



目 录
随着信息技术的飞速发展和大数据时代的到来,图书馆作为知识的海洋,面临着前所未有的挑战与机遇。传统的图书馆管理方式已难以满足现代读者的多元化和个性化需求,而基于Python的图书书籍可视化系统则成为了一种创新且高效的解决方案。
该系统融合了数据分析、爬虫技术、大屏展示等多种先进技术,旨在为读者提供更加便捷、直观、全面的图书浏览和查询体验。通过爬虫技术,系统能够自动抓取网络上的图书资源,实现图书信息的自动更新和扩充;借助数据分析,系统可以对图书数据进行深度挖掘和分析,揭示图书之间的关联和趋势;而大屏展示则能够将分析结果以直观、生动的方式呈现出来,为读者提供更加直观、全面的图书信息概览。
Python作为一种功能强大、易于学习的编程语言,在数据处理、可视化、Web开发等领域具有广泛的应用。在图书书籍可视化系统的设计中,Python发挥着至关重要的作用。通过利用Python的数据处理和分析库,如Pandas、NumPy等,系统可以对图书数据进行高效的清洗、整合和转换;通过利用Python的可视化库,如Matplotlib、Seaborn等,系统可以将分析结果以图表、图像等形式直观地展示出来;而Python的Web开发框架,如Django、Flask等,则为系统的构建和部署提供了强大的支持。
综上所述,基于Python的图书书籍可视化系统,通过融合大屏展示、爬虫技术和数据分析等多种先进技术,为读者提供了更加便捷、直观、全面的图书浏览和查询体验。这一系统的设计和实现,不仅有助于推动图书馆的数字化转型和升级,也为读者带来了更加高效、个性化的阅读体验。
关键词:图书书籍可视化系统;Python;Web开发;Django
Abstract
With the rapid development of information technology and the arrival of the big data era, libraries, as the ocean of knowledge, are facing unprecedented challenges and opportunities. Traditional library management methods are no longer able to meet the diverse and personalized needs of modern readers, while Python based book visualization systems have become an innovative and efficient solution.
This system integrates various advanced technologies such as data analysis, web crawling, and large screen display, aiming to provide readers with a more convenient, intuitive, and comprehensive book browsing and query experience. Through web scraping technology, the system can automatically crawl book resources on the network, achieving automatic updating and expansion of book information; With the help of data analysis, the system can deeply mine and analyze book data, revealing the relationships and trends between books; The large screen display can present the analysis results in an intuitive and vivid way, providing readers with a more intuitive and comprehensive overview of book information.
Python, as a powerful and easy to learn programming language, has a wide range of applications in fields such as data processing, visualization, and web development. Python plays a crucial role in the design of book visualization systems. By utilizing Python's data processing and analysis libraries, such as Pandas, NumPy, etc., the system can efficiently clean, integrate, and transform book data; By utilizing Python visualization libraries such as Matplotlib, Seaborn, etc., the system can visually display the analysis results in the form of charts, images, etc; Python's web development frameworks, such as Django, Flask, etc., provide powerful support for system construction and deployment.
In summary, the book visualization system based on Python provides readers with a more convenient, intuitive, and comprehensive book browsing and query experience by integrating various advanced technologies such as large screen display, web crawling technology, and data analysis. The design and implementation of this system not only helps to promote the digital transformation and upgrading of libraries, but also brings readers a more efficient and personalized reading experience.
