






 本文详细介绍了Spark的部署方式(Local、Standalone、Yarn),提交作业的参数设置,以及Spark的架构、作业提交流程、血统概念和宽窄依赖。重点讲解了Executor和Driver的资源配置,以及Stage和Task的划分机制。
本文详细介绍了Spark的部署方式(Local、Standalone、Yarn),提交作业的参数设置,以及Spark的架构、作业提交流程、血统概念和宽窄依赖。重点讲解了Executor和Driver的资源配置,以及Stage和Task的划分机制。
一、Spark有几种部署方式?
1、Local:运行在一台机器上,通常是练手后者测试环境
2、Standalone:构建一个基于Master+Slaves的资源调度集群,Spark任务提交给Master运行。是Spark 自身的一个调度系统。
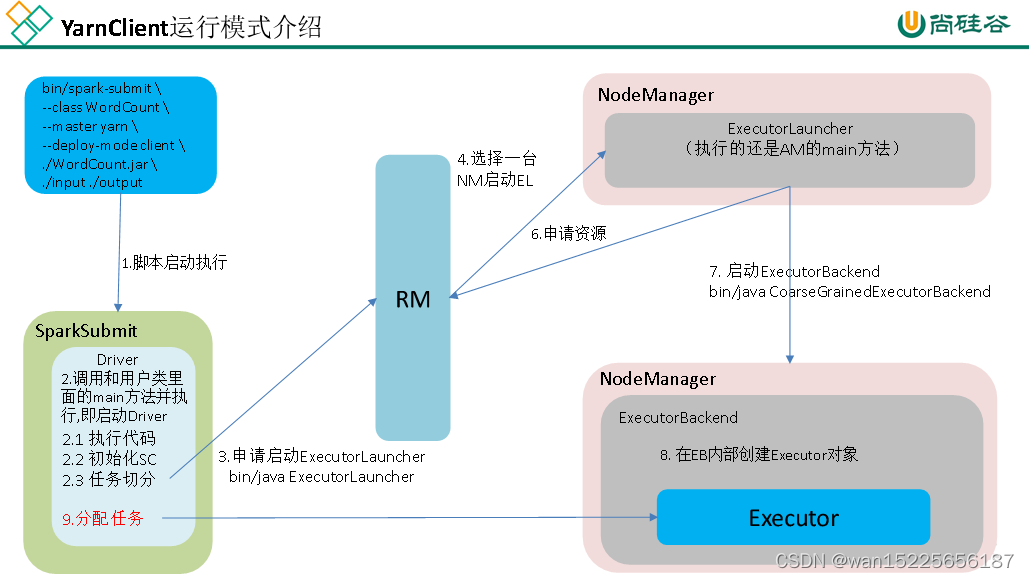
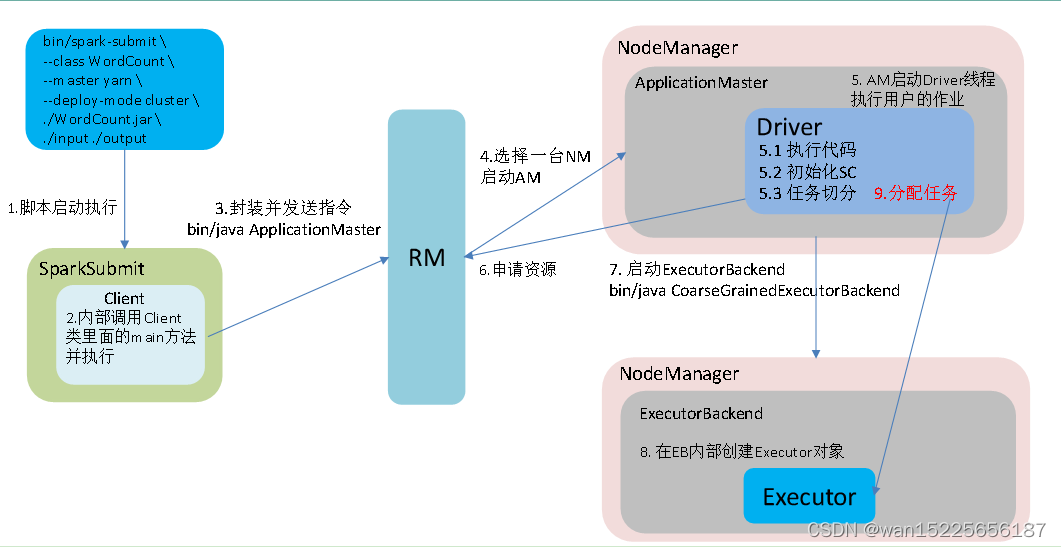
3、Yarn:Spark客户端直接连接Yarn,不需要额外构建Spark集群。优 Yarn-client 和Yarn-cluster 两种模式,主要区别在于:Driver程序的运行节点。
二、Spark任务使用的什么进行提交,JavaEE界面还是脚本?
