



很长时间没有更新公众号的内容了,最近一段时间一直在通过各种渠道了解大型语言模型,重点关注其在各个应用领域的使用情况,以此来了解其应用的边界。
在近两个月的学习过程中,我对所学内容进行了总结,通过这些总结各位可以详细了解大模型的能力。各行各业的人员可以根据这些信息,总结出自己的应用场景。
内容简介
主要的使用场景包括如下列表,每个场景都会举一到两个例子来详细说明:
-
信息抽取:非结构化的告警数据结构化
-
文本释义:将专业的文档内容转义为小学生能够读懂的表达方式
-
内容生成:
-
数据中心面试SRE工程师题目准备
-
创业想法脑力激荡-虚拟现实和健身
-
-
内容归纳总结:将一段比较长的文字内容,进行精减表达
-
内容格式化:非结构化数据结构化,并生成可下载csv文档
-
编程应用
-
通过需求描述,制作一个简单的html页面,并生成代码
-
自然语言转SQL
-
从告警内容中抽取信息,并给出python代码
-
-
翻译:略
-
自然语言:
-
电商评论内容情感分析
-
告警内容分类
-
-
知识获取:告警分类方法有哪些纬度
-
图像生成:告警趋势图生成
信息抽取
大型语言模型广泛应用于信息抽取,能从非结构化文本中理解并提取关键信息。例如,金融新闻的重要数据、医疗记录的病史症状、法律文档的关键条款等。这大大提高了处理大量文本信息的效率。
下面的应用案例是智能运维领域从告警信息中自动抽取关键信息:
假设我们有以下的告警内容,通常需要仔细阅读所有内容才能找到我们需要的信息。这些信息都是非结构化的,因此,系统在处理时,获取关键信息可能会比较麻烦。
【次要告警】110.230.101.09[设备名:hp_server01],哈尔滨培训中心Timed out while waiting for response,发生时间:09/11/2020 09:36:21,【核心应用团队.网络支持团队.运营数据中心】【事件ID:1234565789000】接下来,让我们看一下如何通过大型语言模型方便地对上述文本警告内容进行信息提取和结构化:
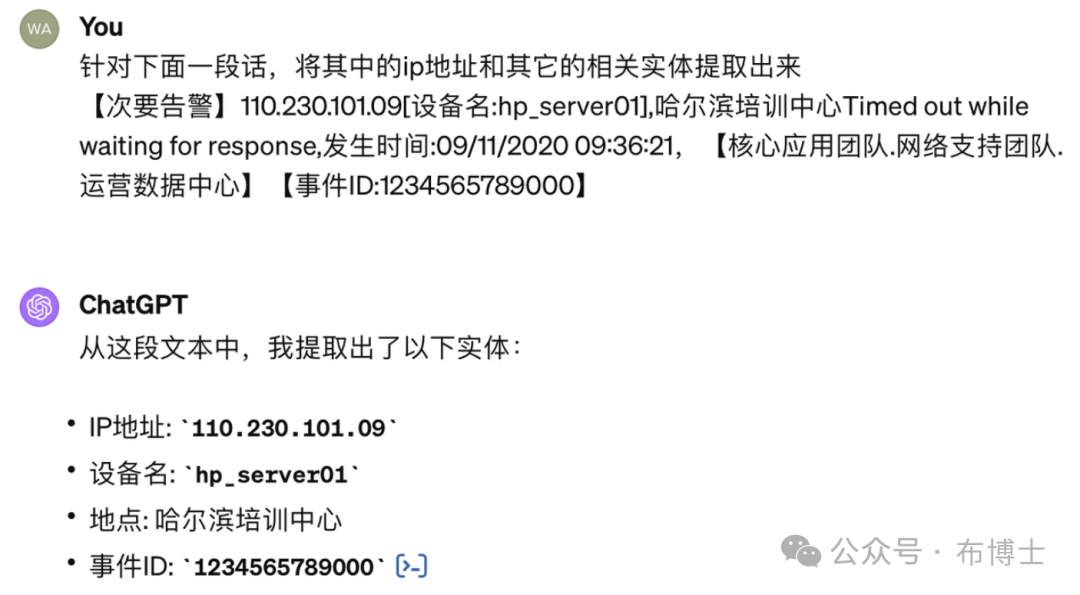
针对上面告警其实还包括所在的团队信息,在这里没有抽取出来,我们再向chatGPT下指令,看一下最终的处理结果:

是不是很完美,我们所需要的信息都提取出来了。
注意:大型语言模型本质上还是一种自然语言模型,由于其拥有大量的语料库进行学习,所以在实体命名和实体提取上有很高的准确性(大多数场景下已经超过人类)。在实际应用中,考虑到数据安全和大模型的计算成本,建议的做法是让大型语言模型处理少量的数据(这可以解决人工标注成本高、耗时长、效率低的问题),生成供算法训练用的已标注数据。然后,由本地的算法团队使用像Bert这样的自然语言处理模型进行训练,以生成一个较好的、可在本地部署的算法。
文本释义
大型语言模型在文本释义方面表现出色,能理解复杂语义,各种上下文中提供清晰解释。如在教育、科技领域解释复杂概念,帮助理解记忆;在日常生活中,解释流行语,使人们更好理解网络文化。这种能力使其成为强大的教育和科普工具。
下面我们介绍一个关于木星说明的例子,这段文本的内容比较专业,现在想要将这段专业的陈述换一种小学二年级的学生能够理解的表达方式。

文本释义之后从语言的表达上会更白话和通俗易懂一些,但又没有缺失要表达的内容。
注意:在许多情况下,如政策、法规、科研、产品推广等专业文档普及全民时,最重要的问题往往是需要适应不同的人群。不同的人群有不同的接受能力,这时可以通过像chatgpt这样的大模型来针对不同层次的人员进行解读,会取得更好的效果。
内容生成
大型语言模型广泛应用于内容生成,如文章、报告等。它们可创新生成或基于现有内容改写。示例包括新闻概要,社交媒体帖子,学习材料。使用这些模型可以提高效率,节省人力,并提供多样化、个性化的内容。随着学习和训练,其生成能力将不断增强。
示例 1 :数据中心面试SRE工程师题目准备
现在数据中心想要面试一批SRE工程师,但是面试官也没有这方面的经验,需要从哪些方面来了解SRE工程师的能力,且看下面一段示例:

示例 2 :创业想法脑力激荡-虚拟现实和健身

注意:像chatGPT这样的大型模型储存了现实世界中关于各种问题的所有正面和负面信息。它就像一个超大的记忆库,不会忘记任何数据。当我们寻求对某个话题的多元思考时,它可以把所有相关的知识点都呈现出来供创业者思考。这是即使召集一群员工也很难做到的。
内容归纳总结
大型语言模型在内容归纳总结方面表现出色,能够对各种类型的文本进行深度理解和高效总结。无论是新闻报道、学术研究,还是会议记录,它都能提取关键信息,形成简洁明了的总结。这种能力不仅可以提高我们处理大量信息的效率,也可以帮助我们更好地理解和记忆内容。
如下一段内容在notion中(notion使用了chatGPT4)的一段话描述内容较多,会占用读者过多的时间,因此让其进行浓缩之后的效果。
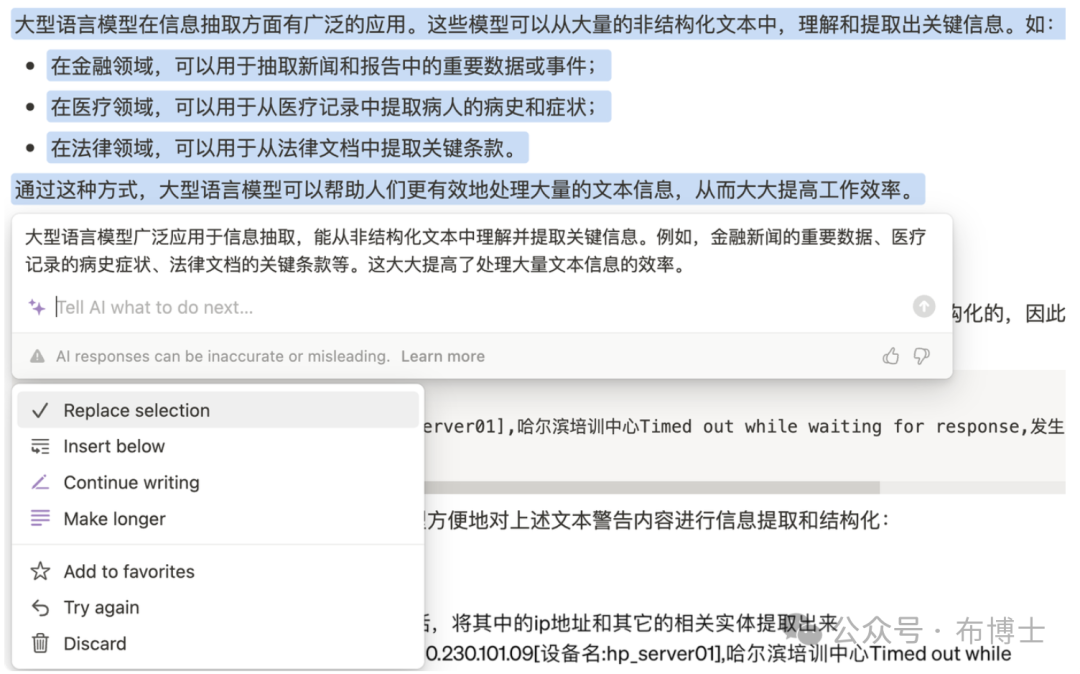
注意:在实际生活中,我们经常遇到长篇大论,如果不通读可能就很难理解其中的重点。这时,我们可以通过使用大型模型来完成这项工作,它能有效地从文章中提取关键信息,从而大大节省我们的时间,提高工作效率。
内容格式化
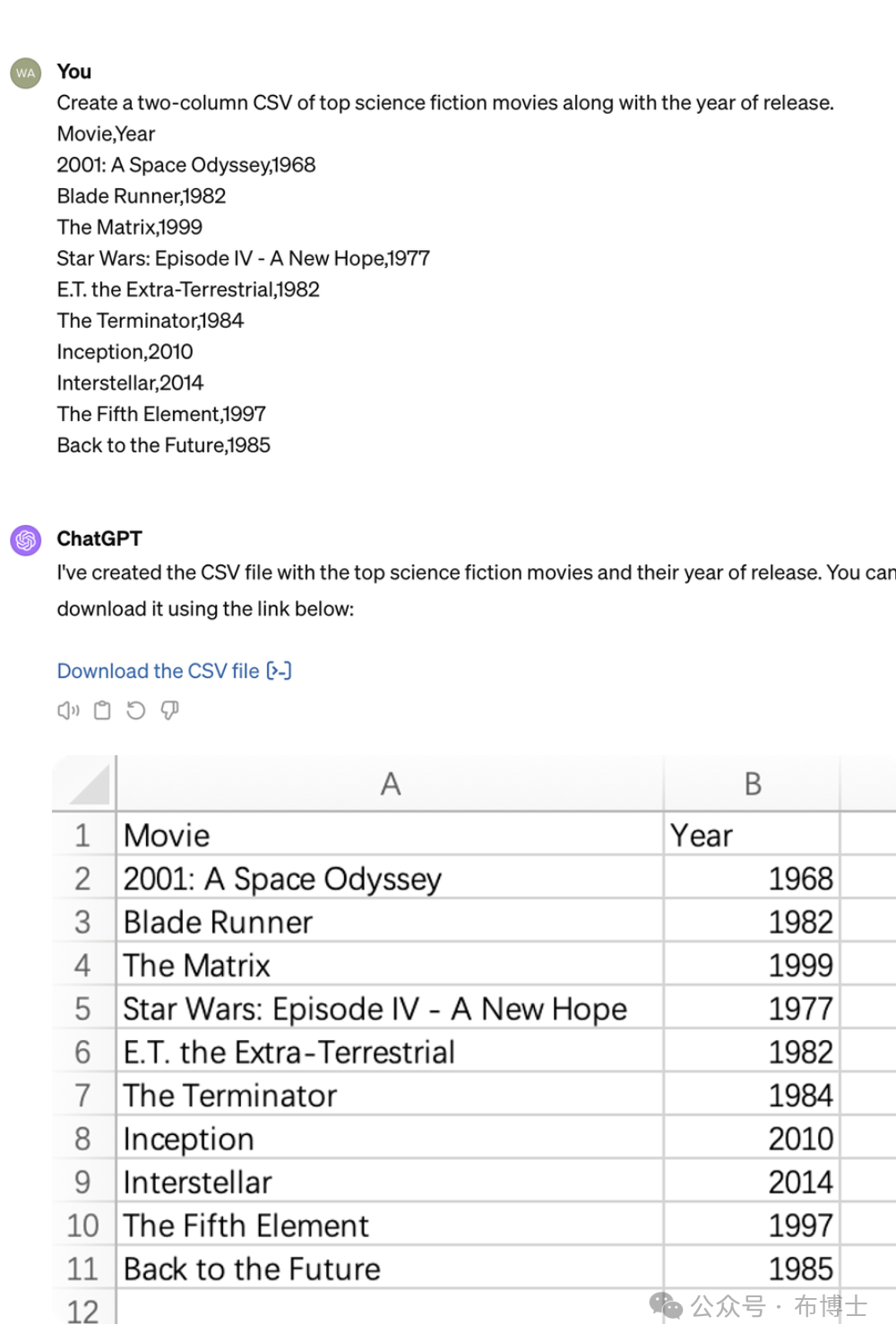
大型语言模型可用于内容格式化,能够将非结构化文本转化为结构化数据,以方便后续处理。例如,它可以将日常会话、用户反馈或者问答对话、会议录音转文本后转化为表格、列表或者其它格式的结构化数据进行存储。这种能力为数据分析、信息提取和自动化流程提供了强大支持。
如下图为将非结构化的文本转换为csv格式的数据,并提供了下载。
编程应用
大型语言模型在编程代码方面的应用表现出色,能够理解代码语义,帮助开发者解决实际问题。例如:
-
解释代码逻辑
-
评估代码时间复杂度,优化代码及执行效率
-
发现代码的bug,并优化代码
-
编写一个简单的html响应页面
-
编写测试用例
-
针对定义好的数据表说明给出操作的SQL语句
-
…
制作一个简单的html页面
任何需求只要给的明确,没有歧义,大语言模型都可以根据需求生成相应的代码。如下是生成一个简单的html页面,并带javascript的交互。
-
大模型交互过程