Keywords:Book visualization system; Python; Web development; Django
1 绪论
1.1 系统设计背景
在数字化、信息化的时代背景下,图书行业正面临着前所未有的挑战与机遇。随着大数据、云计算等技术的飞速发展,图书馆作为知识的宝库,亟需通过技术革新来提升管理效率和服务质量。传统的图书管理方式已难以适应现代读者的多元化、个性化需求,而基于Python的图书书籍可视化系统则成为了推动图书馆数字化转型和升级的关键。
图书行业正经历着数字化转型的浪潮。纸质图书逐渐被电子书、有声书等数字化形式所补充,图书馆也需要通过数字化手段来管理和展示图书资源。Python作为一种功能强大的编程语言,能够高效地处理和分析图书数据,为图书馆的数字化转型提供有力支持。
数据可视化技术的兴起为图书管理带来了新的视角。通过可视化技术,图书馆可以将图书数据以直观、易懂的方式呈现,帮助读者更好地理解图书信息,提升阅读体验。同时,可视化技术也能够为图书馆工作人员提供决策支持,帮助他们更好地了解图书资源的分布和利用情况,优化图书资源配置。
此外,Python在数据处理和可视化方面的优势为图书可视化系统的设计提供了便利。Python拥有丰富的数据处理和分析库,能够高效地对图书数据进行清洗、整合和分析。同时,Python的可视化库也能够将分析结果以图表、图像等形式直观地展示出来,为图书可视化系统的实现提供了强大的技术支持。
综上所述,基于Python的图书书籍可视化系统设计背景主要源于图书行业的数字化转型、数据可视化技术的兴起以及Python在数据处理和可视化方面的优势。这一系统的设计旨在通过技术手段提升图书管理的效率和读者的阅读体验,推动图书馆的数字化转型和升级。通过引入Python等先进技术,图书馆将能够更好地适应数字化时代的需求,为读者提供更加高效、便捷的服务。
基于Python的图书书籍可视化系统设计的主要目的在于通过运用先进的数据处理和可视化技术,将图书馆中大量的书籍信息以直观、生动的方式呈现出来,从而优化图书管理和提高读者的阅读体验。这一设计旨在解决传统图书管理方式中的效率低下、信息展示不直观等问题,通过数字化转型和数据分析,为图书馆带来更高效、智能化的管理方式。
具体而言,该系统的意义在于:它能够帮助图书馆实现数字化转型,适应信息化时代的发展趋势。通过自动化、智能化的数据处理和分析,减少人工操作,提高图书管理的效率和质量。该系统能够提供丰富的图书信息展示和查询功能,使读者能够更加方便地获取所需信息。通过可视化的方式,将图书数据以图表、图像等形式展示,使读者能够更直观地了解图书的分布、借阅情况等,提升阅读体验。此外,该系统还能够为图书馆工作人员提供决策支持。通过对图书数据的深入分析,发现图书资源的利用情况和市场需求,为图书馆的资源配置、采购决策等提供科学依据。
综上所述,基于Python的图书书籍可视化系统设计的目的在于通过技术手段优化图书管理和提高读者的阅读体验,其意义在于推动图书馆的数字化转型和升级,提高图书管理的效率和质量,为读者提供更加便捷、直观的服务,同时为图书馆工作人员提供决策支持,促进图书资源的优化配置。这一系统的应用将有助于图书馆更好地适应信息化时代的发展需求,提升其在知识传播和文化传承中的作用。
1.3.1MVVM模式介绍
