



配置VirtualBox
新建一个虚拟机
ps:步骤可参照我之前博客
一、安装准备
jdk-8u221-linux-x64.tar
hadoop-2.6.0-cdh5.14.2.tar.gz
ps:如何配置jdk可参照我之前的博客jdk安装配置这里就不一一赘述了
话不多说我们直接开始
切换至software 文件目录: cd /software
将准备好的文件拖入software 目录下
将文件解压至 opt目录下:tar -zxf hadoop-2.6.0-cdh5.14.2.tar.gz -C/opt
切换至opt 目录:cd /opt
将hadoop-2.6.0-cdh5.14.2.tar.gz改名为hadoop: mv hadoop-2.6.0-cdh5.14.2/ hadoop
修改主机名 : hostnamectl set-hostname hadoop101
修改主机列表:vi /etc/hosts 为:192.168.56.111 hadoop101
二、配置Hadoop目录下的文件
修改 vi slaves (努力节点) 名称 为hadoop101

切换至hadoop目录:cd /opt/hadoop/etc/hadoop
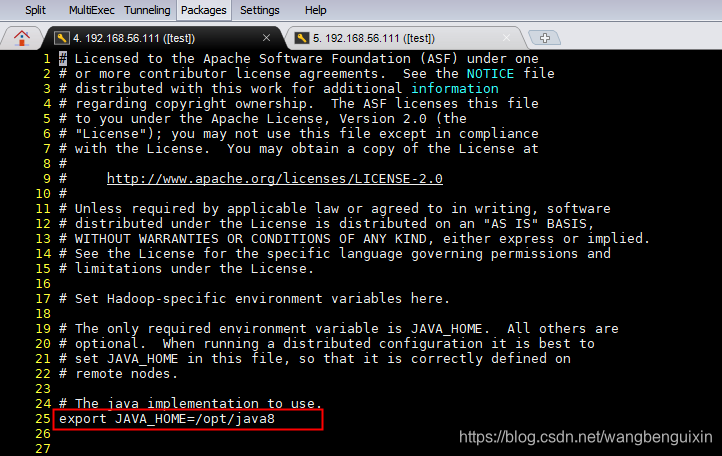
(1)修改hadoop-env.sh配置文件:vi hadoop-env.sh
修改安装路径为 /opt/java8
ps路径:为jdk安装路径,我这里将jdk-8u221-linux-x64.tar改名为了java8 你们可根据情况自行调整;
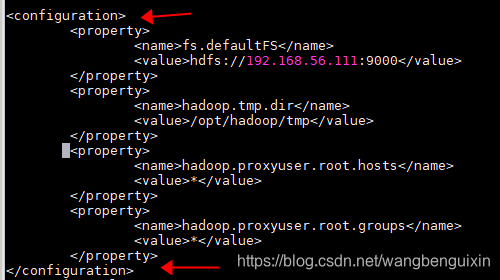
(2)修改core-site.xml配置文件信息:vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.56.111:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
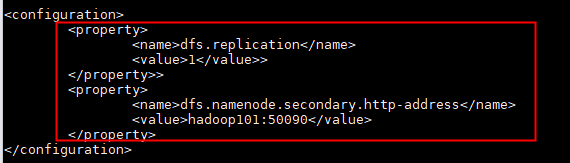
(3)修改hdfs-site.xml配置文件:vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop101:50090</value>
</property>
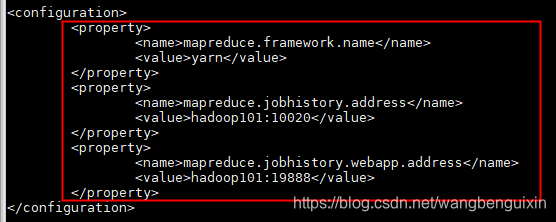
(4)修改mapred-site.xml配置文件 :vi mapred-site.xml
在个文件的全名应该是mapred-site.xml.template 为方便修改 这里给它改个名
mv mapred-site.xml.template mapred-site.xml.
