




 文章介绍了MyCAT的逻辑库与逻辑表概念,包括分片表和非分片表的差异,以及MyCAT的核心配置如server.xml、schema.xml等。重点讨论了分片策略,如全局表的特点和E-R分片,以及垂直拆分和水平拆分的原理。此外,文章还提到了常见的分片规则和MyCAT的读写分离实战,包括不同balance值的影响。最后,讨论了全局序列号的几种生成方式及其优缺点。
文章介绍了MyCAT的逻辑库与逻辑表概念,包括分片表和非分片表的差异,以及MyCAT的核心配置如server.xml、schema.xml等。重点讨论了分片策略,如全局表的特点和E-R分片,以及垂直拆分和水平拆分的原理。此外,文章还提到了常见的分片规则和MyCAT的读写分离实战,包括不同balance值的影响。最后,讨论了全局序列号的几种生成方式及其优缺点。
1.mycat逻辑库与逻辑表
逻辑库(schema) : 由一个或多个数据库集群构成的虚拟数据库,用于mycat直连操作数据库
逻辑表(table): 逻辑库下读写数据的表就是逻辑表,可以是数据切分后,分布在一个或多个分片库中。也可以不做数据切分,不分片,只有一个表构成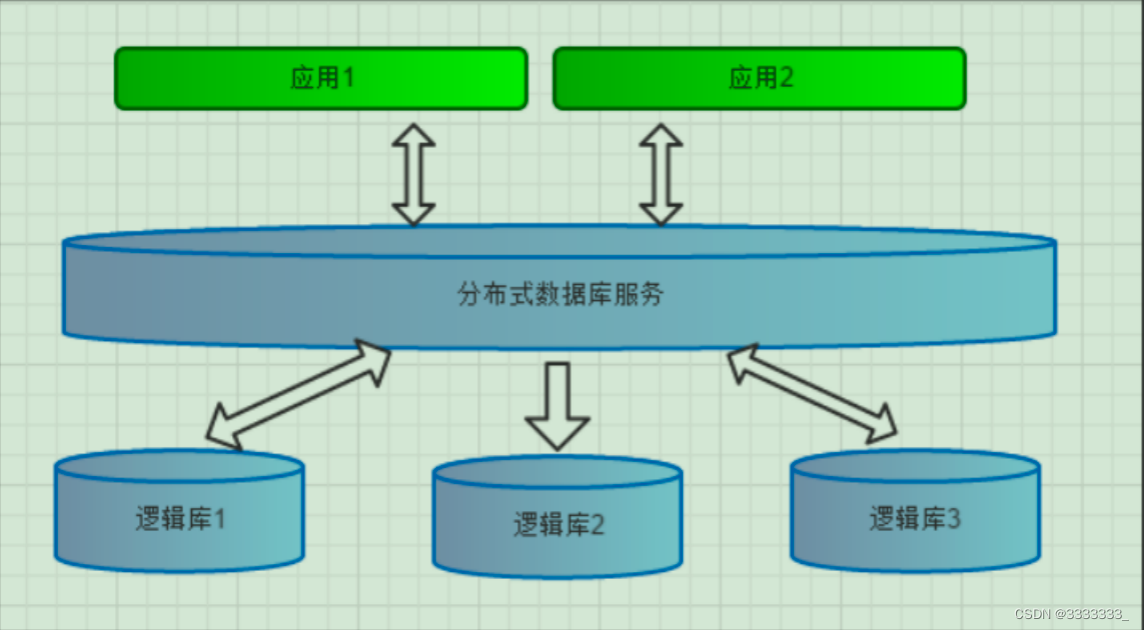
2.mycat分片表与非分片表
分片表: 是指原有的很大数据的表,需要切分到多个数据库的表
非分片表: 即不需要进行数据切分的表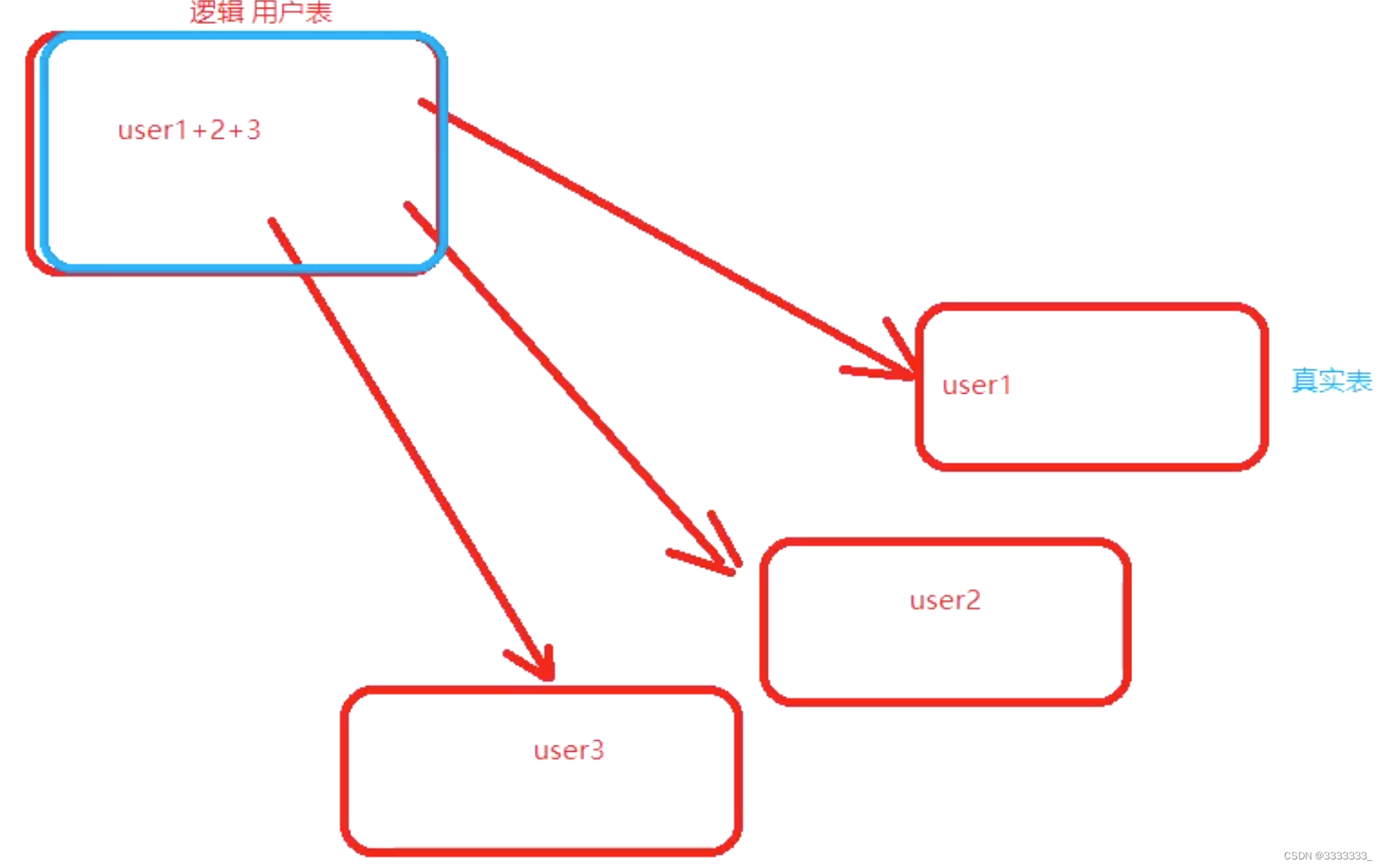
