




 本文介绍如何使用ShardingSphere实现自定义分片算法,以按月分表为例,详细讲解了分表逻辑及SPI配置过程。
本文介绍如何使用ShardingSphere实现自定义分片算法,以按月分表为例,详细讲解了分表逻辑及SPI配置过程。
ShardingSphere笔记(二):自定义分片算法 — 按月分表
文章目录
一、准备
- 这里我是用的 ShardingSphere 的版本是 5.2.1
- 实现方式参考了官方的 SardingSphere 自定义分片算法的 demo,官方的demo中的分片算法是按照订单Id取模。这里我扩展为了根据时间按月分表。
- 官方提供了两种方式来定义自定义的分表算法:
- 一种方式是 SPI 的方式,也就是需要在项目的 resource/META-INF/services 目录下按照 SPI的方式注册算法类。官方demo位置: https://github.com/apache/shardingsphere/tree/master/examples/shardingsphere-jdbc-example/single-feature-example/extension-example/custom-sharding-algortihm-example/spi-based-sharding-algorithm-example/
- 另一种方式是经典方式,不需要创建services文件,但是在注册算法的时候需要写上类的全类名。官方demo位置:https://github.com/apache/shardingsphere/tree/master/examples/shardingsphere-jdbc-example/single-feature-example/extension-example/custom-sharding-algortihm-example/class-based-sharding-algorithm-example
- 我参考的方式是SPI的方式,项目中使用的是mybatis,所以参考的是里面的 mybatis 的demo
二、分表逻辑
在写分片算法之前,我们需要搞清楚,ShardingSphere 这个框架是怎么做分片的?在上一篇笔记里面我简单提到了 ShardingSphere 是通过解析Sql达到分片的目的的。
我们看一看官方是怎么做分片的:SPIBasedOrderStandardShardingAlgorithmFixture
public final class SPIBasedOrderStandardShardingAlgorithmFixture implements StandardShardingAlgorithm<Long> {
//......
@Override
public String doSharding(final Collection<String> availableTargetNames, final PreciseShardingValue<Long> shardingValue) {
for (String each : availableTargetNames) {
if (each.endsWith(shardingSuffix(shardingValue.getValue()))) {
return each;
}
}
return null;
}
private String shardingSuffix(final Long shardingValue) {
return "_" + (shardingValue % 2);
}
@Override
public Collection<String> doSharding(final Collection<String> availableTargetNames, final RangeShardingValue<Long> shardingValue) {
return availableTargetNames;
}
}
可以看到,官方的demo中 继承了 StandardShardingAlgorithm 并且实现了两个方法 :
- String doSharding(Collection<String>, PreciseShardingValue<Long>)
- Collection<String> doSharding(Collection<String> , RangeShardingValue<Long>)
这两个方法就是分表逻辑了:
- 这里类的泛型是 Long 的原因就是官方文档中的分表列是订单号,订单号类型就是Long,就是说这个算法你要应用到数据表的哪一个字段,那么这个泛型的类型就是这个字段的类型。
- 第一个方法是精确匹配,可以发现 PreciseShardingValue 只有一个获取值的方法 getValue() ,意味着这个方法是来匹配到那些精确匹配的sql, 比如说 select * from t_order where order_id = 1。 根据 order_id 做分片,那么ShardingSphere在做分片路由的时候就会调用第一个方法,你通过 PreciseShardingValue.getValue() 就可以拿到等于号后面的值。
- 第二个方法是范围匹配, RangeShardingValue 有一个 getValueRange() 方法,返回的对象提供了lowerEndpoint() 和 upperEndpoint() 两个方法。比如你调用 select * from t_order where order_id > 1 and order_id < 10, 那么就会调用该方法来进行路由,这里的lowerEndPoint 就是1, uperEndpoint 就是10。
