 Pycharm运行tensorrt库报错解决
Pycharm运行tensorrt库报错解决




1. import tensorrt报错问题
在使用命令行运行如下代码,主要是使用了tensorrt库,能正常输出,但使用pycharm运行时报错。
import os
import numpy as np
import tensorrt as trt
from cuda import cudart
trt_file = "model.trt"
data = np.arange(3 * 4 * 5, dtype=np.float32).reshape(3, 4, 5) # input data for inference
def run():
logger = trt.Logger(trt.Logger.ERROR) # create Logger, available level: VERBOSE, INFO, WARNING, ERROR, INTERNAL_ERROR
if os.path.isfile(trt_file): # load serialized network and skip building process if .trt file existed
with open(trt_file, "rb") as f:
engineString = f.read()
if engineString == None:
print("Fail getting serialized engine")
return
print("Succeed getting serialized engine")
else: # build a serialized network from scratch
builder = trt.Builder(logger) # create Builder
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)) # create Network
profile = builder.create_optimization_profile() # create Optimization Profile if using Dynamic Shape mode
config = builder.create_builder_config() # create BuidlerConfig to set meta data of the network
config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 1 << 30) # set workspace for the optimization process (default value is total GPU memory)
inputTensor = network.add_input("inputT0", trt.float32, [-1, -1, -1]) # set input tensor of the network
profile.set_shape(inputTensor.name, [1, 1, 1], [3, 4, 5], [6, 8, 10]) # set dynamic shape range of the input tensor
config.add_optimization_profile(profile) # add the Optimization` Profile into the BuilderConfig
identityLayer = network.add_identity(inputTensor) # here is only a identity transformation layer in our simple network, which the output is exactly equal to input
network.mark_output(identityLayer.get_output(0)) # mark the output tensor of the network
engineString = builder.build_serialized_network(network, config) # create a serialized network from the network
if engineString == None:
print("Fail building serialized engine")
return
print("Succeed building serialized engine")
with open(trt_file, "wb") as f: # save the serialized network as binaray file
f.write(engineString)
print("Succeed saving .trt file")
engine = trt.Runtime(logger).deserialize_cuda_engine(engineString) # create inference engine using Runtime
if engine == None:
print("Fail building engine")
return
print("Succeed building engine")
nIO = engine.num_io_tensors # since TensorRT 8.5, the concept of Binding is replaced by I/O Tensor, all the APIs with "binding" in their name are deprecated
lTensorName = [engine.get_tensor_name(i) for i in range(nIO)] # get a list of I/O tensor names of the engine, because all I/O tensor in Engine and Execution Context are indexed by name, not binding number like TensorRT 8.4 or before
nInput = [engine.get_tensor_mode(lTensorName[i]) for i in range(nIO)].count(trt.TensorIOMode.INPUT) # get the count of input tensor
#nOutput = [engine.get_tensor_mode(lTensorName[i]) for i in range(nIO)].count(trt.TensorIOMode.OUTPUT) # get the count of output tensor
context = engine.create_execution_context() # create Execution Context from the engine (analogy to a GPU context, or a CPU process)
context.set_input_shape(lTensorName[0], [3, 4, 5]) # set actual size of input tensor if using Dynamic Shape mode
for i in range(nIO):
print("[%2d]%s->" % (i, "Input " if i < nInput else "Output"), engine.get_tensor_dtype(lTensorName[i]), engine.get_tensor_shape(lTensorName[i]), context.get_tensor_shape(lTensorName[i]), lTensorName[i])
bufferH = [] # prepare the memory buffer on host and device
bufferH.append(np.ascontiguousarray(data))
for i in range(nInput, nIO):
bufferH.append(np.empty(context.get_tensor_shape(lTensorName[i]), dtype=trt.nptype(engine.get_tensor_dtype(lTensorName[i]))))
bufferD = []
for i in range(nIO):
bufferD.append(cudart.cudaMalloc(bufferH[i].nbytes)[1])
for i in range(nInput): # copy input data from host buffer into device buffer
cudart.cudaMemcpy(bufferD[i], bufferH[i].ctypes.data, bufferH[i].nbytes, cudart.cudaMemcpyKind.cudaMemcpyHostToDevice)
for i in range(nIO):
context.set_tensor_address(lTensorName[i], int(bufferD[i])) # set address of all input and output data in device buffer
context.execute_async_v3(0) # do inference computation
for i in range(nInput, nIO): # copy output data from device buffer into host buffer
cudart.cudaMemcpy(bufferH[i].ctypes.data, bufferD[i], bufferH[i].nbytes, cudart.cudaMemcpyKind.cudaMemcpyDeviceToHost)
for i in range(nIO):
print(lTensorName[i])
print(bufferH[i])
for b in bufferD: # free the GPU memory buffer after all work
cudart.cudaFree(b)
if __name__ == "__main__":
os.system("rm -rf *.trt")
run() # create a serialized network of TensorRT and do inference
run() # load a serialized network of TensorRT and do inference
报错截图