3.MyCAT核心配置
server.xml
<system><property name= "" ></property></system>用于定义系统配置
<user> </user> 用于定义连接MyCAT的用户
schema.xml
<schema> <table> </table> </schema> 定义逻辑库、表
<dataNode> </dataNode> 定义分片节点
<dataHost> </dataHost> 定义分片节点的物理数据源
rule.xml
<tableRule name=> </tableRule> 定义表使用的分片规则
<function name=> </function> 定义分片算法
4.1分片策略
全局表 :类似字典表,存储与业务表之间可能有关系,可以理解为"标签" ,这些表基本上很少变动,可以根据主键ID进行缓存
4.2 全局表特点
全局表特性:
变动不频繁;
数据量总体变化不大;
数据规模不大,很少有超过数十万条记录
全局表操作特点:
全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
全局表的查询操作,只从一个节点获取
全局表可以跟任何一个表进行JOIN操作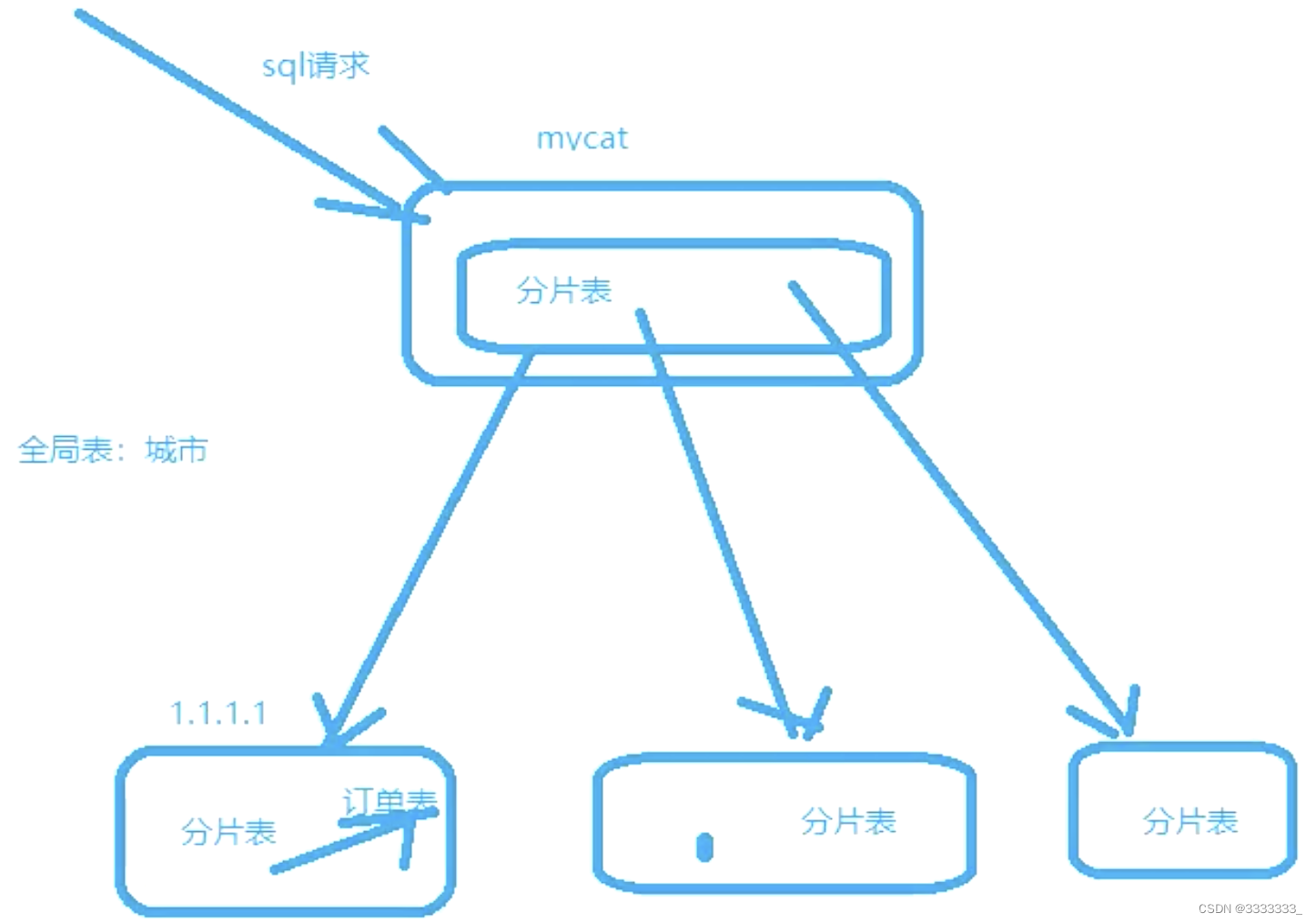
4.3 E-R分片
E-R分片:子表的记录与所关联的父表记录存放在同一个数据分片上,即子表依赖于父表