- 精确匹配的方法返回了一个结果,范围匹配的返回了一个集合,原因就是一条记录不能可能存到两个表中,第一个方法就是来精确定位一条记录应该被路由到哪一个表。
- 该算法不仅仅是可以用在路由表,也可以用在路由数据库。
- 当它作为数据库分片算法的时候,方法中的第一个参数是可用的数据源名称列表。
- 当它作为数据表分表算法的时候第一个参数是可用的数据表列表。
- 因为ShardingSphere本身就是做 分库+分表 的框架,所以事实上 分库算法 + 分表算法 才算的上是完整的分片算法。如果我们配置了多个数据源,并且只配置了分表算法而没有做分库算法那么shardingsphere就只会走配置的第一个数据源。
通过上面的解释,也就能明白官方的 demo 分表算法到底是怎么做的分表的了。这个demo逻辑非常简单,就是把数据路由到了两个表中,一个是 table_name_0, 一个是 table_name_1。 因为他分表的时候就只是很简单的对2取模。当id是2的倍数时路由到后缀名为 0 的表,当id不是2的倍数时路由到 1 的表。
通过配置文件我们也能看到,它确实只分了两个表。
# 这里只配置了一个数据源和两张表,分别是 ds.t_order_0 和 ds.t_order_1, 根据 order_id 分表
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds.t_order_$->{0..1}
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=t-order-spi-based
# 这里只配置了一个数据源和两张表,分别是 ds.t_order_item_0 和 ds.t_order_item_1, 根据 order_id 分表
spring.shardingsphere.rules.sharding.tables.t_order_item.actual-data-nodes=ds.t_order_item_$->{0..1}
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-column=order_id
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-algorithm-name=t-order-item-spi-based
另外,上面的demo是摘自 spi 方式的代码,经典模式的逻辑比这个多了个取模数的配置,而不是像上面一样写死为了2。有兴趣的可以去看看,基本逻辑是一致的。
三、自定义分片算法步骤(以按月分表为例)
假设我们的数据表名称为 test_data。 表中的时间列为 acquisition_time。根据该列作为分片的列。
1. SPI 方式
- 确定需要分表的字段和字段类型。
- 继承 StandardShardingAlgorithm, 实现其中的两个分片方法。实现 getType() 方法,返回该算法的 SPI 名称,在配置文件中配置算法的时候需要用到该名称。
- 通过SPI的方式注册该算法
- 在配置文件中配置该算法
2. 经典模式
- 确定需要分表的字段和字段类型。
- 继承 StandardShardingAlgorithm, 实现其中的两个分片方法。
- 在配置文件中配置该算法
四、按月分表算法(SPI方式)
经典模式和SPI方式配置方式只有在配置文件中的配置方式有一点点不一样。
在这之前需要引入 Shardingsphere的依赖,因为我这里是Springboot项目,直接引入的 starter.
另外
- 因为需要连接mysql,引入了 mysql-connector-java
- 使用了mybatis访问数据库,引入了 mybatis-plus-boot-starter
- 用到了一些工具类,引入了 hutool-all
- 用到了Hikari连接池,引入了 jdbc-starter
<properties>
<maven.compiler.source>14</maven.compiler.source>
<maven.compiler.target>14</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<shardingsphere-jdbc.version>5.2.1</shardingsphere-jdbc.version>
<snakeyaml.version>1.33</snakeyaml.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>${shardingsphere-jdbc.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.9</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.2</version>
</dependency>
</dependencies>
1. 确定需要分表的字段和字段类型
假设我们的数据表名称为 test_data。 表中的时间列为 acquisition_time。该列作为分片的列。
2. 继承 StandardShardingAlgorithm, 实现分片方法
