




前言
网络爬虫(Web Crawler),也称为网页蜘蛛(Web Spider)或网页机器人(Web Bot),是一种按照既定规则自动浏览网络并提取信息的程序。爬虫的主要用途包括数据采集、网络索引、内容抓取等。
爬虫的基本原理:
种子 URL:爬虫从一个或多个种子 URL 开始,这些 URL 是起点。
发送请求:爬虫向这些种子 URL 发送 HTTP 请求,通常是 GET 请求。
获取响应:服务器返回网页的 HTML 内容作为响应。
解析内容:爬虫解析 HTML 内容,提取所需的数据(如文本、链接、图片等)。
提取链接:从网页中提取出所有链接,并将这些链接加入待访问队列。
重复过程:爬虫重复上述步骤,直到达到某个停止条件,如爬取了一定数量的页面,或所有页面都被爬取完毕。
使用工具:selenium
安装selenium:
pip in selenium
安装driver:
需要安装driver才能使用selenium,模拟浏览器打开,以下使用的是 edge,其他浏览器自行百度安装;
下载网址:https://developer.microsoft.com/zh-cn/microsoft-edge/tools/webdriver/?form=MA13LH
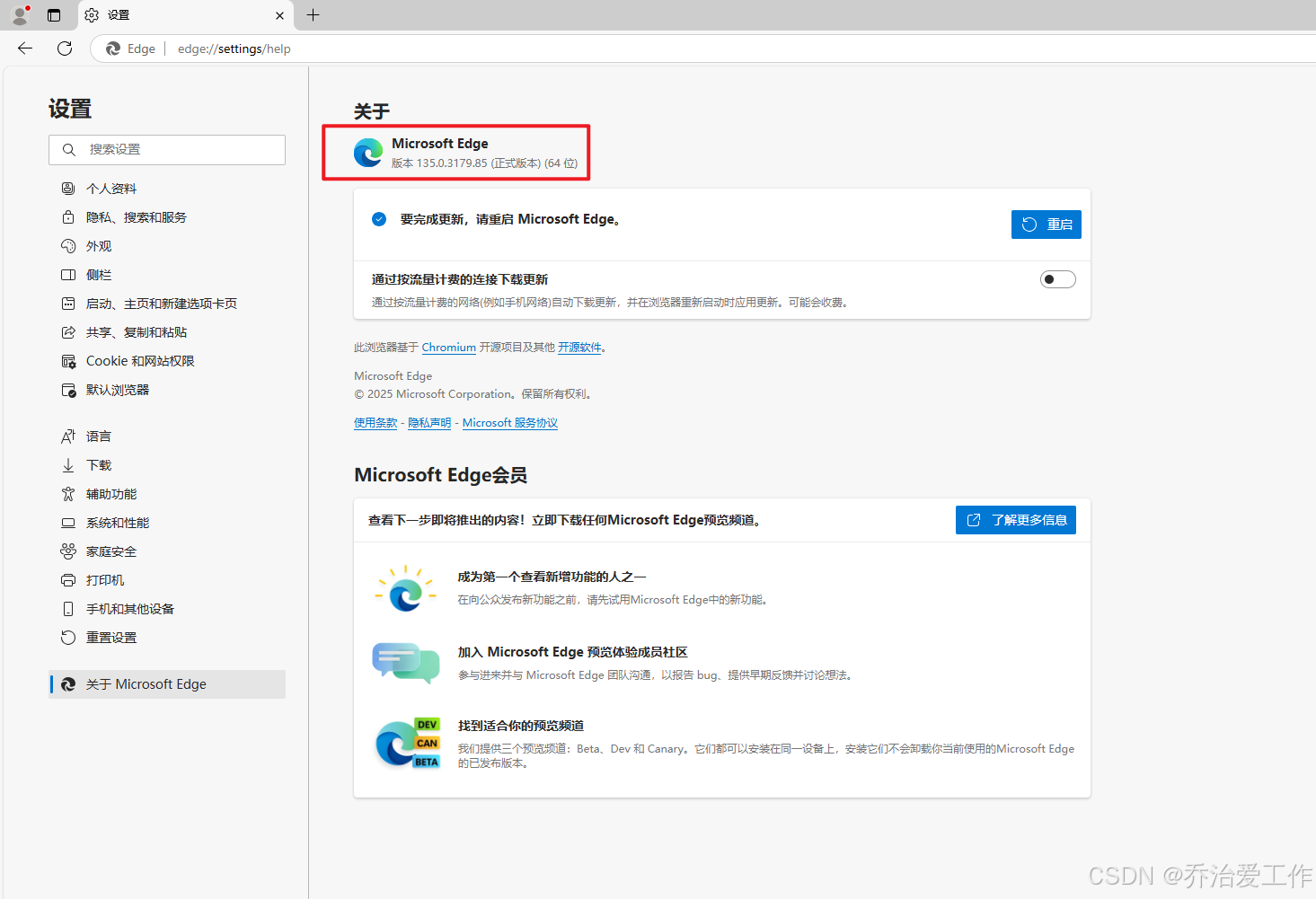
打开edg浏览器,在网址栏输入:edge://settings/help即可查看edg版本,下载对应版本driver即可;(太久没使用edg,打开后可能会自动更新,导致第一次看到的版本非最新版本,重新打开即可)
分析网页内容