<table name="customer" dataNode="dn1,dn2" rule="sharding-by-intfile">
<childTable name="orders" joinKey="customer_id" parentKey="id"/>
</table>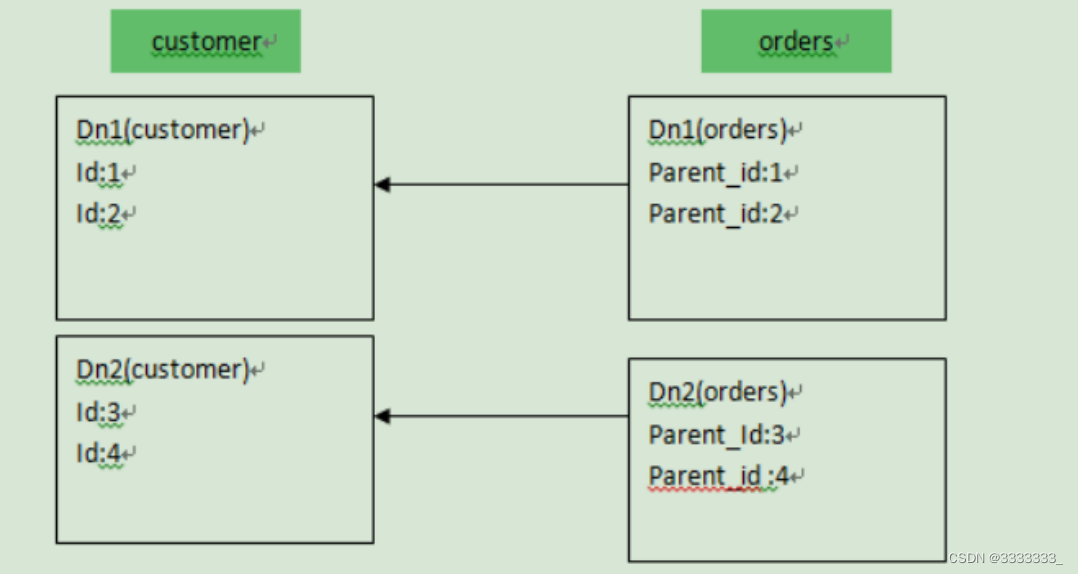
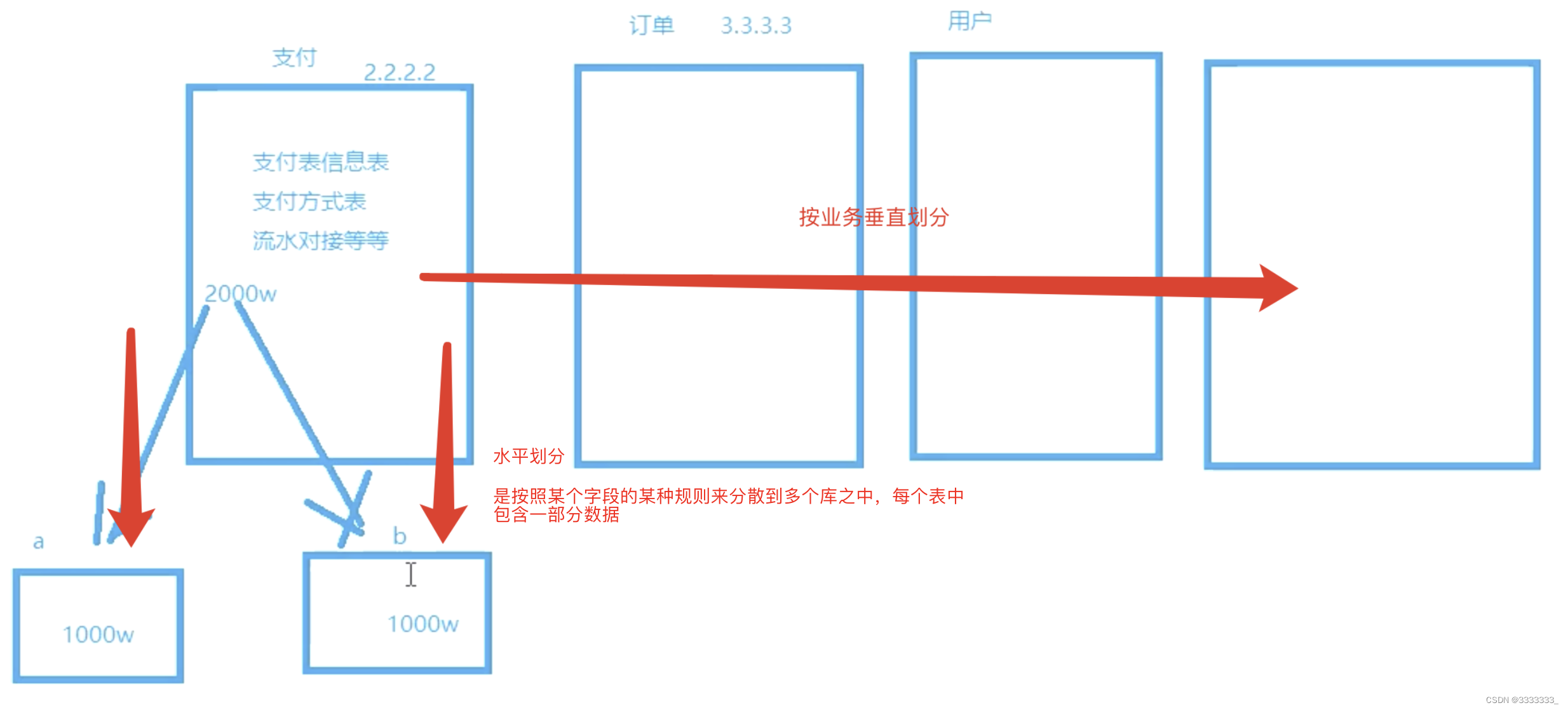
5. MyCAT垂直拆分原理解析
垂直拆分:按照业务需求把数据拆分到不同数据节点
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="customer" dataNode="dn1" rule="auto-sharding-long" > </table>
<table name="goods" dataNode="dn2" rule="auto-sharding-long" > parentKey= "id"/> </table>
</schema>6. MyCAT水平拆分原理解析
水平拆分:根据分片规则,把数据拆分到不同分片表下
父子表关系: goods.id =order_info.order_id
joinKey: 分片表的外键字段
primaryKey: 分片表主键
parentKey:父表的外键字段
7.常见分片规则
hash:
-
