



SAMURAI
SAM2在处理快速移动和存在自遮挡对象的拥挤场景时存在局限性,此外原始SAM2中未考虑fixed-window的内存方法未考虑为下一帧选择调整内图像特征的内存质量,从而导致视频中出现错误传播。
本文提出的SAMURAI通过将时间运动线索与所提出的运动感知记忆选择机制相结合,SAMURAI有效地预测物体运动并细化mask的选择,实现鲁棒、准确的跟踪,而不需要重新训练或微调。
Introduction
在这里插入图片描述
尽管在视觉目标跟踪任务(VOT)中存在遮挡、外观变化和相似目标存在等挑战,但是VOT的主要关注点是保持一致的id和位置。然而SAM2在预测后续帧的mask时,经常忽略运动信息,导致目标在快速移动或交互复杂的情况下不准确,在目标拥挤的场景中这种现象尤为明显,而SAM2倾向于优先考虑目标的外观相似性,而不是空间和时间的一致性,最终导致了跟踪错误。
为了解决这一问题,我们提出将运动信息融合到SAM2的预测过程中,通过利用物体的历史运动轨迹,增强模型对于遮挡的相似物体间的跟踪能力。此外,当前方法中直接选择储存最近帧的方法在遮挡过程中引入了不相关的特征,影响了跟踪性能,因此也需要对SAM2的内存管理进行优化。
贡献点:
- 改进了mask选择的运动模型系统,在复杂场景中提高了跟踪性能
- 利用混合评分系统优化内存选择机制,结合原有的mask,目标和运动评分以保留更多的历史帧信息,从而增强模型整体的跟踪可靠性。
Related Works
Motion Modeling
运动建模是目标跟踪任务中一个重要的研究方向,包括启发式方法和基于学习的方法。启发式方法通常基于运动模型,如Kalman滤波器,依赖于固定的运动先验和预定义的超参数来预测物体轨迹。虽然 KF 在许多跟踪基准测试中被证明是有效的,但在运动强烈或突然的情况下,通常会效果较差;还有一些方法尝试通过补偿相机运动来抵消强烈或突然的物体运动,然后应用传统的基于kF的预测。然而这些基于KF预测的方法都具有大量的超参数,从而限制了对于特定的场景的适应性。相比之下,可学习的运动模型因其数据驱动的性质而引起了越来越多的研究。
Revisiting Segment Anything Model 2
Prompt Encoder
prompt encoder的设计与SAM相同,可以输入两种类型的prompt,即离散的点或框和稠密的mask,prompt encoder输出的prompt tokens可以表示为xprompt∈Ntokens×dx_{prompt} \in N_{tokens} × dxprompt∈Ntokens×d在视觉对象跟踪中,提供了第一帧t0t_0t0 目标对象的真实边界框,SAM 2 将左上角和右下角点的位置编码作为输入,而其余序列使用来自前一帧的预测掩码 ̄ Mˉt−1\bar{M}_{t−1}Mˉt−1 作为提示编码器的输入。
Mask Decoder
memory decoder将memory attention layer中产生的memory-conditioned image embedding以及来自于prompt encoder的prompt tokens作为输入,其多头的输出结果中包括mask的预测以及对应的mask的分数smasks_{mask}smask(即IoU分数),和一个表示当前帧目标得分的sobjs_{obj}sobj