MVVM是Model-View-ViewModel的简写。它本质上就是MVC 的改进版。MVVM 就是将其中的View 的状态和行为抽象化,让我们将视图 UI 和业务逻辑分开。当然这些事 ViewModel 已经帮我们做了,它可以取出 Model 的数据同时帮忙处理 View 中由于需要展示内容而涉及的业务逻辑。微软的WPF带来了新的技术体验,如Silverlight、音频、视频、3D、动画……,这导致了软件UI层更加细节化、可定制化。同时,在技术层面,WPF也带来了 诸如Binding、Dependency Property、Routed Events、Command、DataTemplate、ControlTemplate等新特性。MVVM(Model-View-ViewModel)框架的由来便是MVP(Model-View-Presenter)模式与WPF结合的应用方式时发展演变过来的一种新型架构框架。它立足于原有MVP框架并且把WPF的新特性糅合进去,以应对客户日益复杂的需求变化。
1.3.2Django框架
Django是一个由Python编写的具有完整架站能力的开源Web框架。使用Django,只要很少的代码,Python的程序开发人员就可以轻松地完成一个正式网站所需要的大部分内容,并进一步开发出全功能的Web服务[10]。
Django本身基于MVC模型,即Model(模型)+View(视图)+ Controller(控制器)设计模式,因此天然具有MVC的出色基因:开发快捷、部署方便、可重用性高、维护成本低等。Python加Django是快速开发、设计、部署网站的最佳组合。
Django具有以下特点:
能完善、要素齐全:该有的、可以没有的都有,常用的、不常用的工具都用。Django提供了大量的特性和工具,无须你自己定义、组合、增删及修改。
完善的文档:经过十多年的发展和完善,Django有广泛的实践经验和完善的在线文档(可惜大多数为英文)。开发者遇到问题时可以搜索在线文档寻求解决方案。
强大的数据库访问组件:Django的Model层自带数据库ORM组件,使得开发者无须学习其他数据库访问技术(SQL、pymysql、SQLALchemy等)。
灵活的URL映射:Django使用正则表达式管理URL映射,灵活性高。
丰富的Template模板语言:类似jinjia模板语言,不但原生功能丰富,还可以自定义模板标签。
Vue.js是一套构建用户界面的渐进式框架。与其他重量级框架不同的是,Vue采用自底向上增量开发的设计。Vue 的核心库只关注视图层,并且非常容易学习,非常容易与其它库或已有项目整合。另一方面,Vue 完全有能力驱动采用单文件组件和Vue生态系统支持的库开发的复杂单页应用。
Vue.js 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件。
Vue.js 自身不是一个全能框架——它只聚焦于视图层。因此它非常容易学习,非常容易与其它库或已有项目整合。另一方面,在与相关工具和支持库一起使用时,Vue.js 也能驱动复杂的单页应用。
网络为搜索引擎从万维网下载网页。一般分为传统爬虫和聚焦爬虫。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。通俗的讲,也就是通过源码解析来获得想要的内容。
聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
2 系统分析
本章内容概括了图书书籍可视化系统的可行性分析、功能分析以及用例分析。
2.1 可行性分析
2.1.1 技术可行性分析
图书书籍可视化系统在技术可行性方面具有广泛的支持和应用。Python作为一种高级编程语言,拥有丰富的第三方库和工具,可以轻松地处理各种技术需求。例如,Python的数据库访问工具和ORM框架可以方便地与数据库进行交互,存储和管理信息。Python也支持图形化界面开发,可以创建友好且易于操作的用户界面。总体而言,图书书籍可视化系统在技术可行性方面具备丰富的资源和支持,可以满足系统的各项技术需求,并提供稳定、可靠的功能和性能。
