




 这篇博客介绍了如何使用Python实现CIFAR10数据集上的KNN分类器,包括数据读取、预处理、KNN算法的l1和l2距离计算,并通过交叉验证来确定最佳的k值。还展示了训练和测试过程以及部分代码示例。
这篇博客介绍了如何使用Python实现CIFAR10数据集上的KNN分类器,包括数据读取、预处理、KNN算法的l1和l2距离计算,并通过交叉验证来确定最佳的k值。还展示了训练和测试过程以及部分代码示例。
数据
CIFAR10,下载python版本。
作业内容
实现一个knn分类器,用次knn分类似对CIFAR10的数据进行训练和预测。
knn分类器:
knn分类器额工作分为两部(1)训练:读取训练数据并存储训练数据。(2)测试:对于每一个测试图像,knn计算它与每一个训练集的距离,找出距离最近的k个训练图像,这k个图像中,占数目最多的标签类别,就是测试图像的预测类别。
而计算图像之间的距离有两种方式,分别是l1距离和l2距离。
l1距离是曼哈顿距离,即
l2距离是欧几里得距离。即
此外,测试部分中k的值对结果有很大影响,较小k值容易受到噪声的影响,较大的k值则会导致边界上样本的分类有歧义。这理为了找到合适的k值,使用交叉验证的方法。
作业
数据读取和处理
第一步是加载数据,附上cs231n的data_util代码内容。
from __future__ import print_function
from six.moves import cPickle as pickle
import numpy as np
import os
from scipy.misc import imread
import platform
def load_pickle(f):
version = platform.python_version_tuple()
if version[0] == '2':
return pickle.load(f)
elif version[0] == '3':
return pickle.load(f, encoding='latin1')
raise ValueError("invalid python version: {}".format(version))
def load_CIFAR_batch(filename):
""" load single batch of cifar """
with open(filename, 'rb') as f:
datadict = load_pickle(f)
X = datadict['data']
Y = datadict['labels']
X = X.reshape(10000, 3, 32, 32).transpose(0, 2, 3, 1).astype("float")
Y = np.array(Y)
return X, Y
def load_CIFAR10(ROOT):
""" load all of cifar """
xs = []
ys = []
for b in range(1, 6):
f = os.path.join(ROOT, 'data_batch_%d' % (b,))
X, Y = load_CIFAR_batch(f)
xs.append(X)
ys.append(Y)
Xtr = np.concatenate(xs)
Ytr = np.concatenate(ys)
del X, Y
Xte, Yte = load_CIFAR_batch(os.path.join(ROOT, 'test_batch'))
return Xtr, Ytr, Xte, Yte
def get_CIFAR10_data(num_training=49000, num_validation=1000, num_test=1000,
subtract_mean=True):
"""
Load the CIFAR-10 dataset from disk and perform preprocessing to prepare
it for classifiers. These are the same steps as we used for the SVM, but
condensed to a single function.
"""
# Load the raw CIFAR-10 data
cifar10_dir = 'cs231n/datasets/cifar-10-batches-py'
X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
# Subsample the data
mask = list(range(num_training, num_training + num_validation))
X_val = X_train[mask]
y_val = y_train[mask]
mask = list(range(num_training))
X_train = X_train[mask]
y_train = y_train[mask]
mask = list(range(num_test))
X_test = X_test[mask]
y_test = y_test[mask]
# Normalize the data: subtract the mean image
if subtract_mean:
mean_image = np.mean(X_train, axis=0)
X_train -= mean_image
X_val -= mean_image
X_test -= mean_image
# Transpose so that channels come first
X_train = X_train.transpose(0, 3, 1, 2).copy()
X_val = X_val.transpose(0, 3, 1, 2).copy()
X_test = X_test.transpose(0, 3, 1, 2).copy()
# Package data into a dictionary
return {
'X_train': X_train, 'y_train': y_train,
'X_val': X_val, 'y_val': y_val,
'X_test': X_test, 'y_test': y_test,
}
def load_tiny_imagenet(path, dtype=np.float32, subtract_mean=True):
"""
Load TinyImageNet. Each of TinyImageNet-100-A, TinyImageNet-100-B, and
TinyImageNet-200 have the same directory structure, so this can be used
to load any of them.
Inputs:
- path: String giving path to the directory to load.
- dtype: numpy datatype used to load the data.
- subtract_mean: Whether to subtract the mean training image.
Returns: A dictionary with the following entries:
- class_names: A list where class_names[i] is a list of strings giving the
WordNet names for class i in the loaded dataset.
