




朴素贝叶斯(Naive Bayes)介绍
1. 基本概念
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的简单概率分类器,它假设特征之间相互独立(条件独立性假设)。尽管这个假设在实际中往往不成立,但朴素贝叶斯分类器在许多实际应用中仍然表现出色,尤其是在文本分类、垃圾邮件过滤等领域。
2. 贝叶斯定理
贝叶斯定理描述了在已知某些条件下,事件发生的概率。公式如下:
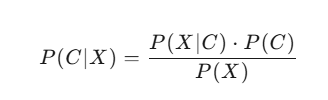
其中:
-
P(C∣X) 是在特征 X 出现的条件下,类别 C 出现的概率(后验概率)。
-
P(X∣C) 是在类别 C 出现的条件下,特征 X 出现的概率(似然概率)。
-
P(C) 是类别 C 出现的先验概率。
-
P(X) 是特征 X 出现的先验概率。
3. 朴素贝叶斯分类器
朴素贝叶斯分类器通过计算每个类别的后验概率,并选择后验概率最高的类别作为预测结果。具体步骤如下:
-
计算先验概率:计算每个类别的先验概率 P(C)。
-
计算似然概率:计算每个特征在每个类别下的条件概率 P(X∣C)。
-
计算后验概率:根据贝叶斯定理计算后验概率 P(C∣X)。
-
选择类别:选择后验概率最高的类别作为预测结果。
4. 常见类型
-
高斯朴素贝叶斯:假设特征服从高斯分布,适用于连续数值型数据。
-
多项式朴素贝叶斯:假设特征服从多项式分布,适用于离散数据(如文本分类中的词频)。
-
伯努利朴素贝叶斯:假设特征是二元的(0或1),适用于二值特征数据。
朴素贝叶斯代码示例
以下是一个使用 Python 和 scikit-learn 实现的朴素贝叶斯分类器的代码示例,用于鸢尾花(Iris)数据集的分类任务:
Python
Copy
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建高斯朴素贝叶斯分类器
gnb = GaussianNB()
# 训练模型
gnb.fit(X_train, y_train)
# 预测测试集
y_pred = gnb.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")
代码说明
-
加载数据集:
-
使用
load_iris函数加载鸢尾花数据集,该数据集包含150个样本,每个样本有4个特征,分为3个类别。
-
-
划分训练集和测试集:
-
使用
train_test_split函数将数据集划分为训练集和测试集,测试集占30%。
-
-
创建分类器:
-
使用
GaussianNB创建高斯朴素贝叶斯分类器。
-
-
训练模型:
-
调用
fit方法训练模型。
-
-
预测和评估:
-
使用训练好的模型对测试集进行预测,并计算准确率。
-
朴素贝叶斯在医学图像分类中的应用
1. 医学图像分类
-
研究背景:在医学图像分类任务中,朴素贝叶斯分类器被用于处理有限样本的分类问题,尤其是在特征提取和分类阶段。
-
方法:研究者通常会先提取医学图像的特征(如纹理特征、形状特征等),然后使用朴素贝叶斯分类器进行分类。
-
结果:朴素贝叶斯分类器在一些医学图像分类任务中表现出色,尤其是在处理有限样本和高维特征时。
2. 实际应用案例
-
病理图像分类:在病理图像分类任务中,朴素贝叶斯分类器被用于少样本学习场景,以应对有限样本的挑战。
-
医学图像分割:在医学图像分割任务中,朴素贝叶斯分类器被用于处理复杂背景和对象的分割问题。
总结
朴素贝叶斯分类器是一种简单而有效的分类方法,特别适用于处理有限样本和高维特征的问题。尽管其条件独立性假设在实际中往往不成立,但在许多实际应用中仍然表现出色。通过上述代码示例,你可以快速实现一个朴素贝叶斯分类器,并在实际任务中进行应用。



















 1488
1488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











