



1.open系统调用
在 Linux 中, open() 系统调用用于打开一个文件或设备,并返回一个文件描述符,通过该描述符可以进行文件读写操作。open() 可以用于创建新文件或打开已存在的文件,具体行为取决于传递给它的参数。
需要包含的头文件:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
函数原型:
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
int creat(const char *pathname, mode_t mode);
参数解释:
pathname: 要打开或创建的⽬标⽂件
flags: 打开⽂件时,可以传⼊多个参数选项,⽤下⾯的⼀个或者多个常量进⾏“或”运算,构成
flags。
参数:
O_RDONLY: 只读打开
O_WRONLY: 只写打开
O_RDWR : 读,写打开
这三个常量,必须指定⼀个且只能指定⼀个
O_CREAT : 若⽂件不存在,则创建它。需要使⽤mode选项,来指明新⽂件的访问权限
O_APPEND: 追加写
返回值:
成功:新打开的⽂件描述符
失败:-1
mode 参数用于设置文件权限,通常只有在使用 O_CREAT 标志时才会使用。它指定文件的新权限,控制谁可以读取、写入和执行该文件。mode 是一个表示文件权限的整数,使用常量来组合不同的权限位。
常见的 mode 权限:
S_IRUSR:用户可读权限。
S_IWUSR:用户可写权限。
S_IXUSR:用户可执行权限。
S_IRGRP:组用户可读权限。
S_IWGRP:组用户可写权限。
S_IXGRP:组用户可执行权限。
S_IROTH:其他用户可读权限。
S_IWOTH:其他用户可写权限。
S_IXOTH:其他用户可执行权限。
示例:
open("file.txt", O_CREAT, S_IRUSR | S_IWUSR);
这会创建一个新文件,并设置权限为文件所有者可读和可写。
也可以用二进制表示
open("myfile", O_WRONLY | O_CREAT, 00644);
文件所有者权限为读写。用户组和其他用户权限为只读。



myfile.c:
(1)打开文件:
使用 open() 函数以只读 (O_RDONLY) 和创建文件 (O_CREAT) 的模式打开 log.txt 文件。如果文件不存在,O_CREAT 会创建文件。若文件打开失败,程序会输出错误并返回 -1。
(2)读取文件:
通过 read() 函数从文件描述符 fd 中读取数据到 buff 中。read() 函数将最多读取 strlen(msg) 字符(这是一个错误的参数,应该是缓冲区大小)。
(3)输出内容:
如果读取成功(s > 0),则通过 printf() 输出读取到的内容。否则,退出循环。
(4)关闭文件:
使用 close() 关闭文件描述符。
2.文件描述符
2.1.文件描述符
文件描述符(File Descriptor,简称 FD)是操作系统为每个进程提供的一种标识符,用于访问打开的文件、设备或其他输入输出资源。文件描述符是一个非负整数,它在进程的文件表中对应着一个指向内核中文件信息的指针。
上面myfile.c中 read 之所以可以通过 int 类型的 fd 读取到 long.txt 文件的内容就是因为每个文件都有一个文件描述符。
(1)文件描述符的工作原理
每个进程在打开文件时,操作系统会为该进程分配一个文件描述符。文件描述符不仅仅用于普通文件,还可以用于设备、管道和套接字等其他输入输出资源。操作系统通过文件描述符来管理文件的读写操作。
Linux进程默认情况下会有3个缺省打开的文件描述符,分别是:
标准输入(STDIN):文件描述符 0,用于从用户或其他程序读取数据。
标准输出(STDOUT):文件描述符 1,用于向用户或其他程序输出数据。
标准错误输出(STDERR):文件描述符 2,用于输出错误信息。
除了标准输入、输出和错误输出外,应用程序可以打开更多文件,操作系统会为每个打开的文件分配一个文件描述符。
(2)打开文件与文件描述符
当你调用 open() 函数打开一个文件时,操作系统会返回一个文件描述符,这个描述符可以用于后续的文件操作(如读写)。
int fd = open("example.txt", O_RDONLY);
这行代码尝试以只读模式打开 example.txt 文件,并返回一个文件描述符 fd。之后,可以使用该文件描述符来执行文件读写操作。
(3)文件描述符的使用
在文件描述符返回后,可以通过以下系统调用来进行操作:
read(fd, buffer, size):从文件描述符 fd 所指向的文件(或资源)中读取最多 size 字节的数据到 buffer 中。
write(fd, buffer, size):向文件描述符 fd 所指向的文件(或资源)写入 size 字节的数据。
close(fd):关闭文件描述符,释放该文件描述符在进程中的资源(比如让这个描述符编号可以被后续的 open 等操作重新复用),并解除进程与该文件的关联关系。
(4)文件描述符表
操作系统维护一个文件描述符表,每个进程有一个独立的文件描述符表。文件描述符表的每个条目指向一个内核中的文件表,该表保存了文件的详细信息(如文件位置指针、权限等)。通过文件描述符,操作系统可以访问这些信息。