- X_train: (N_tr, 3, 64, 64) array of training images
- y_train: (N_tr,) array of training labels
- X_val: (N_val, 3, 64, 64) array of validation images
- y_val: (N_val,) array of validation labels
- X_test: (N_test, 3, 64, 64) array of testing images.
- y_test: (N_test,) array of test labels; if test labels are not available
(such as in student code) then y_test will be None.
- mean_image: (3, 64, 64) array giving mean training image
"""
# First load wnids
with open(os.path.join(path, 'wnids.txt'), 'r') as f:
wnids = [x.strip() for x in f]
# Map wnids to integer labels
wnid_to_label = {wnid: i for i, wnid in enumerate(wnids)}
# Use words.txt to get names for each class
with open(os.path.join(path, 'words.txt'), 'r') as f:
wnid_to_words = dict(line.split('\t') for line in f)
for wnid, words in wnid_to_words.iteritems():
wnid_to_words[wnid] = [w.strip() for w in words.split(',')]
class_names = [wnid_to_words[wnid] for wnid in wnids]
# Next load training data.
X_train = []
y_train = []
for i, wnid in enumerate(wnids):
if (i + 1) % 20 == 0:
print('loading training data for synset %d / %d' % (i + 1, len(wnids)))
# To figure out the filenames we need to open the boxes file
boxes_file = os.path.join(path, 'train', wnid, '%s_boxes.txt' % wnid)
with open(boxes_file, 'r') as f:
filenames = [x.split('\t')[0] for x in f]
num_images = len(filenames)
X_train_block = np.zeros((num_images, 3, 64, 64), dtype=dtype)
y_train_block = wnid_to_label[wnid] * np.ones(num_images, dtype=np.int64)
for j, img_file in enumerate(filenames):
img_file = os.path.join(path, 'train', wnid, 'images', img_file)
img = imread(img_file)
if img.ndim == 2:
## grayscale file
img.shape = (64, 64, 1)
X_train_block[j] = img.transpose(2, 0, 1)
X_train.append(X_train_block)
y_train.append(y_train_block)
# We need to concatenate all training data
X_train = np.concatenate(X_train, axis=0)
y_train = np.concatenate(y_train, axis=0)
# Next load validation data
with open(os.path.join(path, 'val', 'val_annotations.txt'), 'r') as f:
img_files = []
val_wnids = []
for line in f:
img_file, wnid = line.split('\t')[:2]
img_files.append(img_file)
val_wnids.append(wnid)
num_val = len(img_files)
y_val = np.array([wnid_to_label[wnid] for wnid in val_wnids])
X_val = np.zeros((num_val, 3, 64, 64), dtype=dtype)
for i, img_file in enumerate(img_files):
img_file = os.path.join(path, 'val', 'images', img_file)
img = imread(img_file)
if img.ndim == 2:
img.shape = (64, 64, 1)
X_val[i] = img.transpose(2, 0, 1)
# Next load test images
# Students won't have test labels, so we need to iterate over files in the
# images directory.
img_files = os.listdir(os.path.join(path, 'test', 'images'))
X_test = np.zeros((len(img_files), 3, 64, 64), dtype=dtype)
for i, img_file in enumerate(img_files):
img_file = os.path.join(path, 'test', 'images', img_file)
img = imread(img_file)
if img.ndim == 2:
img.shape = (64, 64, 1)
X_test[i] = img.transpose(2, 0, 1)
y_test = None
y_test_file = os.path.join(path, 'test', 'test_annotations.txt')
if os.path.isfile(y_test_file):
with open(y_test_file, 'r') as f:
img_file_to_wnid = {}
for line in f:
line = line.split('\t')
img_file_to_wnid[line[0]] = line[1]
y_test = [wnid_to_label[img_file_to_wnid[img_file]] for img_file in img_files]
y_test = np.array(y_test)
mean_image = X_train.mean(axis=0)
if subtract_mean:
X_train -= mean_image[None]
X_val -= mean_image[None]
X_test -= mean_image[None]
return {
'class_names': class_names,
'X_train': X_train,
'y_train': y_train,
'X_val': X_val,
'y_val': y_val,
'X_test': X_test,
'y_test': y_test,
'class_names': class_names,
'mean_image': mean_image,
}
def load_models(models_dir):
"""
Load saved models from disk. This will attempt to unpickle all files in a
directory; any files that give errors on unpickling (such as README.txt) will
be skipped.
Inputs:
- models_dir: String giving the path to a directory containing model files.
