




NLP2SQL的技术本质与未来方向
技术本质:NLP2SQL是自然语言理解、数据库知识图谱与代码生成的交叉领域,其核心挑战在于语义对齐(自然语言→数据库Schema)与逻辑推理(生成合法SQL)。
未来方向:
大模型驱动的端到端生成:减少中间表示,直接生成SQL。
多模态交互:支持语音、图表等多模态输入输出。
因果推理:支持反事实查询(如“如果降价10%,销量会如何变化?”)。
行业垂直化:构建医疗、金融等领域的专用模型。
NLP2SQL 技术原理详解
NLP2SQL(自然语言转SQL)是连接人类语言与数据库的桥梁,其核心目标是将非结构化的自然语言查询(如“统计北京地区2023年销售额最高的产品”)转换为可执行的结构化SQL语句。以下是其技术原理的完整拆解:
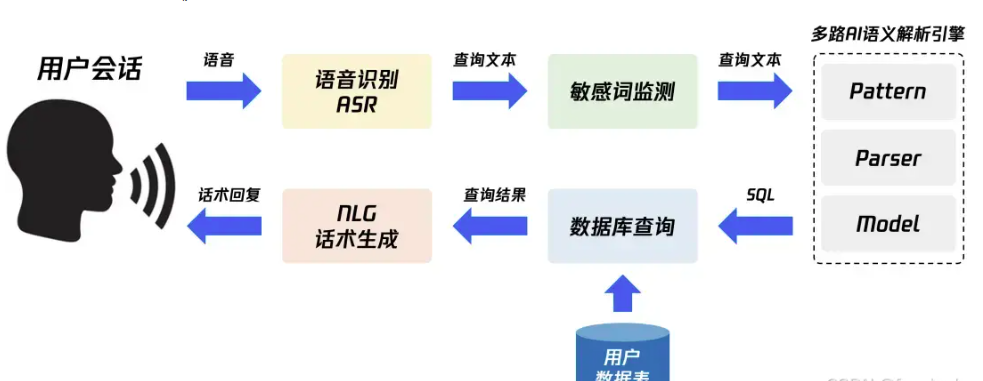
一、核心流程与模块化架构
NLP2SQL技术通常由四大核心模块构成,各模块协同完成从语义解析到SQL生成的完整链路:
1. 自然语言理解(NLU)模块
目标:将用户输入的文本解析为结构化语义表示。
关键技术:
分词与词性标注:识别“北京”、“2023年”、“销售额”等实体及词性(如时间、数值、指标)。
命名实体识别(NER):标注数据库相关实体(如“产品”→表名、字段名)。
依存句法分析:解析句子结构(如“销售额”是“最高”的修饰对象)。
意图分类:判断查询类型(如聚合查询、筛选查询、多表关联)。
2. 数据库模式映射(Schema Linking)模块
目标:将自然语言中的实体与数据库表、字段关联。
关键技术:
Schema编码:将数据库元数据(表名、字段名、数据类型)编码为向量(如BERT模型)。
实体对齐:通过相似度计算匹配自然语言与Schema(如“销售额”→sales.amount)。
上下文消歧:处理多义性(如“苹果”→水果或公司,需结合领域知识)。

. 语义解析(Semantic Parsing)模块
目标:将语义表示转换为中间逻辑形式(如抽象语法树AST)。
关键技术:
基于语法的解析:使用上下文无关文法(CFG)或组合范畴语法(CCG)生成解析树。
基于神经网络的解析:通过Seq2Seq模型(如T5、BART)直接生成逻辑形式。
混合架构:结合语法规则与神经网络(如SPARQL-to-SQL)。
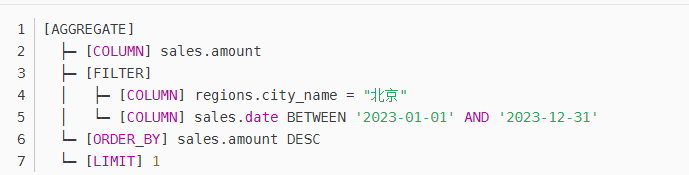
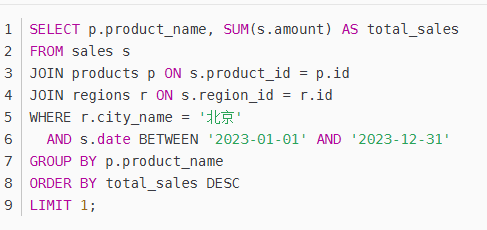
SQL生成与优化模块
目标:将逻辑形式转换为可执行的SQL语句,并优化查询效率。
关键技术:
模板匹配:基于预定义规则生成SQL(如“最大值”→MAX())。
神经网络生成:使用Transformer架构(如Codex、GPT-4)端到端生成SQL。
查询优化:改写低效SQL(如避免SELECT *、添加索引提示)。
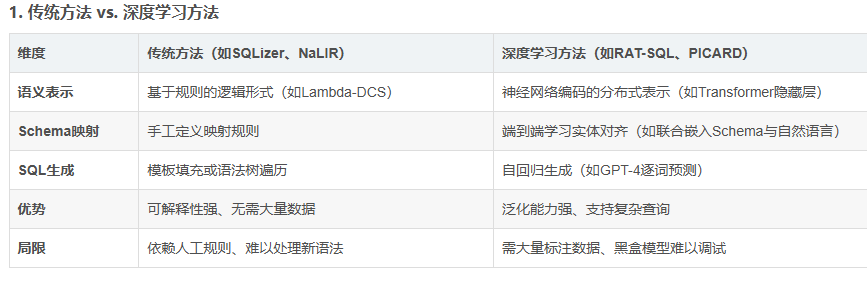
最新技术趋势
大模型预训练:利用GPT-4、Claude等大模型,通过少量领域数据微调实现高精度SQL生成。
检索增强生成(RAG):结合向量数据库(如Pinecone)检索相似历史查询,提升复杂语义处理能力。
多模态融合:支持语音、图表等多模态输入(如用户上传Excel后提问“分析销售额与广告投入的相关性”)。
主动学习:系统自动标记错误查询并请求用户修正,持续优化模型。

















 1319
1319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