write(1(标准输出的文件描述符), ...) 会将 hello henu 输出到标准输出(屏幕)。
write(2, ...) 会将相同的 hello henu 输出到标准错误(通常也是屏幕,但会有不同的标记或颜色,取决于终端设置)。
2.2.文件描述符分配规则
标准文件描述符
在 Linux 和 Unix 系统中,每个进程默认会打开三个文件描述符,分别是:
标准输入(STDIN): 文件描述符 0。
标准输出(STDOUT): 文件描述符 1。
标准错误输出(STDERR): 文件描述符 2。
从 3 开始的文件描述符
当一个文件第一次通过 open() 打开时,它会获得文件描述符 3。
第二个文件会分配文件描述符 4,以此类推。
除了标准输入、输出和错误输出外,进程还可以打开更多文件或设备。这些文件描述符的分配从文件描述符 3 开始,并且会根据文件打开的顺序逐个递增。
文件描述符的分配是按顺序进行的,并且不会跳过数字。
1 #include <stdio.h>
2 #include <sys/types.h>
3 #include <sys/stat.h>
4 #include <fcntl.h>
5
6 int main()
7 {
8 int fd = open("myfile", O_RDONLY);
9 if(fd < 0)
10 {
11 perror("open");
12 return 1;
13 }
14 printf("%d\n", fd);
15
16 close(fd);
17 return 0;
18 }
![]()



发现是 fd 的结果是0、2,可见,文件描述符的分配规则:在记录文件描述符的 files_struct 数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符。
3.重定向
如果将标准输出(1)关闭,会发生什么呢?
1 #include <stdio.h>
2 #include <sys/types.h>
3 #include <sys/stat.h>
4 #include <fcntl.h>
5 #include <stdlib.h>
6
7 int main()
8 {
9 close(1);
10 int fd = open("log.txt", O_RDWR | O_CREAT, 00644);
11 if(fd < 0)
12 {
13 perror("open");
14 return 1;
15 }
16 printf("d: %d", fd);
17 fflush(stdout);
18
19 close(fd);
20 return 0;
21 }

此时,我们发现,本来应该输出到显示器上的内容,输出到了文件 myfile 当中,其中,fd=1。这
种现象叫做输出重定向。常见的重定向有: > , >> , < 。
几个细节:
printf是C库当中的IO函数,一般往 stdout 中输出,但是stdout底层访问文件的时候,找的还是fd:1,
但此时,fd:1下标所表示内容,已经变成了myfifile的地址,不再是显示器文件的地址,所以,输出的任何消息都会往文件中写入,进而完成输出重定向。
open参数:第一个0表示这是八进制,第二个零是特殊权限设置,644分别是文件所有者、所属组、其他用户的权限。
常见的几种重定向:
>:将标准输出重定向到文件,覆盖原文件内容。
>>:将标准输出重定向到文件,追加到文件末尾。
<:将文件内容作为标准输入提供给命令。
2>:将标准错误重定向到文件,覆盖原文件内容。
2>>:将标准错误追加到文件末尾。
&>:同时将标准输出和标准错误重定向到同一个文件,覆盖原文件内容。
>&:将标准输出和标准错误输出重定向到同一个文件,功能与 &> 类似。
2>&1:将标准错误重定向到标准输出,通常用于将两者合并到同一个文件。
4.dup2系统调用
dup2 是一个在 Unix-like 操作系统中用于文件描述符复制的系统调用。它可以将一个文件描述符复制到另一个指定的文件描述符,通常用于重定向输入输出。