-
生成的代码如下:
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>JavaScript Features Demo</title><style>body { font-family: Arial, sans-serif; }.dropdown-container {margin: 20px;position: relative;display: inline-block;}.dropdown-button {padding: 10px;background-color: #f9f9f9;border: 1px solid #ccc;cursor: pointer;}.dropdown-content {display: none;position: absolute;background-color: #f9f9f9;min-width: 160px;box-shadow: 0px 8px 16px 0px rgba(0,0,0,0.2);z-index: 1;}.dropdown-content a {color: black;padding: 12px 16px;text-decoration: none;display: block;}.dropdown-content a:hover {background-color: #f1f1f1}.show {display:block;}</style></head><body><div class="dropdown-container"><button onclick="toggleDropdown()" class="dropdown-button">Click Me!</button><div id="myDropdown" class="dropdown-content"><a href="#" onclick="showMessage('Option 1')">Option 1</a><a href="#" onclick="showMessage('Option 2')">Option 2</a><a href="#" onclick="showMessage('Option 3')">Option 3</a></div></div><p id="messageArea"></p><script>function toggleDropdown() {document.getElementById("myDropdown").classList.toggle("show");}window.onclick = function(event) {if (!event.target.matches('.dropdown-button')) {var dropdowns = document.getElementsByClassName("dropdown-content");var i;for (i = 0; i < dropdowns.length; i++) {var openDropdown = dropdowns[i];if (openDropdown.classList.contains('show')) {openDropdown.classList.remove('show');}}}}function showMessage(message) {document.getElementById("messageArea").innerText = "You selected: " + message;}</script></body></html>
-
代码保存为html后的执行结果页面如下:

自然语言转sql
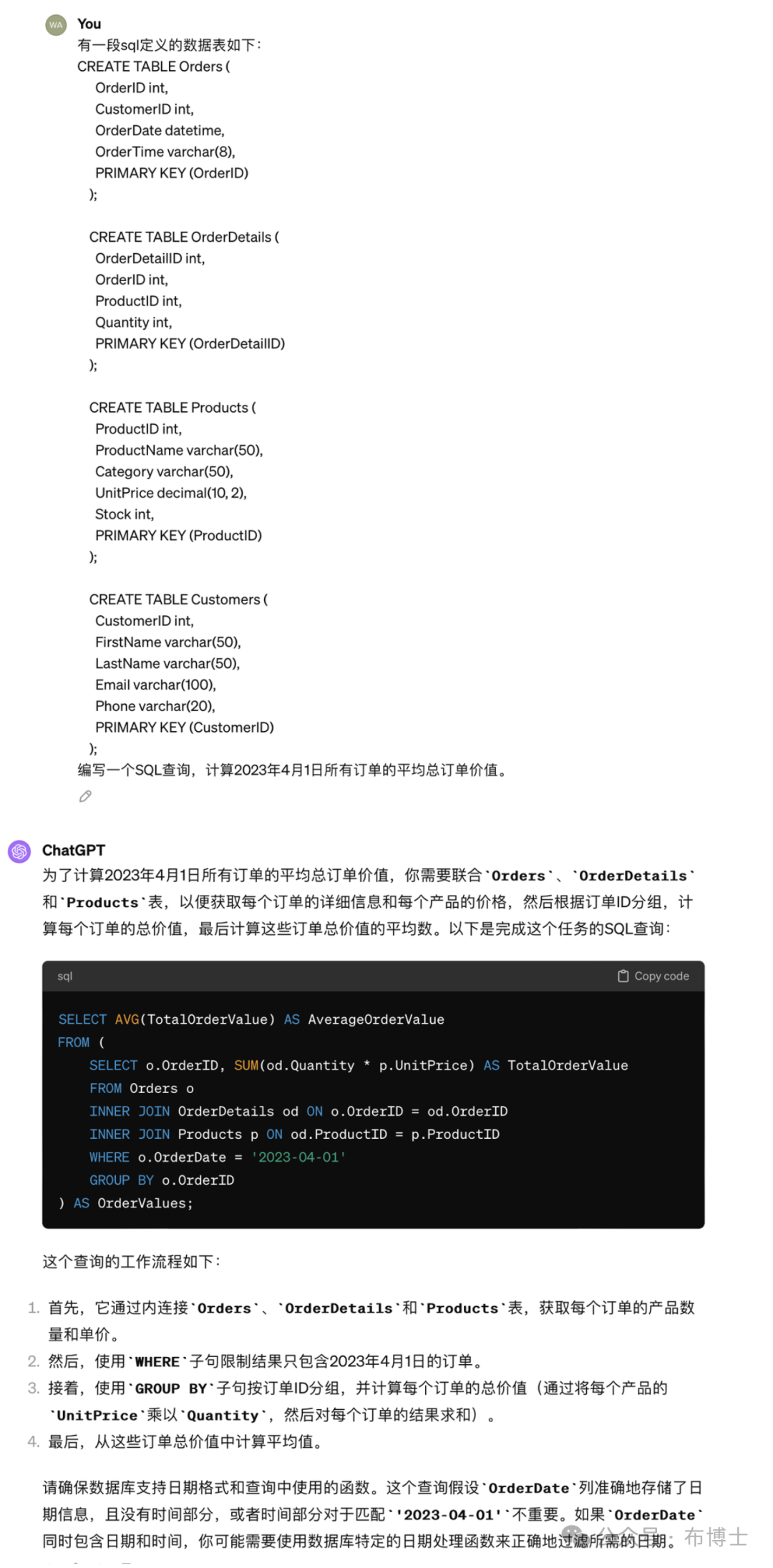
在数据处理和分析领域,我们经常需要对数据表进行复杂的增、删、改、查操作。此时,我们可以借助大型语言模型,提供明确的表结构和每个表的说明,然后明确提出自己的统计需求,如下图所示:
从告警内容中抽取信息
在我们见到的很多客户中,所提供的告警数据结构化并不好,我们

