




 本文介绍了MySQL的三层逻辑架构,详细阐述了从客户端请求到数据存储的整个流程,重点关注查询优化器如何选择最优执行路径。
本文介绍了MySQL的三层逻辑架构,详细阐述了从客户端请求到数据存储的整个流程,重点关注查询优化器如何选择最优执行路径。
流程图
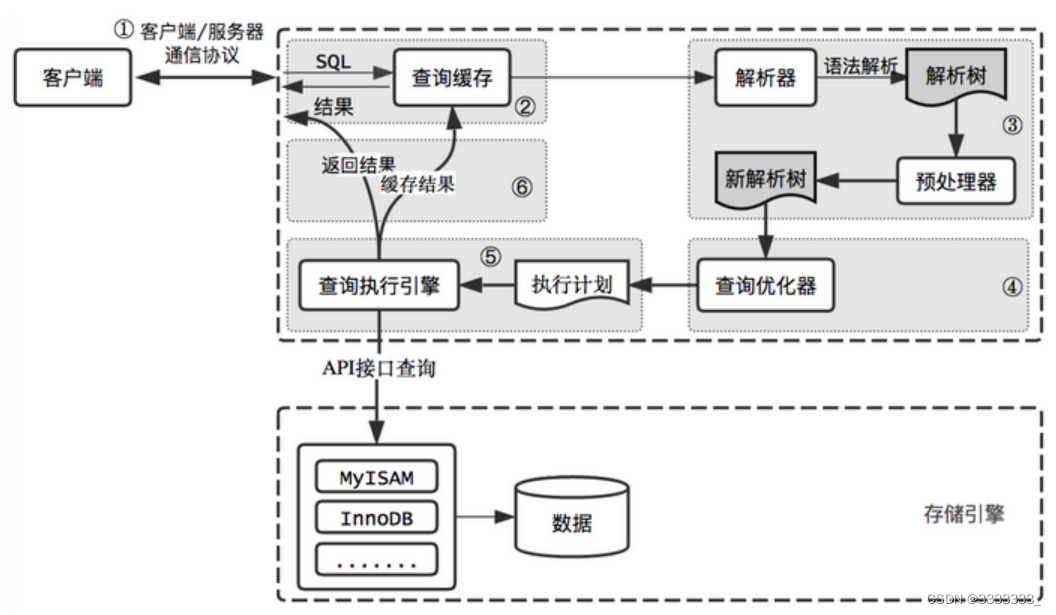
MySQL 逻辑架构
MySQL的逻辑架构整体分为三层
最上层:这一层为客户端层,并非 MySQL 所独有,诸如:连接处理、授权认证、安全等功能均在这一层处理。
中间层:MySQL大多数核心服务均在这一层,包括查询解析、分析、优化、缓存、内置函数(比如:时间、数学、加密等函数)。所有的跨存储引擎的功能也在这一层实现:存储过程、触发器、视图等。
最下层:这一层为存储引擎,其负责MySQL中的数据存储和提取。和Linux下的文件系统类似,每种存储引擎都有其优势和劣势。中间的服务层通过API与存储引擎通信,这些API接口屏蔽了不同存储引擎间的差异。
详解步骤
- 当我们请求mysql服务器的时候,MySQL前端会有一个监听,请求到了之后,服务器得到相关的SQL语句,执行之前(虚线部分为执行),还会做权限的判断
- 通过权限之后,SQL就到MySQL内部,他会在查询缓存中,看该SQL有没有执行过,如果有查询过,则把缓存结果返回,说明在MySQL内部,也有一个查询缓存.但是这个查询缓存,默认是不开启的,这个查询缓存,和我们的Hibernate,Mybatis的查询缓存是一样的,因为查询缓存要求SQL和参数都要一样,所以这个命中率是非常低的(没什么卵用的意思)
- 如果我们没有开启查询缓存,或者缓存中没有找到对应的结果,那么就到了解析器,解析器主要对SQL语法进行解析
- 解析结束后就变成一颗解析树,这个解析树其实在Hibernate里面也是有的,大家回忆一下,在以前做过Hibernate项目的时候,是不是有个一个antlr.jar。这个就是专门做语法解析的工具.因为在Hibernate里面有HQL,它就是通过这个工具转换成SQL的,我们编程语言之所以有很多规范、语法,其实就是为了便于这个解析器解析,这个学过编译原理的应该知道.
- 得到解析书之后,不能马上执行,还需要对这棵树进行预处理,比如常量放在什么地方,如果有计算把计算结果算出来等等
- 预处理完毕之后,会得到一棵比较规范的树,这棵树就是要去执行的树,比起之前的那棵树得到了一些优化
- 再就是进入"查询优化器",这个是MySQL里面最关键的东西。我们写任何一条SQL,比如select * from user where user = bob and password = mypass。它会怎么去执行呢?是先执行user=bob还是password=mypass?每一条SQL的执行顺序"查询优化器"就是根据MySQL对数据统计表的一些信息,比如索引,比如表一共有多少数据,MySQL都是有缓存起来的,在真正执行SQL之前,它会根据自己的这些数据,进行一个综合的判定,判断这一次在多种执行方式里面到底选哪一种执行方式,可能运行的最快,这一步是MySQL性能中,最关键的核心点,也就是我们的优化原则。我们平时所说的优化SQL,其实说白了就是想让”查询优化器“按照我们的想法,帮我们选择最优的执行方案,因为我们比MySQL更懂我们的数据,MySQL看数据,静静只是自己收集到的信息,这些信息可能是不准确的,mysql根据这些信息选择了一个它自认为最优的方案,但是这个方案可能和我们想象的不一样。
- 再就是进入查询执行计划,也就是MySQL查询中的执行计划,比如是先执行user=bob还是password=mypass
- 这个执行计划会传给查询执行引擎,执行引擎选择存储引擎来执行这一份传过来的计划,到磁盘中的文件去查询,这个时候重点来了。影响这个查询性能最根本的原因是什么?就是硬盘的机械运动,也就是我们平时熟悉的IO,所以一条查询语句是快还是慢,就是根据这个IO的时间来确定的,那怎么执行IO有事什么来确定的呢?就是传过来的这一份执行计划!
- 如果开了查询缓存,则返回结果给客户端,并且查询缓存也会存一份

















 2247
2247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