shell脚本。(一般调度使用Azkaban、Airflow、Oozie)
三、Spark提交作业的参数
1、提交任务是的几个重要参数
executor-cores —— 每个executor 使用的内核数,默认为1,官方建议 2~5 个。
num-executors —— 启动executors的数量,默认为 2 。
executor-memory —— executor 内存大小 ,默认是 1G
driver-cores —— driver 使用内核数,默认是1
driver-memory —— driver内存大小,默认 512M
2、一个提交任务的样式
spark-submit \
--master local[5] \ (本地模式)
--driver-cores 2 \ (Drive使用内核数)
--driver-memory 8g \ (Drive内存大小)
--executor-cores 4 \ (每个executor使用的内核数【官方建议2~5个】)
--num-executors 10 \ (启动executors的数量)
--executor-memory 8g \ (executor内存大小)
--class PackageName.ClassName XXXX.jar \
--name "Spark Job Name" \
InputPath \
OutputPath
四、简述Spark的架构与作业提交流程
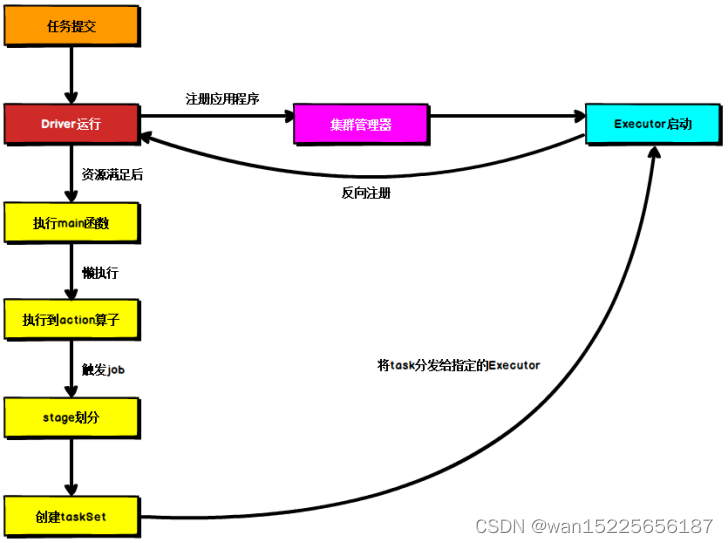
不论Spark以任何模式进行部署,任务提交后,都会先启动Driver进程,随后Driver进程向集群管理器注册应用程序,之后集群管理器根据此任务的配置文件分配Executor 并启动,当Driver所虚的资源全部满足后,Driver开始执行 main 函数,Spark查询为懒执行,当执行到Action算子的时候开始反向推算,根据宽依赖进行stage的划分,随后每一个stage对应一个taskset,taskset中有多个task,根据本地化原则,task会被分发到指定的Executor去执行,在任务执行过程中,Excutor也会不断与Driver进行通信,报告任务运行情况。
五、如何理解Spark中的血统概念
RDD在Lineage 依赖方面分为两种 Narrow Dependencies 与 Wide Dependencies 用来解决数据容错是的高效性以及划分任务时候起到的重要作用。
六、简述Spark的宽窄依赖,以及Spark如何划分stage,每个stage又根据什么决定task的个数?
Stage:根据RDD之间的依赖关系不同将job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。
Task:Stage是一个TaskSet,将Stage根据分区划分成一个个的Task。

















 8695
8695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