import re# 函数定义:从告警信息中抽取IP地址def extract_ip(alert_message):# 使用正则表达式匹配IP地址ip_pattern = r'\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b'match = re.search(ip_pattern, alert_message)if match:return match.group()else:return "No IP address found"# 测试用例test_cases = ["【次要告警】110.230.101.09[设备名:hp_server01],哈尔滨培训中心Timed out while waiting for response,发生时间:09/11/2020 09:36:21,【核心应用团队.网络支持团队.运营数据中心】【事件ID:1234565789000】","【紧急告警】192.168.1.105 - 无法连接到数据库,发生时间: 12/10/2021 22:45:00","正常操作信息 - 设备无告警"]# 运行测试用例并打印结果for i, test in enumerate(test_cases, start=1):print(f"Test Case {i}: IP Address - {extract_ip(test)}")
注意:未来的研发人员可能会分为两类。一类是技术更强的架构师,他们将指导架构设计,因为大模型目前还不具备这样的创造能力。第二类是了解需求的程序设计人员,他们可以更清晰地描述需求,将更多的代码工作交给大模型完成,最后只需集成和测试大模型生成的代码片段。
翻译
大语言模型在翻译方面表现出强大的能力,能够理解并准确翻译各种语言。通过机器学习的方法,它可以在不同的语言之间自由转换,无论是常见的英语、中文,还是较为少见的小语种,都能够进行高质量的翻译。这使得跨语言的交流和理解变得更加便捷。
多余的示例也不必整理,在google的翻译、苹果浏览器的翻译上这些功能早就已经存在了,只是chatGPT比其翻译得更好一些,大家可以自己实操一下。
另外结合一些插件,还可以完成对在线pdf、word等文档的翻译。
注意:翻译的质量非常好,大家可以试试看。其效率高、质量高,只需要简单的校对。对于我们这种英语能力较弱的学生来说,不论是PDF、HTML、Word等类型的文档,ChatGPT的大模型都提供了丰富的插件来帮助你阅读和翻译,非常方便。
自然语言
大语言模型在自然语言处理方面有着广泛的应用。它可以:
-
文章分类,通过分析文章的内容和风格,将文章分类到正确的类别。
-
情感分析:大模型可以理解和分析文本中的情绪和观点。
-
知识问答及聊天机器人:能基于大量的学习和训练数据,为各种问题提供准确的答案。在我在公从号文章《运维效率提升:基于大模型构建高效的运维知识及智能问答平台》中有详细的介绍。
-
会议记要:可以用于会议纪要的生成,帮助用户快速理解会议内容,形成待办项、不同人员的观点结构化等
-
…
电商评论情感分析
情感分析在产品或服务评价中具有重要价值。通过分析用户评论的情绪,可以及时了解用户对产品或服务的满意度,用以改进产品或服务,提升用户体验。
如下示例:

告警内容分类
告警分为可用性、容量、性能、报错四类,以便有效管理和响应。可用性告警需立即处理,恢复服务;容量告警关注资源使用,可能需扩容;性能告警涉及运行效率,可能需优化配置;报错告警需排错、修复。这样分类可帮助快速定位问题,制定准确策略,提高稳定性和可用性。
如下是针对告警内容进行基于告警内容分类的一个示例:

知识获取
大模型在知识获取场景下能准确理解并回答复杂问题,深度理解语境,提供贴近实际需求的答案。与传统搜索相比,大模型分析语义,而非仅匹配关键词,因此结果更符合用户实际意图,提供更具有深度和广度的知识获取体验。
如下是一个告警分类知识获取的示例:

注意:这是大型语言模型的核心能力。在2017年左右,我们通过自然语言处理模型来处理非结构化数据,这是一个庞大且复杂的工程任务,消耗了大量的算法工程师的时间,但成果却并不理想。现在,像ChatGPT这样的大型语言模型已经让这些应用更加普及,使得普通人使用的门槛也随之降低。
图像生成
对于当前的大型模型来说,我认为文生图的生成方式还是比较抽象的。它可以生成无所谓精确的、自由发挥的图片,让人看一下比较热闹,但如果想要依照以下的示例生成一张定义准确且高标准的数据可视化图,那么还有很大的差距。
告警趋势图生成
如下的示例:

12岁小朋友试用chatGPT
12岁小朋友试用chatGPT的四幅图,依次为:
-
价值100亿的苹果
-
月薪1亿的老板的办公室
-
月新100亿的办公室
-
月薪10亿的翡翠老板办公室

为本文生成一张图
以此结尾,为本文所表达的内容生成一张文章的封面图:

注意:如果你的需求描述不清晰,文生图可以发挥无限的想象力。由于这些想象的结果没有明确的对错判断,只是评估图像是否美观,对于需要通过数据表达或有精确要求的图像来说,这些图像的生成结果可能并不理想。因此,需要根据使用场景来判断。
总结
总的来说,大型语言模型在各种应用场景中都展现出了强大的能力。无论是信息提取、文本释义、内容生成、内容归纳总结,还是内容格式化、编程应用、翻译、自然语言处理、知识获取,甚至是图像生成(抽象的可以,带事实数据的欠佳),都能够有效地完成任务,提供高质量的结果。这种全面的能力使得大型语言模型在处理各种问题,满足各种需求方面都具有极高的灵活性和准确性。

















 6511
6511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