问题解决
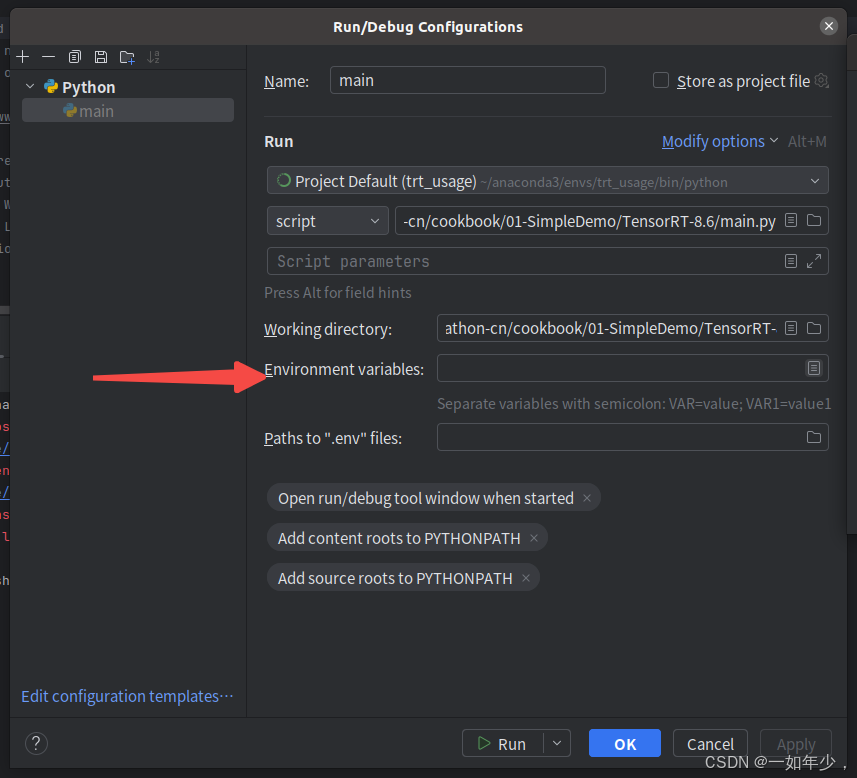
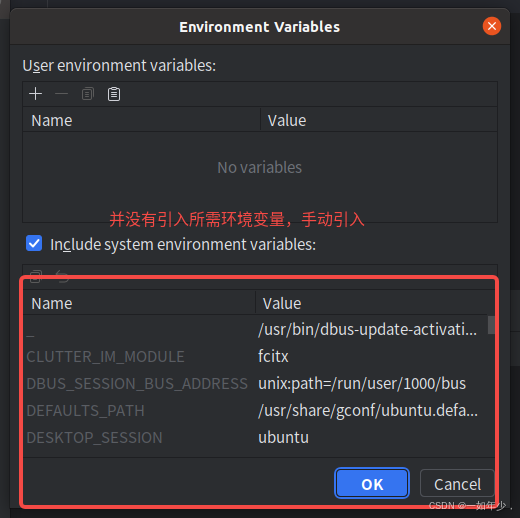
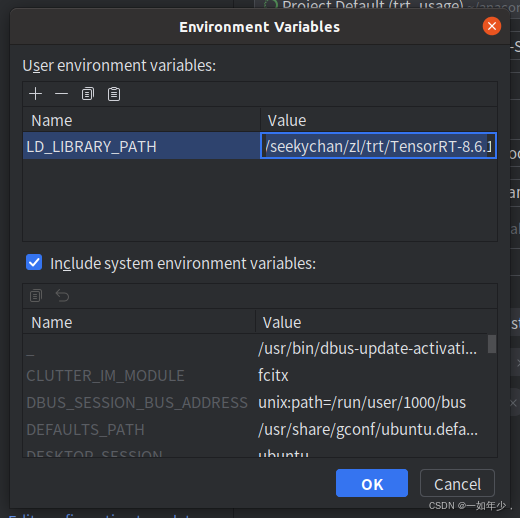
- 打开运行配置,发现并没有引入LD_LIBRARY_PATH环境变量,手工将环境变量引入,再次运行,完成。


















 1687
1687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