参数:
oldfd:现有的文件描述符,通常是一个已打开的文件或设备(如标准输入、标准输出等)。
newfd:目标文件描述符。dup2 会将 oldfd 的副本复制到 newfd,并关闭 newfd(如果它已经打开)。
返回值:
成功时,返回 newfd,即新的文件描述符。
失败时,返回 -1,并设置 errno。
功能:
dup2 会将 oldfd 指向的文件或设备重定向到 newfd。
如果 newfd 已经打开,dup2 会先关闭 newfd,然后将 oldfd 的文件描述符复制到 newfd。
如果 oldfd 等于 newfd,dup2 不会做任何操作,只会返回 newfd。
1 #include <stdio.h>
2 #include <sys/types.h>
3 #include <sys/stat.h>
4 #include <fcntl.h>
5 #include <stdlib.h>
6 #include <unistd.h>
7
8 int main()
9 {
10 // close(1);
11 int fd = open("log.txt", O_RDWR | O_CREAT, 00644);//使用O_APPEND则是追加写入
12 if(fd < 0)
13 {
14 perror("open");
15 return 1;
16 }
17 dup2(fd, 1);
18 while(1)
19 {
20 char buf[1024] = {0};
21 ssize_t read_size = read(0, buf, sizeof(buf) - 1);
22 if(read_size < 0)
23 {
24 perror("read");
25 return 1;
26 }
27 printf("%s", buf);
28 fflush(stdout);
29 }
30
31 return 0;
32 }
从标准输入读取内容到buffer里,buffer使用printf打印到文件描述符1所指向的文件中。