Each model file is a pickled dictionary with a 'model' field.
Returns:
A dictionary mapping model file names to models.
"""
models = {}
for model_file in os.listdir(models_dir):
with open(os.path.join(models_dir, model_file), 'rb') as f:
try:
models[model_file] = load_pickle(f)['model']
except pickle.UnpicklingError:
continue
return models将数据即放在cs231n/dataset目录下,然后利用上述代码的函数读取文件
from __future__ import print_function
import random
import numpy as np
from cs231n.data_utils import load_CIFAR10
import matplotlib.pyplot as plt
# from past.builtins import xrange
def time_function(f,*args):
import time
tic = time.time()
f(*args)
toc = time.time()
return toc-tic
plt.rcParams['figure.figsize'] = (10.0,8.0)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
cifar10_dir = 'cs231n/dataset/cifar-10-batches-py'
X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
print('Traing data shape: ',X_train.shape)
print('Traing labels shape: ',y_train.shape)
print('Test data shape: ', X_test.shape)
print('Test labels shape: ', y_test.shape)显示数据的大小:

再从数据的每个类别中随机选取7个样本图像输出:
classes =['plane','car','bird','cat','deer','dog','frog','horse','ship','truck']
num_classes = len(classes)
samples_per_class = 7
for y, cls in enumerate(classes):
idxs = np.flatnonzero(y_train == y)
# 找出标签为y的全部索引
idxs = np.random.choice(idxs, samples_per_class, replace = False)
# 从中随机选择7个数据
for i,idx in enumerate(idxs):
plt_idx = i*num_classes +y +1
plt.subplot(samples_per_class, num_classes, plt_idx)
plt.imshow(X_train[idx].astype('uint8'))
plt.axis('off')
if i ==0 :
plt.title(cls)
plt.show()输出图像:
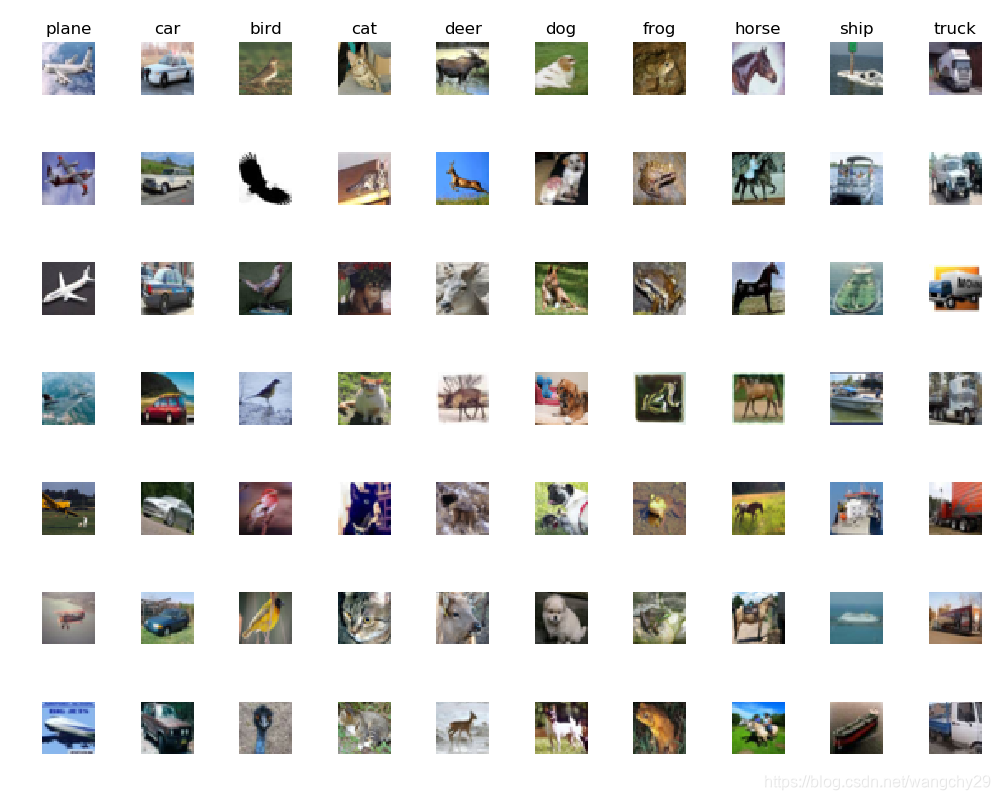
然后为了减少程序运行的时间,这里值选取5000个训练数据和500个测试数据进行训练和预测:
num_training = 5000
mask = list (range(num_training))
X_train = X_train[mask]
y_train = y_train[mask]
num_test = 500
mask = list (range(num_test))
X_test = X_test[mask]
y_test = y_test[mask]再次输出训练数据和测试数据的大小:

再将数据转换为二维数据:
X_train = np.reshape(X_train, (X_train.shape[0],-1))
X_test = np.reshape(X_test,(X_test.shape[0],-1))
print(X_train.shape,X_test.shape)输出数据的大小:
![]()
knn实现
定义一个类,包含knn分类器的初始化、训练、测试部分。
class k_nearest_neighbor(object):
def __init__(self):
pass
def train(self,X,y):
self.X_train = X
self.y_train = y
定义测试:
def predict(self,X,k,numloops = 1):
if numloops == 1:
dists = self.compute_distances_one_loop(X)
elif numloops == 2:
dists = self.compute_distances_two_loops(X)
else:
print("error")
return self.predict_labels(dists,k=k)
定义三种距离的测试:
def compute_distances_two_loops(self,X):
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test,num_train))
for i in range(num_test):
for j in range(num_train):
dists[i][j]=np.sqrt(np.sum(np.square(self.X_train[j,:]- X[i,:])))
# print(dists)
return dists