/**
* 按月分表的 Sharding 算法
*
* @author wangp
*/
@Getter
@Slf4j
public class HisDataMonthShardingAlgorithm implements StandardShardingAlgorithm<Date> {
private final ThreadLocal<SimpleDateFormat> formatThreadLocal = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyyMM"));
private Properties props;
/**
* 设置该参数的原因是,如果在范围查找的时候我们没有设置最小值,比如下面的查询
* where acquisition_time < '2022-08-11 00:00:00'
* 这个时候范围查找就只有上限而没有下限,这时候就需要有一个下限值兜底,不能一致遍历下去
*/
private Date tableLowerDate;
/**
* 在配置文件中配置算法的时候会配置 props 参数,框架会将props中的配置放在 properties 参数中,并且初始化算法的时候被调用
*
* @param properties properties
*/
@Override
public void init(Properties properties) {
this.props = properties;
String autoCreateTableLowerDate = properties.getProperty("auto-create-table-lower");
try {
this.tableLowerDate = formatThreadLocal.get().parse(autoCreateTableLowerDate);
} catch (Exception e) {
log.error("parse auto-create table lower date failed: {}, use default date 2018-01", e.getMessage());
try {
this.tableLowerDate = formatThreadLocal.get().parse("201801");
} catch (ParseException ignored) {
}
}
}
/**
* 精确路由算法
*
* @param availableTargetNames 可用的表列表(配置文件中配置的 actual-data-nodes会被解析成 列表被传递过来)
* @param shardingValue 精确的值
* @return 结果表
*/
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Date> shardingValue) {
Date value = shardingValue.getValue();
// 根据精确值获取路由表
String actuallyTableName = shardingValue.getLogicTableName() + shardingSuffix(value);
if (availableTargetNames.contains(actuallyTableName)) {
return actuallyTableName;
}
return null;
}
/**
* 范围路由算法
*
* @param availableTargetNames 可用的表列表(配置文件中配置的 actual-data-nodes会被解析成 列表被传递过来)
* @param shardingValue 值范围
* @return 路由后的结果表
*/
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Date> shardingValue) {
// 获取到范围查找的最小值,如果条件中没有最小值设置为 tableLowerDate
Date rangeLowerDate;
if (shardingValue.getValueRange().hasLowerBound()) {
rangeLowerDate = shardingValue.getValueRange().lowerEndpoint();
} else {
rangeLowerDate = tableLowerDate;
}
// 获取到范围查找的最大值,如果没有配置最大值,设置为当前时间 + 1 月
// 这里需要注意,你的项目里面这样做是否合理
Date rangeUpperDate;
if (shardingValue.getValueRange().hasUpperBound()) {
rangeUpperDate = shardingValue.getValueRange().upperEndpoint();
} else {
// 往后延一个月
rangeUpperDate = DateUtil.offsetMonth(new Date(), 1);
}
rangeUpperDate = DateUtil.endOfMonth(rangeUpperDate);
List<String> tableNames = new ArrayList<>();
// 过滤那些存在的表
while (rangeLowerDate.before(rangeUpperDate)) {