M={(M0,smask,0),(M1,smask,1),...}\mathcal{M} = \{(M_0,s_{mask,0}),(M_1,s_{mask,1}),... \}M={(M0,smask,0),(M1,smask,1),...}
smasks_{mask}smask通过MAE loss的监督得到,表示mask的整体置信度,sobjs_{obj}sobj则通过CE loss的监督得到,以确认目标是否存在于当前帧中。
在原始实现中,最终输出的结果是根据NmaskN_{mask}Nmask中的最高得分给出的。然而在跟踪任务中,smasks_{mask}smask并不是非常稳健的指标,尤其是在存在相似目标相互遮挡的拥挤场景中,为此我们引入了一个额外的运动模型来跟踪目标的运动,并提供额外的运动分数来帮助选择mask。
Memory Attention Layer
Memory attention 模块首先对当前帧的embedding进行self-attention,再对image embedding 和内存中的信息进行cross-attention,因此无条件的image embedding得到了来自于先前输出的mask,输入的prompt和目标点集的上下文信息。
Memory Encoder and Memory Bank
在经过mask decoder 生成输出的mask之后,mask会经过memory encoder来生成对应的memory embedding,新的memory 会在当前帧处理完成后进行更新,这些memory embedding会存储在memory bank中(first-in-first-out FIFO的队列),并在下一帧中作为输入进行使用。在任意时间t下,memory banke可以表示为:
Bt=[mt−1,mt−2,...,mt−Nmem]B_t = [m_{t-1}, m_{t-2}, ..., m_{t-N_{mem}}]Bt=[mt−1,mt−2,...,mt−Nmem]
其中,使用最后的NmemN_{mem}Nmem帧的输出作为memory bank 的信息
这种直接的fixed-window的内存可能会受到错误encoder或低置信度目标的影响,导致在长序列的视觉跟踪任务的上下文中传播错误。我们提出的基于运动感知的记忆选择策略将会替换原有的原始memory bank,以确保可以保留更好的memory 特征和图像特征的选择。
Method
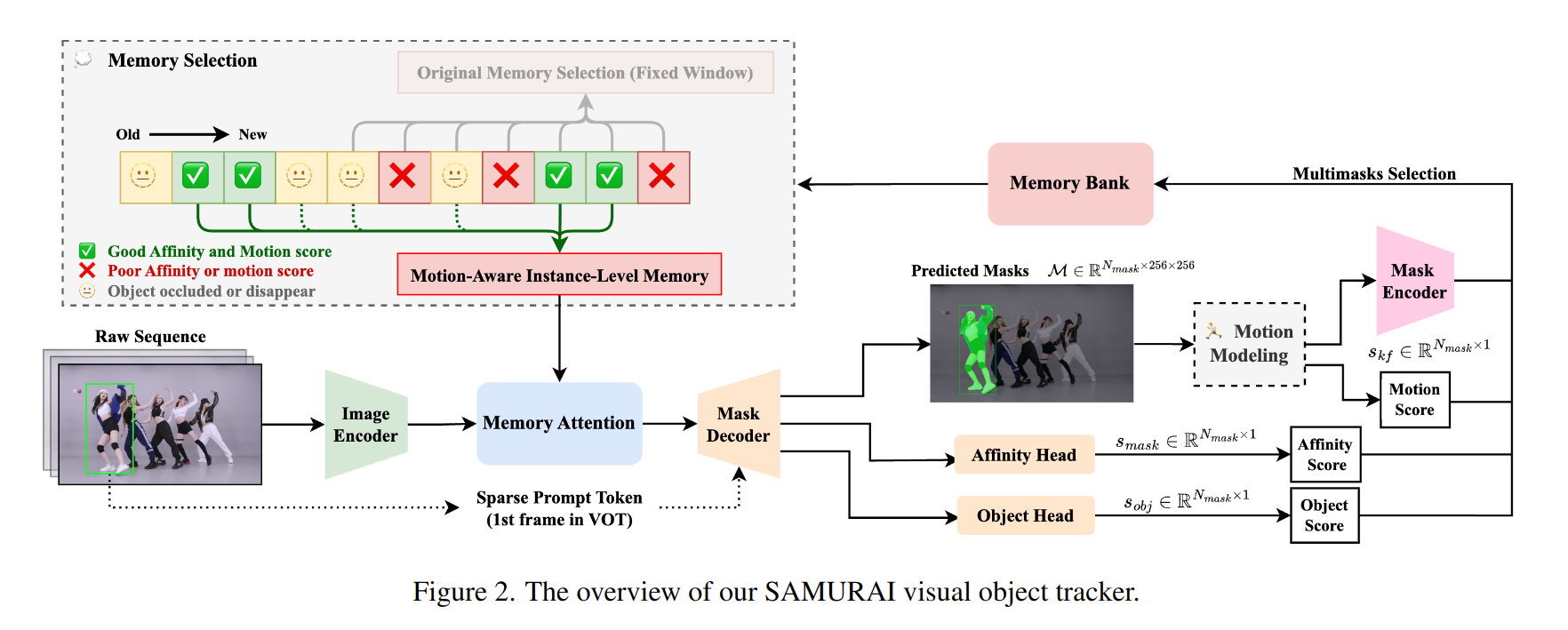
Motion Modeling
运动建模一直是视觉对象跟踪 (VOT) 和多目标跟踪 (MOT) 在解决关联歧义方面的有效方法。我们采用基于线性的卡尔曼滤波器作为我们的基线,以证明运动建模在提高跟踪精度方面的结合
在我们的视觉对象跟踪框架中,我们集成了卡尔曼滤波器来增强边界框位置和维度预测,这反过来又有助于从M个mask中选取N个置信度最高的候选mask,状态向量x定义为:
x=[x,y,w,h,x˙,y˙,w˙,h˙]T\mathbf{x} = [x, y, w, h, \dot{x}, \dot{y}, \dot{w}, \dot{h}]^Tx=[x,y,w,h,x˙,y˙,w˙,h˙]T
其中分别表示目标的中心坐标(x,y),宽度和高度(w,h),以及速度(dx,dy,dw,dh)(d_x,d_y,d_w,d_h)(dx,dy,dw,dh)。对于每一个maskMiM_iMi, 通过计算mask非零像素的边界来得到对应的边界坐标,卡尔曼滤波器在预测正确的循环中,其状态转移方程可以表示为:
xt+1∣t=Fxˉt∣t\mathbf{x}_{t+1|t} = \mathbf{F} \mathbf{\bar{x}}_{t|t}xt+1∣t=Fxˉt∣t
skf=IoU(xˉt+1∣t,Mi)s_{kf} = IoU(\mathbf{\bar{x}}_{t+1|t}, M_i)skf=IoU(xˉt+1∣t,Mi)
KF-IoU 分数 skfs_{kf}skf 通过预测mask的IoU分数和由卡尔曼滤波器预测的边界框来计算,然后选择最高的KF-IoU 分数和原有的mask分数smasks_{mask}smask的加权和来选择最终的mask:
M∗=argmaxMi(αkfskf(Mi)+(1−αkf)smask(Mi))M^* = \text{argmax}_{M_i}(\alpha_{kf}s_{kf}(M_i) + (1-\alpha_{kf})s_{mask}(M_i))M∗=argmaxMi(αkfskf(Mi)+(1−αkf)smask(Mi))
最后,卡尔曼滤波器的状态更新方程可以表示为:
xˉt+1∣t+1=Hxt+1∣t+K(zt+1−Hxt+1∣t)\mathbf{\bar{x}}_{t+1|t+1} = \mathbf{H} \mathbf{x}_{t+1|t} + \mathbf{K}(\mathbf{z}_{t+1} - \mathbf{H} \mathbf{x}_{t+1|t})xˉt+1∣t+1=Hxt+1∣t+K(zt+1−Hxt+1∣t)
此外,为了保证目标对象在一段时间内重新出现或较差的mask质量后运动建模的鲁棒性,我们还保持了稳定的运动状态,当且仅当被跟踪的对象在过去τkfτ_{kf}τkf帧中成功更新时,我们才会考虑运动模块。
Motion-Aware Memory Selection
原生SAM2基于从历史帧中选取的NmemN_{mem}Nmem作为当前帧的条件视觉特征,为了构建一个考虑目标运动的memory bank, 我们基于三个分数对历史帧进行有条件选取:mask分数,目标遮挡分数和运动分数。当且仅当三个分数都大于对应阈值时,才会将这一帧的memory embedding添加到memory bank中。
我们根据上述评分函数选取NmemN_{mem}Nmem来构建基于运动感知的memory bank BtB_tBt:
Bt={mi∣f(smask,sobj,skf)=1,t−Nmax≤i<t}B_t = \{m_i|f(s_{mask},s_{obj},s_{kf}) = 1, t - N_{max} ≤ i < t \}Bt={mi∣f(smask,sobj,skf)=1,t−Nmax≤i<t}
其中NmaxN_{max}Nmax表示可查看的最大帧数, 基于运动感知的BtB_tBt随后通过memory attention layer和mask decoder生成当前时间戳的mask,此处保持SAM2中对 Nmem=7N_{mem}=7Nmem=7的设定。
本文提出的运动模型和内存选择模块策略都可以显著增强跟踪精度,且不会带来额外损耗。
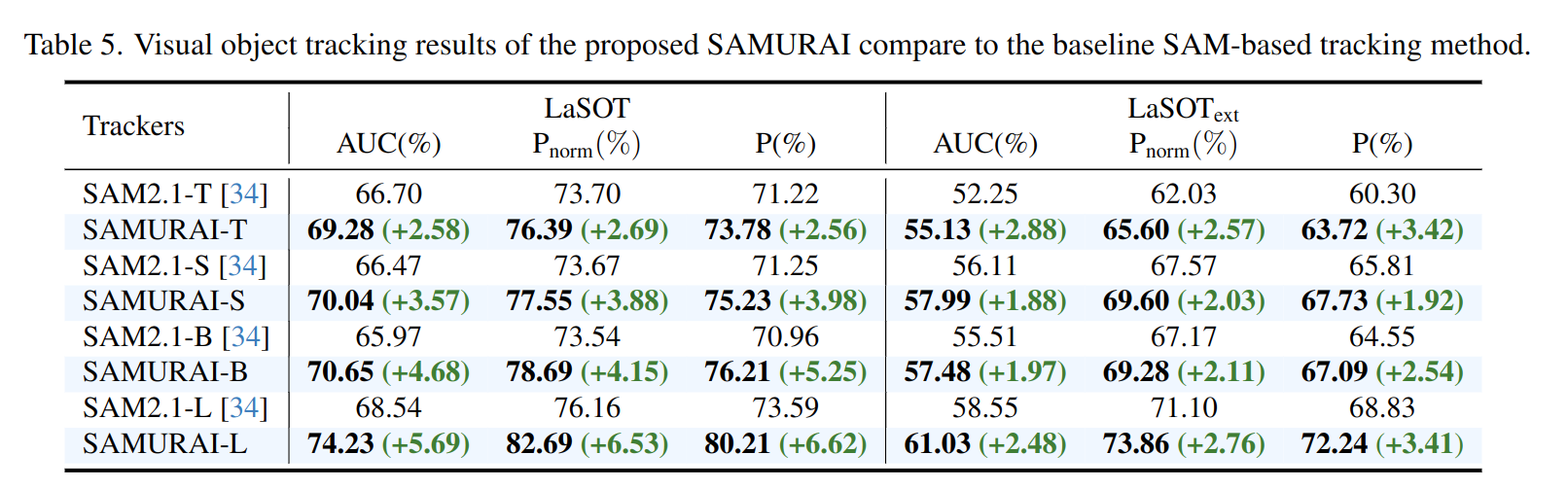
result
在这里插入图片描述


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









