径推理(能给出多个解)、aha时刻(通过策略突破瓶颈)等自发行为。
- 拒绝采样: 当针对推理的强化学习收敛后,研究者们使用训练得到的模型进行拒绝采样,生成多个答案,然后只选择最优的答案来继续训练,生成新的监督微调(SFT)数据。这个阶段的目的是提高模型在非推理任务(如写作、角色扮演等)上的表现。
- 工程上:省
- FP8混合精度训练:引入了FP8 混合精度训练框架,相比传统的FP16 精度,数据内存占用更少,但在一些算子模块、权重中仍然保留了FP16、FP32 的精度,节省计算资源。
- 底层通信优化:专门开发了高效的跨节点全对全通信内核,优化对带宽的利用,保证数据传输效率,并能支持大规模部署。
- DualPipe跨节点通信:传统训练信息流水线会产生一些等待时间、有“流水线气泡”,DeepSeek设计了一个双重流水线,让一个计算阶段在等待数据传输时可以切换到另一批数据,充分利用空闲时间。
- 并行:对硬件的极限使用. 在系统架构层面,DeepSeek就使用了专家并行训练技术,通过将不同的专家模块分配到不同的计算设备上同时进行训练,提升了训练过程中的计算效率。并对算力做极致压缩。、
Mixture of Experts (MoE) 混合专家模型
- 核心想法: 模型的不同参数, 作为专家,针对不同的任务或者不同的数据定制化。
- 优点: 给定输入,只有部分相关的专家会被激活,使得计算量减少,但受益于丰富的定制化的知识池。
两种典型的MoE: Dense MoE VS. Sparse MoE
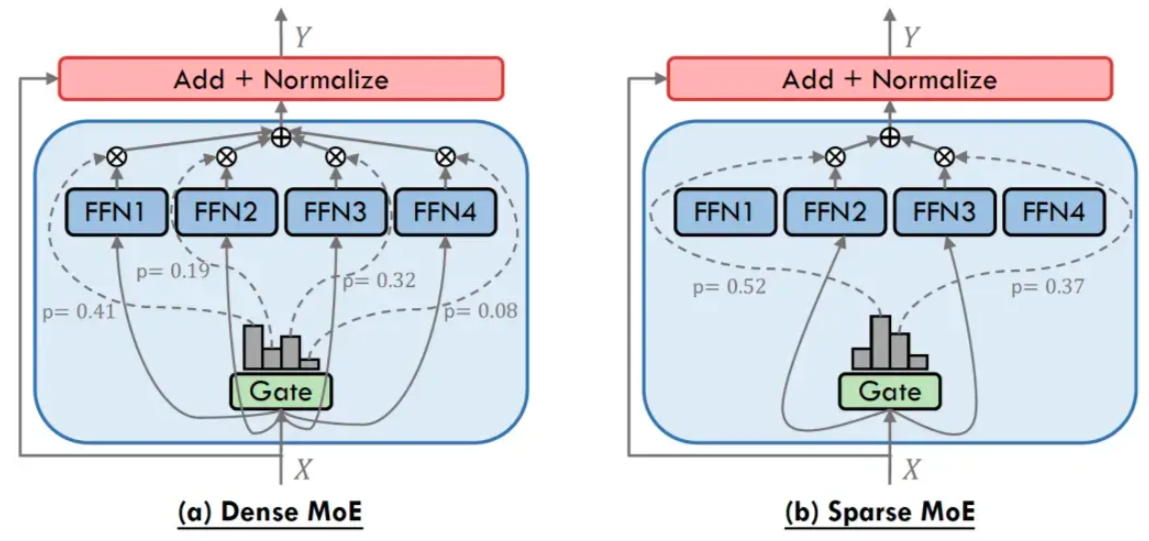
- Dense MoE: 每次前向传播,所有专家参与,计算负担大
- Sparse MoE: 在每次前向传播时只选择专家的一个子集,即Top-k专家
往往会带来负载均衡问题,即专家工作量的不均衡分布,部分专家频繁更新,其它专家很少更新,大量研究专注于解决负载均衡问题。
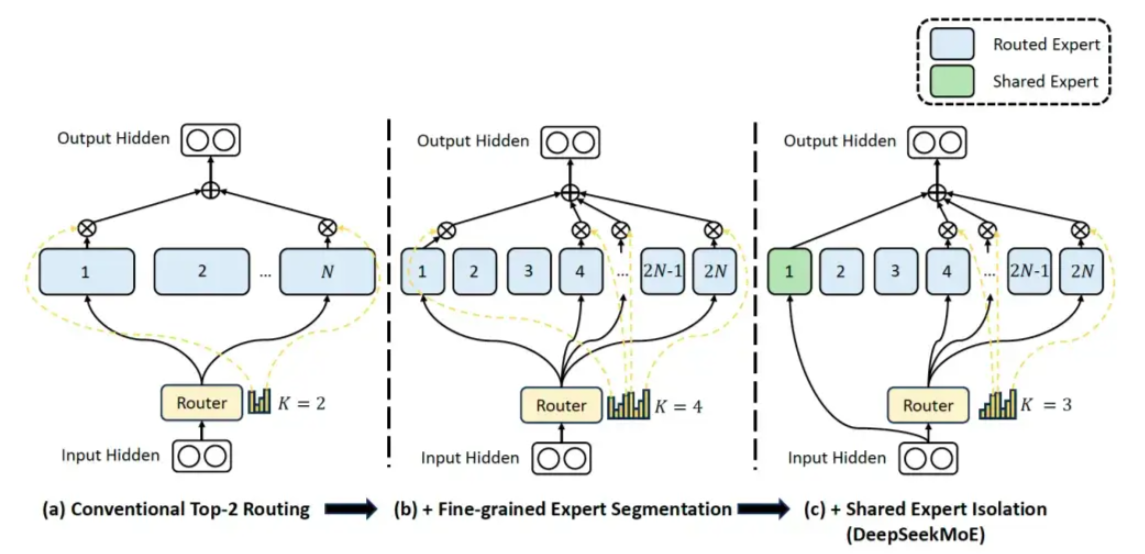
DeepSeek的MoE结构: DeepSeekMoE
DeepSeek-R1: 1个共享的专家+63个路由的专家,每个专家是标准FFN的1/4大小.