String actuallyTableName = shardingValue.getLogicTableName() + shardingSuffix(rangeLowerDate);
if (availableTargetNames.contains(actuallyTableName)) {
tableNames.add(actuallyTableName);
}
rangeLowerDate = DateUtil.offsetMonth(rangeLowerDate, 1);
}
return tableNames;
}
/**
* sharding 表后缀 _yyyyMM
*/
private String shardingSuffix(Date shardingValue) {
return "_" + formatThreadLocal.get().format(shardingValue);
}
/**
* SPI方式的 SPI名称,配置文件中配置的时候需要用到
*/
@Override
public String getType() {
return "HIS_DATA_SPI_BASED";
}
}
具体的算法思路都已经写在上面的注释中了,不再赘述。需要注意的是在范围查找的时候我对于没有最大值和没有最小值的处理方式,大家需要结合自己项目中的实际情况灵活处理。
3. 通过SPI的方式注册该算法
在 resources 文件夹下创建文件夹 META-INF/services。 在该文件夹下创建文件 org.apache.shardingsphere.sharding.spi.ShardingAlgorithm, 文件内写上我们自定义的分片算法。
org.example.sharding.HisDataMonthShardingAlgorithm
这就是Java里面最基本的SPI配置,不明白为什么配置的可以搜索一下JavaSPI, 如下图
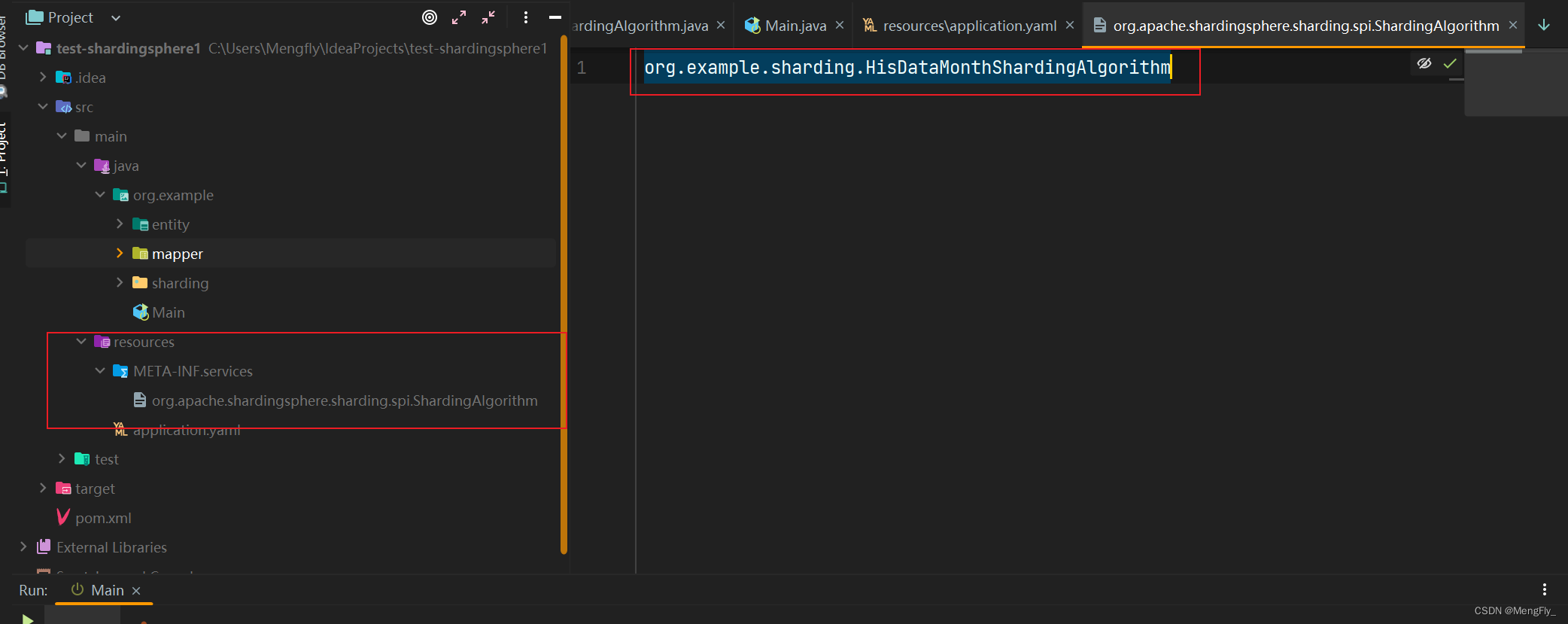
4. 在配置文件中配置该算法
官方文档使用的 properties 配置文件夹,我比较习惯使用 yaml来配置。
spring:
shardingsphere:
# 配置显示sql,这项配置在测试的时候非常有用,建议打开,可以看到路由结果,生产环境可以关掉
props:
sql-show: true
datasource:
# 配置数据源列表,多个数据源使用逗号分割
names: ds1
# 第一个数据源,因为我们的按月分表算法只实现了按表的分片算法,所以没有配置多个数据库
# 如果需要配置多个数据源,就需要实现数据库的分库策略。
ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost/test_sharding_db?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&allowMultiQueries=true
username: root
password: 123456
rules:
sharding:
tables:
# 需要分表的逻辑表名, 如果需要配置多个数据表,按照这个规则配置就可以
test_data:
# 表的真实表列表(需要注意这里的表都应该存在,否则就有可能出现我第一篇文章里面提到的 NPE 异常)
actual-data-nodes: ds1.test_data_20220${1..9}, ds1.test_data_2022${10..12}
# 分片策略配置
table-strategy:
standard:
# 分片算法是 his_month_sharding, 这个名称是在下面配置的
sharding-algorithm-name: his_month_sharding
# 分片列是 acquisition_time, 需要注意的是,分表算法的数据类型一定要和这个分片的列数据类型一致
sharding-column: acquisition_time
# 配置分片算法
sharding-algorithms:
# 分片算法名称
his_month_sharding:
# 分片算法类型,这个type就是我们的分片算法实现类中 getType() 的返回值,SPI适用于这种方式
type: HIS_DATA_SPI_BASED
五、 测试
至此,数据库分库分表都已经配置完成了,下面就是进行测试了。我这里准备了2022年一年的表,如下:
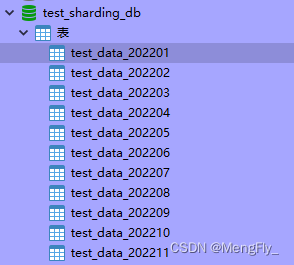
1. 精确查找
我们指定查询的数据时间为6月份
Java代码
LambdaQueryWrapper<TestData> queryWrapper = new LambdaQueryWrapper<>(TestData.class)
.eq(TestData::getAcquisitionTime, DateUtil.parseDateTime("2022-06-07 00:00:00"));
mapper.selectCount(queryWrapper);
查询的逻辑 sql:
2022-11-21 21:33:47.144 INFO 3056 --- [ main] ShardingSphere-SQL : Logic SQL:
SELECT COUNT( * ) FROM test_data WHERE (acquisition_time = ?)