- 取模 mod-long
- 一致性 hash murmur
- 取模范围约束 sharding-by-pattern
- crc32slot 分片算法 crc32solt 是有状态分片算法的实现之一,数据自动迁移方案设计
范围:
-
- 范围约定 rang-long (提前规划好分片字段某个范围属于哪个分片)
- 分片枚举 hash-int
- 范围求模分片 rang-mod
7.1常见分片规则
按日期(天)分片 sharding-by-date
按单月小时拆分 sharding-by-hour
日期范围 hash 分片 range-date-hash
冷热数据分片: sharding-by-hotdate
8. MyCAT读写分离实战
读负载: 读写分离配置在writeHost下进行处理:
balance 负载均衡属性,目前的取值有 3 种:
1. balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上
2. balance="1", 全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡
3. balance="2",所有读操作都随机的在 writeHost、readhost 上分发 4. balance="3",所有读请求随机的分发到 wiriterHost 对应的 readhost 执行,writerHost 不负担读压力
注意 balance=3 只在 1.4 及其以后版本有,1.3 没有
9. MyCAT写负载
写负载: 负载均衡类型,目前的取值有 3 种:
1. writeType="0", 所有写操作发送到配置的第一个 writeHost,第一个挂了切到还生存的第二个 writeHost 重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties
2. writeType="1",所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐
3. writeType= "2", 基于 MySQL 主从同步的状态决定是否切换。
17.全局序列号
全局ID方式:
server.xml 中配置:
0
1 本地文件方式
缺点:当 MyCAT 重新发布后,配置文件中的 sequence 会恢复到初始值。
优点:本地加载,读取速度较快 1
2 数据库方式
优点:主从切换后,ID的插入互不影响
缺点:并发场景下数据库压力大,系统较复杂
3 本地时间戳方式
优点:ID生成快速,并发好
缺点:mycat需要配置高可用,做好数据备份
4 分布式 ZK ID 生成器
优点:ID生成效率快,系统解耦
缺点:整体架构系统负责,zk需要保证高可用

















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