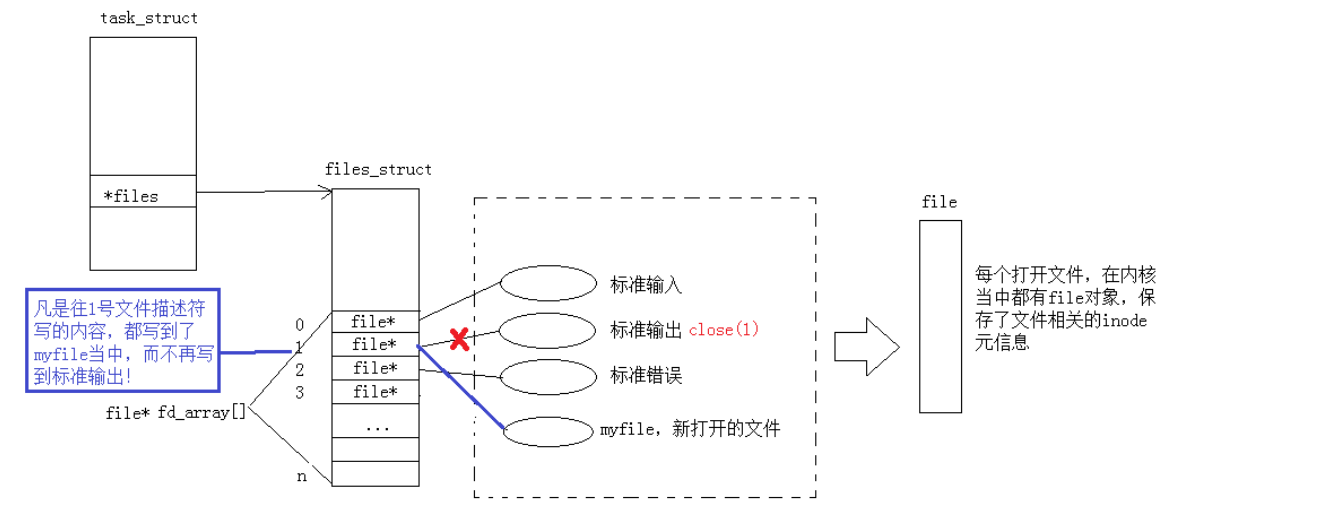
重定向的本质是通过改变文件描述符与实际资源的映射关系,实现输入 / 输出流的 “转向”。每个进程都有一张文件描述符表,重定向的本质是修改这张表中某个描述符的映射目标。
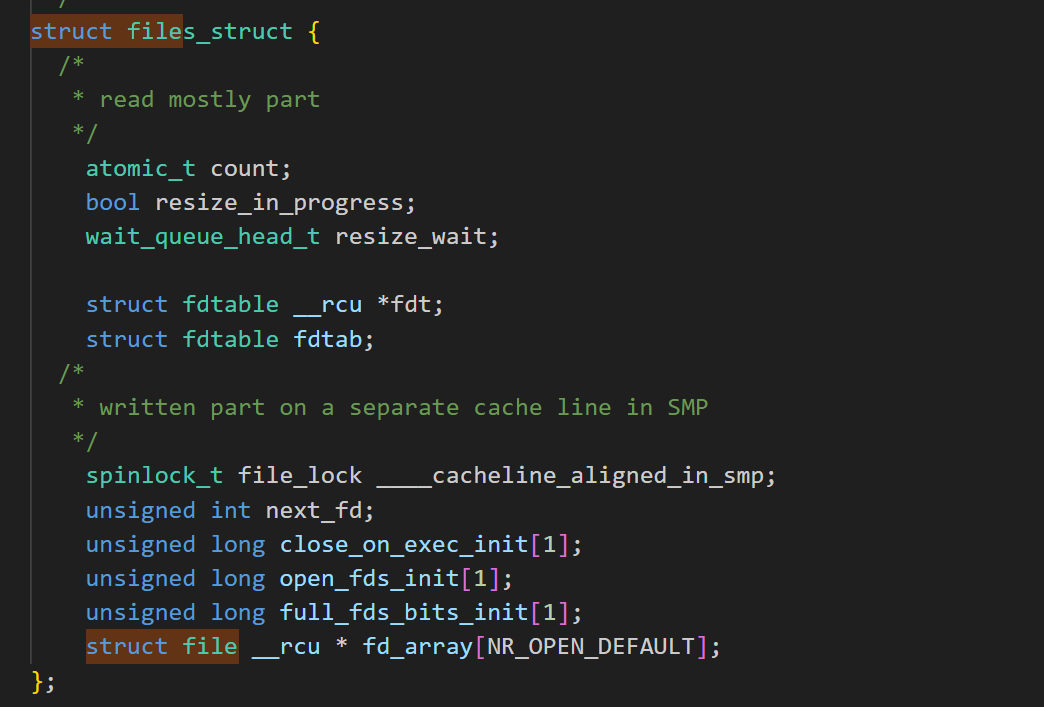
在linux内核中,文件描述符表由 struct files_struct 组织管理。
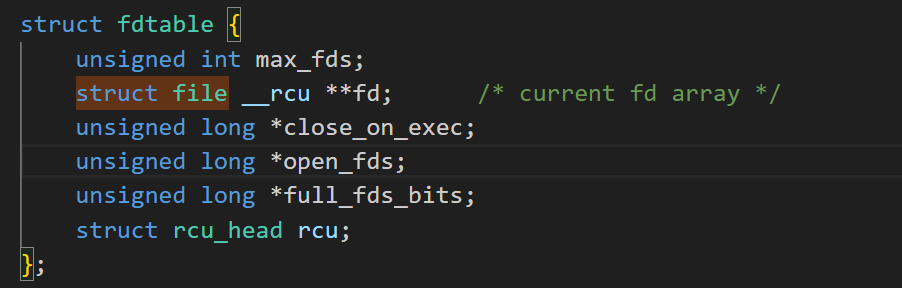
- 核心成员 struct fdtable *fdt 指向动态文件描述符表,其中 struct file __rcu **fd 是一个可动态扩容的指针数组。数组的下标对应文件描述符(如 oldfd、newfd),元素是指向 struct file 结构体的指针(即文件实例的引用);
- fd_array 是一个静态数组,当进程打开的文件数超过 NR_OPEN_DEFAULT 时,内核会通过 fdtable 结构体进行动态扩容,但 fd_array 作为 “基础数组”,始终承担着小数量文件描述符的高效管理(避免频繁动态分配的开销)。
dup2(oldfd, newfd) 可以理解为:将 oldfd 下标对应的 struct file 指针,拷贝到 newfd 下标对应的位置。如果 newfd 原本已有指向(即已打开文件),dup2 会先关闭它,再完成指针拷贝。
5.缓冲区
5.1.缓冲区类型
标准I/O提供了3种类型的缓冲区:
- 全缓冲区:这种缓冲方式要求填满整个缓冲区后才进行I/O系统调用操作。对于磁盘文件的操作通常使用全缓冲的方式访问。
- 行缓冲区:在行缓冲情况下,当在输入和输出中遇到换行符时,标准I/O库函数将会执行系统调用操作。当所操作的流涉及一个终端时(例如标准输入和标准输出),使用行缓冲方式。因为标准I/O库每行的缓冲区长度是固定的,所以只要填满了缓冲区,即使还没有遇到换行符,也会执行I/O系统调用操作,默认行缓冲区的大小为1024。
- 无缓冲区:无缓冲区是指标准I/O库不对字符进行缓存,直接调用系统调用。标准出错流stderr通常是不带缓冲区的,这使得出错信息能够尽快地显示出来。
除了上述列举的默认刷新方式,下列特殊情况也会引发缓冲区的刷新:
- 缓冲区满时;
- 执行flush语句;
验证stderr不带缓冲区:
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
close(2);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");return 0;
}
perror("hello world");
close(fd);
return 0;
}