本次爬取内容网址为(中国工人日报):https://www.workercn.cn/papers/grrb/2025/04/19/1/page.html
使用谷歌浏览器,打开以上网址,且按F12查看网页源码
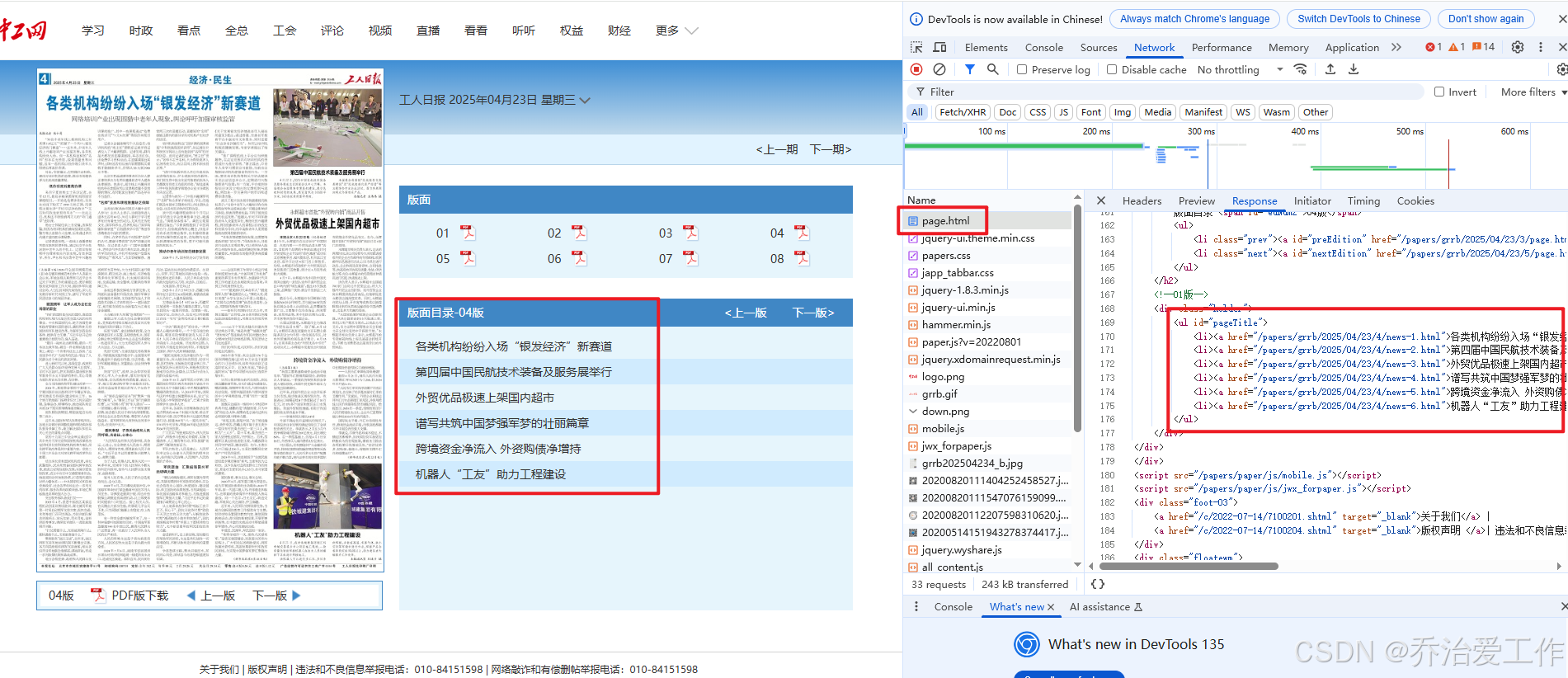
通过查看网址源码可知,该网址为静态网址,数据主要存储在html上,直接爬取该url即可得到对应数据;
url分析可知:
https://www.workercn.cn/papers/grrb/2025/04/24/1/page.html
https://www.workercn.cn/papers/grrb/对应日报时间/版面/page.html
因此我们需要使用到日期函数来获取到我们需要爬取的时间周期内日期:
from datetime import datetime, timedelta
thirty_days_ago = datetime.today() - timedelta(days=int(xday))
生成从30天前到现在的日期列表
date_list = [(thirty_days_ago + timedelta(days=i)).strftime('%Y%/m/%d') for i in range(31)]
for date in date_list :
print(date)< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1623
1623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