Multi-Head Latent Attention (MLA)
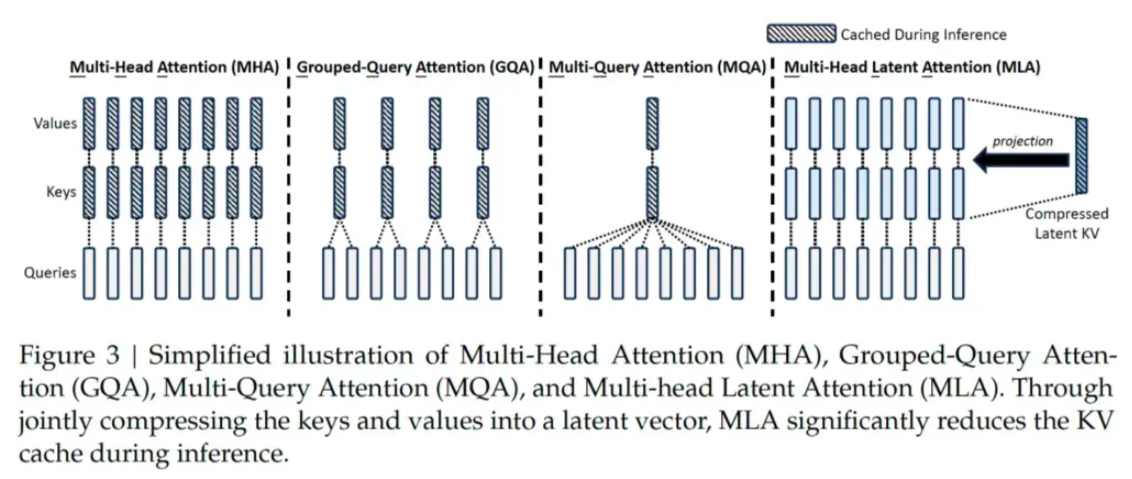
- 低秩联合压缩键值:MLA通过低秩联合压缩键值(Key-Value),将它们压缩为一个潜向量,从而大幅减少所需的缓存容量,降低计算复杂度。
- 优化键值缓存:在推理阶段,MHA需要缓存独立的键和值矩阵,会增加内存和计算,而MLA通过低秩矩阵分解技术,显著减小了存储KV的维度,从而降低了内存占用。
R1的训练范式:冷启动与多阶段RL
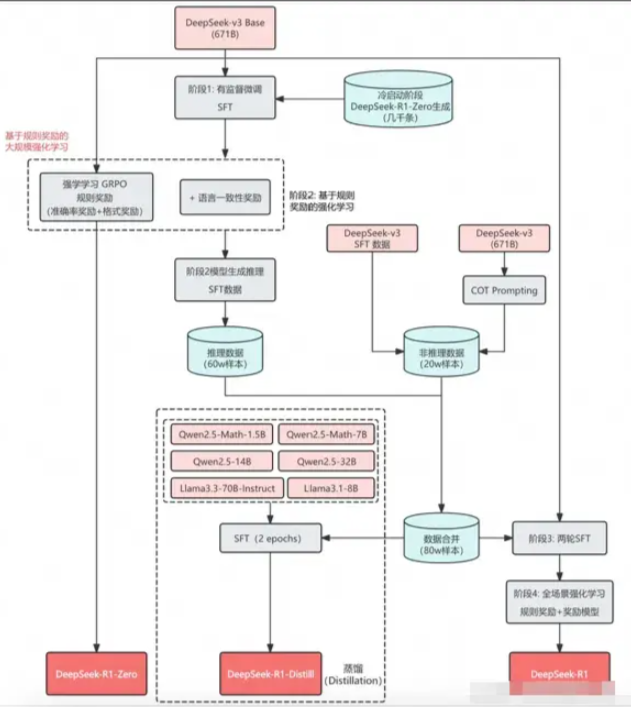
- Step 1 冷启动: 先收集一部分高质量CoT冷启动数据(约几千条),使用该数据fine-tune DeepSeek-v3-base模型,记为模型A;
- Step2 大规模RL: 使用A模型用GPRO训练,使其涌现推理能力,收敛的模型记为B;
- Step3 : 使用B模型产生高质量SFT数据,并混合DeepSeek-V3产生的其它领域的高质量数据,形成一个高质量数据集;
- Step4 再次SFT: 使用该数据集训练原始DeepSeek-v3-base模型,记为模型C;
- Step5 最终RL: 使用C重新进行Step2,但是数据集变为所有领域,收敛后的模型记为D,这个模型就是DeepSeek-R1
- Step6: 训练C模型的数据对小模型进行蒸馏,得到蒸馏的相对较小的模型。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