def compute_distances_one_loop(self,X):
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
dists[i] = np.sqrt(np.sum(np.square(X[i, :] - self.X_train),axis=1))
return dists
def compute_distance_no_loops(self,X):
# dists = (x^2+x_train^2-2xx_train^T)^(1/2)
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test,num_train))
dists = np.multiply(np.dot(X,self.X_train.T),-2)
sq1 = np.sum(np.square(X),axis=1,keepdims = True)
sq2 = np.sum(np.square(self.X_train),axis=1)
dists = np.add(dists,sq1)
dists = np.add(dists,sq2)
dists = np.sqrt(dists)
return dists
类别预测:
def predict_labels(self,dists,k):
num_test = dists.shape[0]
y_pred = np.zeros(num_test)
for i in range(num_test):
closest_y = self.y_train[np.argsort(dists[i,:])[:k]]
y_pred[i] = np.argmax(np.bincount(closest_y))
return y_pred训练和测试:
from cs231n.classifiers import k_nearest_neighbor
knn= k_nearest_neighbor()
knn.train(X_train, y_train)
dists = knn.compute_distances_two_loops(X_test)
# print(dists.shape)
#
# plt.imshow(dists, interpolation = 'none')
# plt.show()
y_test_pred = knn.predict_labels(dists,k=10)
# print(y_test_pred)
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct)/num_test
print('Got %d / %d correct => accuracy: %f'% (num_correct,num_test,accuracy))结果:
交叉验证:
num_folds = 5
k_choices = [1,3,5,8,10,12,15,20,50,100]
X_train_folds = []
y_train_folds = []
X_train_folds = np.array_split(X_train, num_folds)
y_train_folds = np.array_split(y_train, num_folds)
k_to_accuracies = {}
for k in k_choices:
accuracies = np.zeros(num_folds)
for fold in range(num_folds):
temp_X = X_train_folds[:]
temp_y = y_train_folds[:]
X_validate_fold = temp_X.pop(fold)
y_validate_fold = temp_y.pop(fold)
temp_X = np.array([y for x in temp_X for y in x])
temp_y = np.array([y for x in temp_y for y in x])
knn.train(temp_X,temp_y)
y_test_pred = knn.predict(X_validate_fold,k =k)
num_correct = np.sum(y_test_pred == y_validate_fold)
accuracy = float(num_correct)/num_test
accuracies[fold]= accuracy
k_to_accuracies[k]=accuracies
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f'% (k ,accuracy))可视化:
for k in k_choices:
accuracies = k_to_accuracies[k]
plt.scatter([k]*len(accuracies),accuracies)
accuracies_mean = np.array([np.mean(v) for k,v in sorted(k_to_accuracies)])
accuracies_std = np.array([np.std(v) for k,v in sorted(k_to_accuracies)])
plt.errorbar(k_choices, accuracies_mean, yerr=accuracies_std)
plt.title('Cross-validation on k')
plt.xlabel('k')
plt.ylabel('Cross-validation accuracy')
plt.show()
https://blog.youkuaiyun.com/zhangxb35/article/details/55223825
https://blog.youkuaiyun.com/u014485485/article/details/79433514

















 640
640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