为什么要有缓冲区:
当读写文件时,若不开辟操作缓冲区,直接通过系统调用(如read/write)对磁盘进行操作,会面临显著的效率问题:每次读写操作都需执行一次系统调用,而执行系统调用必然涉及 CPU 状态切换 —— 从用户空间切换到内核空间,完成进程上下文的切换。这一过程会损耗一定的 CPU 时间,若存在频繁的磁盘访问(如高频读写小文件),会对程序的整体执行效率造成很大影响。
为减少系统调用次数、提升效率,缓冲机制应运而生。其核心逻辑如下:在对磁盘文件操作时,可一次性从文件中读出大量数据到缓冲区(或一次性将大量数据写入缓冲区),后续对这部分数据的访问无需再触发系统调用;仅当缓冲区数据被耗尽(读操作)或填满(写操作)时,才再次通过系统调用与磁盘交互。
这种设计的效率增益来自两方面:
- 大幅减少磁盘读写次数,降低系统调用带来的 CPU 状态切换损耗;
- 计算机对内存中缓冲区的操作速度,远快于对物理磁盘的读写速度,进一步提升整体运行效率。
5.2.系统调用与库函数
open/read/write 与 fopen/fread/fwrite 的核心区别是所属层级不同:前者是 Linux 系统调用(直接操作内核),后者是 C 标准库函数(基于系统调用封装,带缓冲机制),具体差异可从 5 个维度对比:
1. 所属层级与依赖
open/read/write:仅依赖 Linux 内核,移植性差,操作对象为文件描述符
fopen/fread/fwrite:依赖 C 标准库,可跨平台,文件指针(FILE* 类型,封装了文件描述符和缓冲)
2. 缓冲机制(关键差异)
这是两者最核心的区别,直接影响性能和使用场景:
open/read/write:无缓冲,每次调用都会直接触发内核的 I/O 操作(读 / 写磁盘或设备)。例如:用 write 写 100 次 1 字节数据,会触发 100 次内核 I/O,频繁调用时性能低(内核态与用户态切换开销大)。
fopen/fread/fwrite:有缓冲,C 标准库会在用户态维护一个 缓冲区(默认通常 4KB 或 8KB),读写先操作缓冲区,满足条件后才触发内核 I/O:
- 写操作:数据先存到缓冲区,缓冲区满 / 调用 fflush/ 关闭文件时,才一次性写入内核;
- 读操作:一次性从内核读一批数据到缓冲区,后续 fread 直接从缓冲区取,减少内核调用。
例如:用 fwrite 写 100 次 1 字节数据,可能只触发 1 次内核 I/O(缓冲区满后写入),性能更高。
3. 函数参数与返回值
int open(const char* path, int flags, mode_t mode)
成功返回 文件描述符(正整数),失败返回 -1
FILE* fopen(const char* path, const char* mode)
成功返回 文件指针(FILE*),失败返回 NULL
ssize_t read(int fd, void* buf, size_t count)
成功返回 实际读取字节数,失败返回 -1,0 表示读到文件尾
size_t fread(void* buf, size_t size, size_t nmemb, FILE* stream)
成功返回 实际读取的 “数据块个数”(不是字节数,需乘以 size 得总字节数),失败 / 到文件尾返回 0
ssize_t write(int fd, const void* buf, size_t count)
成功返回 实际写入字节数,失败返回 -1
size_t fwrite(const void* buf, size_t size, size_t nmemb, FILE* stream)
成功返回 实际写入的 “数据块个数”,失败返回 0
4. 关闭与错误处理
关闭文件:
- open 打开的文件用 close(fd) 关闭;
- fopen 打开的文件用 fclose(fp) 关闭(会自动刷新缓冲区并释放资源)。
错误处理:
- open/read/write 失败时,通过 errno 变量存储错误码(需包含 <errno.h>),用 perror() 打印错误信息;
- fopen/fread/fwrite 失败时,部分实现会设置 errno,也可通过 ferror() 检查文件操作错误。
6.FILE
FILE 结构体是对文件操作的抽象封装,因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过fd 访问的。 所以C库当中的FILE结构体内部,必定封装了fd。
FILE 本质是 struct _IO_FILE 的 typedef 别名,其内部关键成员可归纳为三类:底层文件描述符(fd),缓冲区管理(核心优化点),文件状态与控制信息
#include <stdio.h>
#include <string.h>
int main()
{
const char *msg0="hello printf\n";
const char *msg1="hello fwrite\n";
const char *msg2="hello write\n";
printf("%s", msg0);
fwrite(msg1, strlen(msg0), 1, stdout);
write(1, msg2, strlen(msg2));
fork();
return 0;
}

