




Docugami XML Knowledge Graphs (KG-RAG) 应用指南
简介
许多文档包含多种内容类型,包括文本和表格。
传统的RAG(Retrieval-Augmented Generation)处理半结构化数据时可能会遇到一些问题,因为仅通过文本分割可能会丢失语义,例如:
- 文本分割可能会破坏表格,导致检索时数据损坏
- 嵌入表格可能会对语义相似性搜索带来挑战
Docugami 将文档分解为由层次化的语义块组成的 XML 知识图谱,使用 XML 数据模型。本指南展示了如何使用 XML 知识图谱作为输入执行 RAG(KG-RAG):
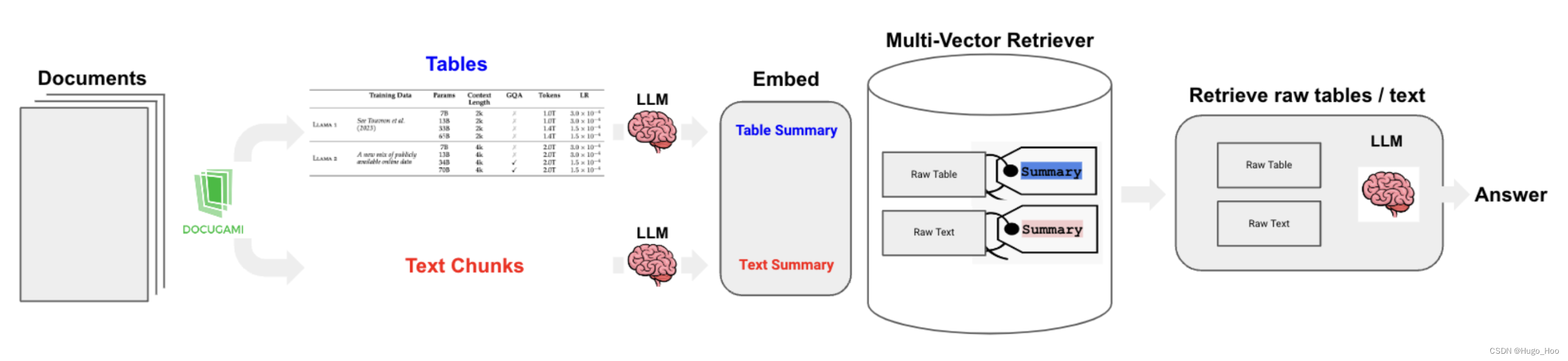
我们将使用 Docugami 从文档(PDF [扫描或数字],DOC 或 DOCX)中分割出文本和表格块,包括块中的语义 XML 标记。
我们将使用多向量检索器存储原始表格和文本(包括语义 XML 标记)以及更适合检索的表格摘要。
我们将使用 LCEL 来实现所使用的链。
整体流程如下:
安装包
Python
! pip install langchain docugami==0.0.8 dgml-utils==0.3.0 pydantic langchainhub chromadb hnswlib --upgrade --quiet
Docugami 在云端处理文档,因此您不需要安装任何额外的本地依赖项。
数据加载
让我们使用 Docugami 处理一些文档。以下是开始所需的步骤:
- 创建一个 Docugami 工作区(提供免费试用)
- 通过开发者游乐场为您的工作区创建访问令牌。详细说明。
- 将您的文档(PDF [扫描或数字],DOC 或 DOCX)添加到 Docugami 进行处理。有两种方法可以做到这一点:
- 使用简单的 Docugami Web 体验。详细说明。
- 使用 Docugami API,特别是文档端点。您也可以使用 docugami python 库作为一个方便的包装器。
一旦您的文档进入 Docugami,它们将被处理并组织成相似文档的集合,例如 NDAs(保密协议)、租赁协议和服务协议。Docugami 不限于任何特定类型的文档,创建的聚类取决于您的特定文档。如果您愿意,稍后可以更改文档集分配。您可以在简单的 Docugami Web 应用程序中监视文件状态,或者使用 webhook 在文档处理完成时收到通知。
您也可以使用 Docugami API 或 docugami python 库执行所有文件处理,而无需访问 Docugami Web 应用程序,除非是为了获取 API 密钥。
您可以在这里获取 API 密钥:https://help.docugami.com/home/docugami-api。以下代码假定您已经设置了 DOCUGAMI_API_TOKEN 环境变量。
首先,让我们定义两个简单的辅助方法来上传文件并等待它们完成处理。
from pprint import pprint
from docugami import Docugami
from docugami.lib.upload import upload_to_named_docset, wait_for_dgml
# 开始文档集信息(根据需要更改这些值)
DOCSET_NAME = "NTSB Aviation Incident Reports" # NTSB航空事故报告
FILE_PATHS = [
"/Users/tjaffri/ntsb/Report_CEN23LA277_192541.pdf",
"/Users/tjaffri/ntsb/Report_CEN23LA338_192753.pdf",
# ... 更多文件路径
]
# 注意:请指定大约6个(或更多!)类似的文件一起处理作为一个文档集
# 这是 Docugami 自动检测文档集中的模式以生成语义 XML 知识图谱的当前要求
assert len(FILE_PATHS) > 5, "请提供至少6个文件"
# 结束文档集信息
dg_client = Docugami()
dg_docs = upload_to_named_docset(dg_client, FILE_PATHS, DOCSET_NAME)
dgml_paths = wait_for_dgml(dg_client, dg_docs)
pprint(dgml_paths)
如果您使用的是免费的 Docugami 层级,您的文件应该在大约15分钟或更短时间内完成,具体取决于上传的页数和可用资源(请联系 Docugami 了解更快处理的付费计划)。如果您的笔记本没有持续运行,您可以重新运行上述代码而不需要重新处理文件以继续等待(它不会重新上传)。
分割 PDF 表格和文本
您可以使用 Docugami Loader 非常轻松地获取文档的块,包括语义和结构元数据。这是大多数用例的更简单且推荐的方法,但在本文中,让我们探索使用 dgml-utils 库更详细地探索此文件的分割输出,通过处理我们刚刚下载的 XML。
from pathlib import Path
from dgml_utils.segmentation import get_chunks_str
# 我们只是读取第一个文件,您也可以对其他文件做同样的事情
dgml_path = dgml_paths[Path(FILE_PATHS[0]).name]
with open(dgml_path, " 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