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop101:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop101:19888</value>
</property>
(5)修改yarn-site.xml配置文件 vi yarn-site.xml
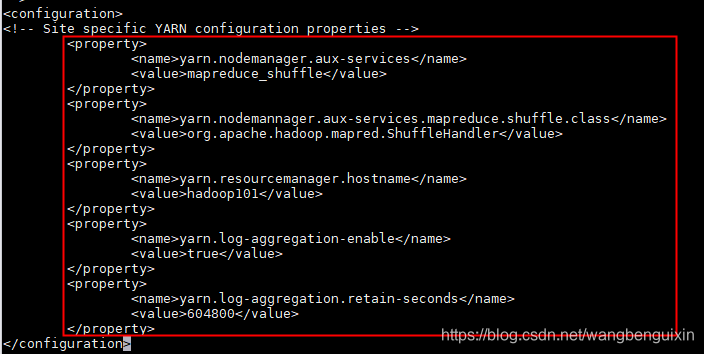
<!-- reducer获取数据方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemannager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
<!-- 日志聚集功能使用 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
三、Hadoop环境变量配置
配置Hadoop环境变量 :vi /etc/profile
shift + g 跳转最后一行 o 下一行插入:
export HADOOP_HOME=/opt/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
保存退出;
使配置文件即时生效:source /etc/profile
四、格式化HDFS
hadoop namenode -format
五、启动hadoop
start-all.sh