查询的实际sql:
2022-11-21 21:33:47.145 INFO 3056 --- [ main] ShardingSphere-SQL : Actual SQL: ds1 :::
SELECT COUNT( * ) FROM test_data_202206 WHERE (acquisition_time = ?) ::: [2022-06-07 00:00:00.0]
可以看到,acquisition_time = 2022-06-07 00:00:00 的sql被路由到了 test_data_202206 这个表上。
2. 范围查找(有上限和有下限)
Java代码
queryWrapper = new LambdaQueryWrapper<>(TestData.class)
.ge(TestData::getAcquisitionTime, DateUtil.parseDateTime("2022-04-07 00:00:00"))
.le(TestData::getAcquisitionTime, DateUtil.parseDateTime("2022-08-07 00:00:00"));
mapper.selectCount(queryWrapper);
查询的逻辑sql:
2022-11-21 22:03:13.995 INFO 10536 --- [ main] ShardingSphere-SQL : Logic SQL:
SELECT COUNT( * ) FROM test_data WHERE (acquisition_time >= ? AND acquisition_time <= ?)
查询的实际sql
2022-11-21 22:03:13.995 INFO 10536 --- [ main] ShardingSphere-SQL : Actual SQL: ds1 :::
SELECT COUNT( * ) FROM test_data_202204
WHERE (acquisition_time >= ? AND acquisition_time <= ?) UNION ALL SELECT COUNT( * ) FROM test_data_202205
WHERE (acquisition_time >= ? AND acquisition_time <= ?) UNION ALL SELECT COUNT( * ) FROM test_data_202206
WHERE (acquisition_time >= ? AND acquisition_time <= ?) UNION ALL SELECT COUNT( * ) FROM test_data_202207
WHERE (acquisition_time >= ? AND acquisition_time <= ?) UNION ALL SELECT COUNT( * ) FROM test_data_202208
WHERE (acquisition_time >= ? AND acquisition_time <= ?)
::: [2022-04-07 00:00:00.0, 2022-08-07 00:00:00.0, 2022-04-07 00:00:00.0, 2022-08-07 00:00:00.0, 2022-04-07 00:00:00.0, 2022-08-07 00:00:00.0, 2022-04-07 00:00:00.0, 2022-08-07 00:00:00.0, 2022-04-07 00:00:00.0, 2022-08-07 00:00:00.0]
可以看到 acquisition_time >= 2022-04-07 00:00:00 and acquisition_time <= 2022-08-07 00:00:00 的sql被路由到了 05、06、07、08 这四个月的表上。
3. 范围查找(有上限和无下限)
Java代码
queryWrapper = new LambdaQueryWrapper<>(TestData.class)
.le(TestData::getAcquisitionTime, DateUtil.parseDateTime("2022-04-07 00:00:00"));
mapper.selectCount(queryWrapper);
查询的逻辑sql:
2022-11-21 22:09:42.710 INFO 15912 --- [ main] ShardingSphere-SQL :
Logic SQL: SELECT COUNT( * ) FROM test_data WHERE (acquisition_time <= ?)
查询的实际sql
2022-11-21 22:09:42.710 INFO 15912 --- [ main] ShardingSphere-SQL : Actual SQL: ds1 :::
SELECT COUNT( * ) FROM test_data_202201
WHERE (acquisition_time <= ?) UNION ALL SELECT COUNT( * ) FROM test_data_202202
WHERE (acquisition_time <= ?) UNION ALL SELECT COUNT( * ) FROM test_data_202203
WHERE (acquisition_time <= ?) UNION ALL SELECT COUNT( * ) FROM test_data_202204
WHERE (acquisition_time <= ?)