如果对进程实现输出重定向,结果变成了 printf 和 fwrite (库函数)都输出了2次
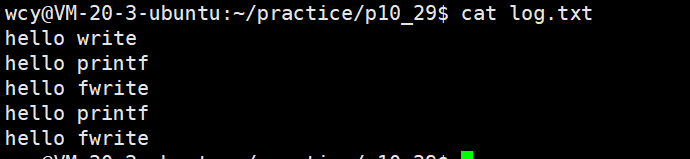
为什么呢?肯定和fork有关!
一般 C 库函数的缓冲行为会根据输出目标变化:写入文件时采用全缓冲,写入显示器时采用行缓冲。
printf、fwrite 这类 C 库函数会自带缓冲区。当输出重定向到普通文件时,缓冲方式会从行缓冲切换为全缓冲:
- 此时缓冲区中的数据不会被立即刷新到文件,即便调用 fork 创建子进程,缓冲数据也仍暂存在用户态内存中;
- 只有当进程退出时,C 库才会自动统一刷新缓冲区,将数据写入文件;
- 但 fork 会触发 “写时拷贝” 机制:父进程的内存空间(包括 C 库缓冲区)会被子进程共享,一旦父进程准备刷新缓冲区(修改缓冲数据状态),子进程会复制一份相同的缓冲数据。最终父、子进程退出时各自刷新,文件中就会出现两份相同数据;
而 write 系统调用没有这种现象,恰好说明它不存在用户态缓冲区,调用时会直接将数据写入内核,不受 fork 写时拷贝的影响。

















 5万+
5万+




 到【灌水乐园】发言
到【灌水乐园】发言