启动历史服务:mr-jobhistory-daemon.sh start historyserver

六、 查看启动是否成功
打开浏览器在地址栏输入
ps:注意区分中英文字符
(1)http://192.168.56.111:50070 HDFS页面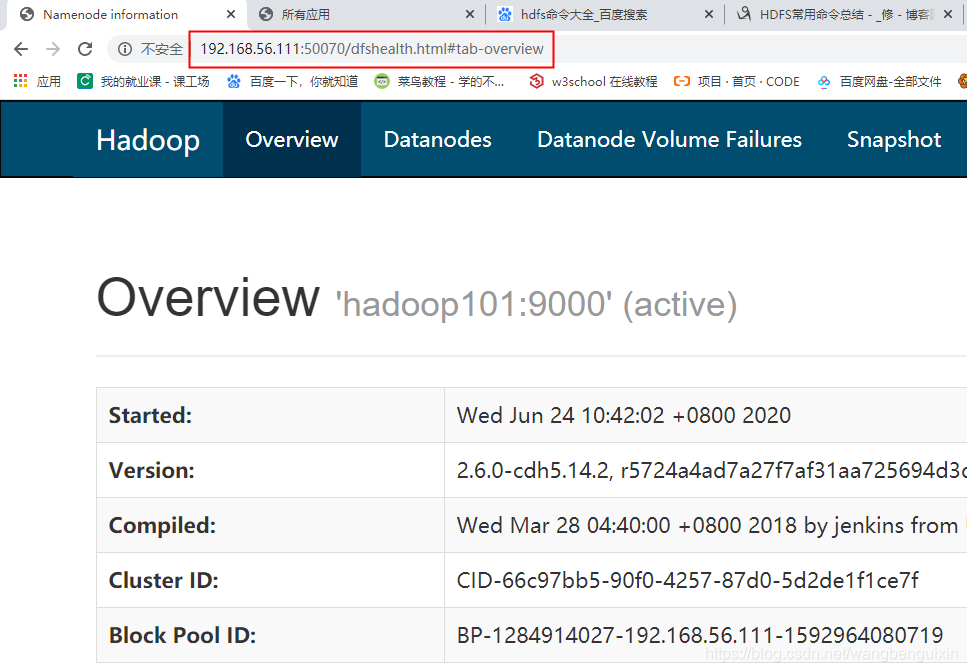
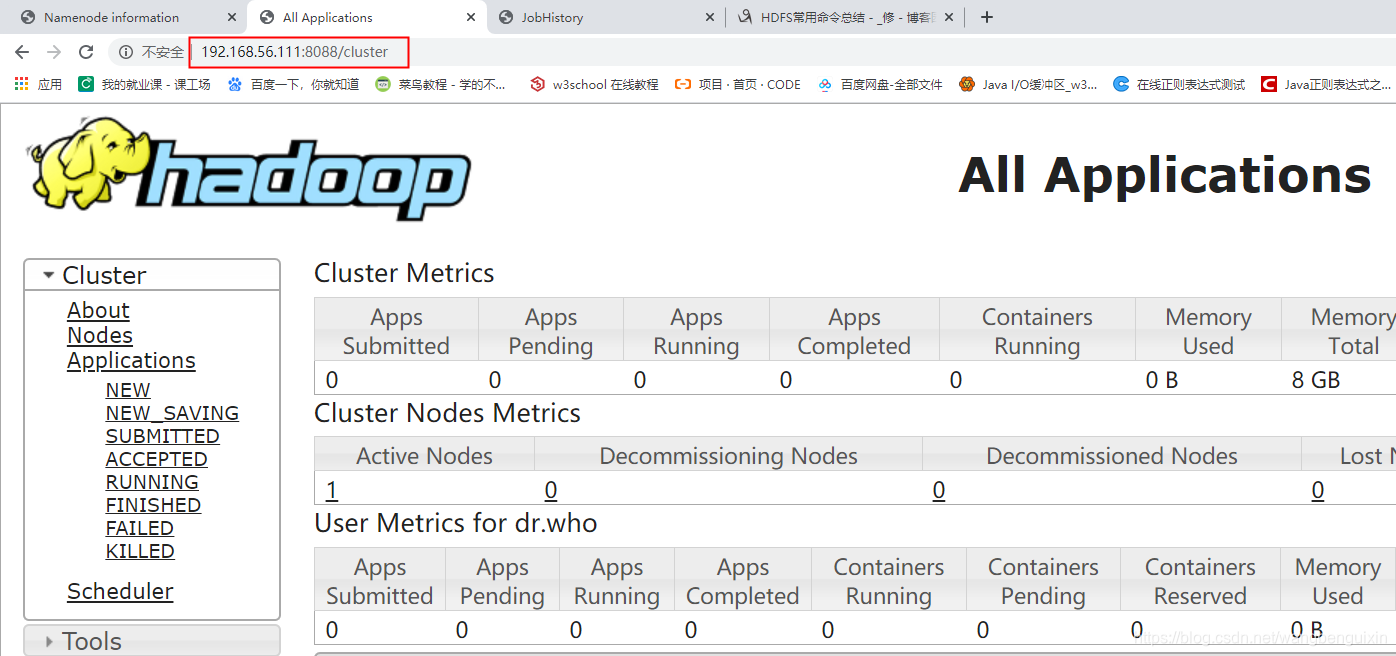
(2)http://192.168.56.111:8088 YARN的管理界面
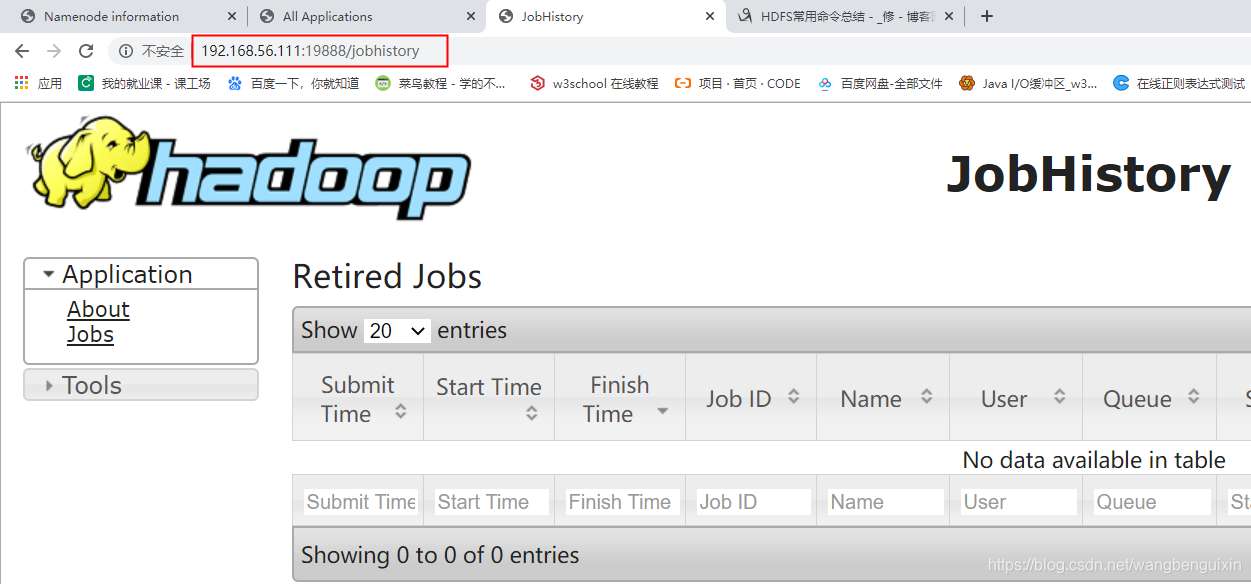
(3)http://192.168.56.111:19888/
ps:jps可以查看hadoop进程 有针对性地查看哪边的配置文件未生效
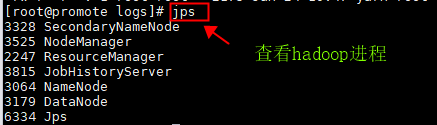
jps遇到启动的服务缺少时:
1、查看对应的log文件,查看报错原因
关闭进程:stop-all.sh
2、确定莫蒙提,可以删除hadoop目录下的tmp目录删除
切换到hadoop目录:cd /opt/hadoop
删除tmp目录:rm -rf tmp
3、重新format(执行格式化命令:hadoop namenode -format)
4、重新启动hadoop:start-all.sh

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