::: [2022-04-07 00:00:00.0, 2022-04-07 00:00:00.0, 2022-04-07 00:00:00.0, 2022-04-07 00:00:00.0]
4. 范围查找(无上限和有下限)
Java代码
queryWrapper = new LambdaQueryWrapper<>(TestData.class)
.ge(TestData::getAcquisitionTime, DateUtil.parseDateTime("2022-08-07 00:00:00"));
mapper.selectCount(queryWrapper);
查询的逻辑sql:
2022-11-21 22:09:42.691 INFO 15912 --- [ main] ShardingSphere-SQL : Logic SQL:
SELECT COUNT( * ) FROM test_data WHERE (acquisition_time >= ?)
查询的实际sql
2022-11-21 22:09:42.692 INFO 15912 --- [ main] ShardingSphere-SQL : Actual SQL: ds1 :::
SELECT COUNT( * ) FROM test_data_202208
WHERE (acquisition_time >= ?) UNION ALL SELECT COUNT( * ) FROM test_data_202209
WHERE (acquisition_time >= ?) UNION ALL SELECT COUNT( * ) FROM test_data_202210
WHERE (acquisition_time >= ?) UNION ALL SELECT COUNT( * ) FROM test_data_202211
WHERE (acquisition_time >= ?) UNION ALL SELECT COUNT( * ) FROM test_data_202212
WHERE (acquisition_time >= ?)
::: [2022-08-07 00:00:00.0, 2022-08-07 00:00:00.0, 2022-08-07 00:00:00.0, 2022-08-07 00:00:00.0, 2022-08-07 00:00:00.0]
5. 范围查找(无筛选条件)
Java 代码
mapper.selectCount(null);
查询的逻辑sql:
2022-11-21 22:18:45.082 INFO 12052 --- [ main] ShardingSphere-SQL : Logic SQL:
SELECT COUNT( * ) FROM test_data
查询的实际sql
2022-11-21 22:18:45.083 INFO 12052 --- [ main] ShardingSphere-SQL : Actual SQL: ds1 :::
SELECT COUNT( * ) FROM test_data_202201 UNION ALL
SELECT COUNT( * ) FROM test_data_202202 UNION ALL
SELECT COUNT( * ) FROM test_data_202203 UNION ALL
SELECT COUNT( * ) FROM test_data_202204 UNION ALL
SELECT COUNT( * ) FROM test_data_202205 UNION ALL
SELECT COUNT( * ) FROM test_data_202206 UNION ALL
SELECT COUNT( * ) FROM test_data_202207 UNION ALL
SELECT COUNT( * ) FROM test_data_202208 UNION ALL
SELECT COUNT( * ) FROM test_data_202209 UNION ALL
SELECT COUNT( * ) FROM test_data_202210 UNION ALL
SELECT COUNT( * ) FROM test_data_202211 UNION ALL
SELECT COUNT( * ) FROM test_data_202212
六、总结
至此,按月分表就算是完成了,通过上面的测试可以看到,如果没有筛选条件将会导致全表查询。所以如果我们选择了数据库分表,那么我们在查询数据的时候就一定要把分片的列加入到查询条件中,上面的测试中虽然看上去还只有一个sql,但是如果我们使用了join语句查询,甚至可能出现笛卡尔积的查询次数,举个例子,我们有两个分表的数据表,t1(分了100张表), t2(分了100张表) ,假入我们的查询语句没有使用分片列作为查询条件将会导致 100x100=10000次数据库查询 ,这样的效率是特别低的。
最好的方法是
select [columns...] from t1 left join t2 on t1.c1 = t2.c2 where [t1,t2].[c1,c2] [=,>,<,>=,>=] [condition]
c1 和 c2 都是 表 t1和t2 的分表列,并且他们在查询条件中,这样查询的次数只取决于这两个表符合该条件的表最大的数量,而不会出现笛卡尔积查询次数的问题。
另外,我们虽然实现了分表算法,还记得我们上一篇文章里面提到的,真实表必须存在这个问题吗?但是一般情况下,按月分表并不像取模分表那样可以提前建好表,如果一次性将未来的表都创建好的话就会存在很多的空表,如果我们想要不修改代码,就必须:1. 要么提前创建好未来的数据库表。2. 要么能在框架运行过程中自动创建不存在的未来表。
所以,我在项目实践的时候采用的是第二种方式,即在运行过程中动态创建表。在这个过程中也踩了很多的坑,下面的文章我将介绍怎么在分表算法运行过程中动态创建表。

















 1514
1514









 到【灌水乐园】发言
到【灌水乐园】发言