2.1.2 经济可行性分析
图书书籍可视化系统在经济可行性方面具有优势。Python作为一种免费且开源的编程语言,可以降低开发成本并提高效率。开发人员可以利用Python的大量开源库和框架来加快系统开发速度,避免从头开始编写复杂的功能模块。此外,Python还拥有活跃的社区和广泛的用户基础,使得开发人员能够轻松获得支持和解决问题。同时,Python语言的易学性和简洁性也减少了培训成本和开发周期。综上所述,图书书籍可视化系统在经济可行性方面是有利的,可以有效地控制开发成本并提高投资回报率。
图书书籍可视化系统基于Python具有操作可行性。通过使用Python作为开发语言,可以充分利用其简单易学、跨平台和丰富的第三方库等特性,快速构建一个功能完备且稳定的系统。Python提供了丰富的数据库访问工具和网络编程库,使得开发人员能够轻松地处理信息的存储和管理,以及与用户进行交互和通信。此外,Python还具备强大的数据处理和图形化界面开发能力,可以满足友好用户界面的需求。总之,图书书籍可视化系统在操作上是可行的,并且能够提供高效、灵活和易用的管理功能。
图书书籍可视化系统功能需求介绍如下。
登录:管理员需要通过安全的登录功能进行身份验证,以确保系统的安全性和管理权限。
系统用户:管理员可以管理系统中的用户信息,包括添加、编辑、删除用户等操作,确保用户信息的完整性和准确性。
图书信息列表:管理员可以查看系统中的所有图书信息,包括书名、作者、出版日期、ISBN号等相关信息,以便全面了解系统的图书资源情况。
图书信息添加:管理员可以添加新的图书信息到系统中,包括输入书名、作者、出版日期、ISBN号、分类标签等,以丰富系统的图书资源。
图书书籍可视化系统的非功能性需求比如图书书籍可视化系统的安全性怎么样,可靠性怎么样,性能怎么样,可拓展性怎么样等。具体可以表示在如下2-1表格中:
表2-1图书书籍可视化系统非功能需求表
| 安全性 | 主要指图书书籍可视化系统数据库的安装,数据库的使用和密码的设定必须合乎规范。 |
| 可靠性 | 可靠性是指图书书籍可视化系统能够安装用户的指示进行操作,经过测试,可靠性90%以上。 |
| 性能 | 性能是影响图书书籍可视化系统占据市场的必要条件,所以性能最好要佳才好。 |
| 可扩展性 | 比如数据库预留多个属性,比如接口的使用等确保了系统的非功能性需求。 |
| 易用性 | 用户只要跟着图书书籍可视化系统的页面展示内容进行操作,就可以了。 |
| 可维护性 | 图书书籍可视化系统开发的可维护性是非常重要的,经过测试,可维护性没有问题 |
2.3 系统用例分析
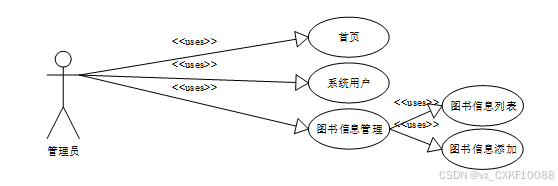
web后台管理上的管理员是维护整个图书书籍可视化系统中所有数据信息的,管理员有后台首页、登录、系统用户、图书信息管理(图书信息列表、图书信息添加)等功能。管理员角色用例如图2-1所示。
2.4.1系统开发流程
图书书籍可视化系统开发时,首先进行需求分析,进而对系统进行总体的设计规划,设计系统功能模块,数据库的选择等,本系统的开发流程如图2-2所示。
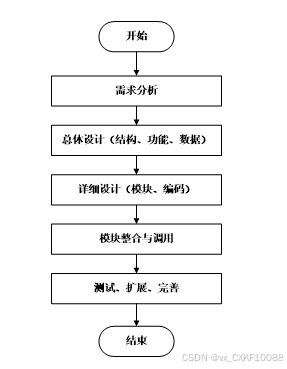
图2-2系统开发流程图
2.4.2 用户登录流程
为了保证系统的安全性,要使用本系统对系统信息进行管理,必须先登陆到系统中。如图2-3所示。
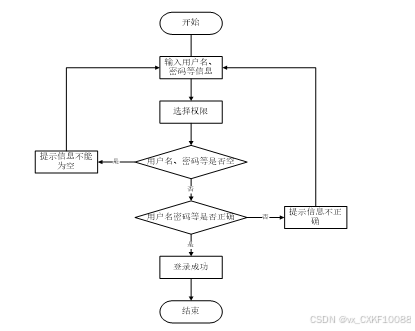
图2-3 登录流程图
2.4.3 系统操作流程
用户打开并进入系统后,会先显示登录界面,输入正确的用户名和密码,系统自动检测信息,若信息无误,则用户会进入系统功能界面,进行操作,否则会提示错误无法登录,操作流程如图2-4所示。
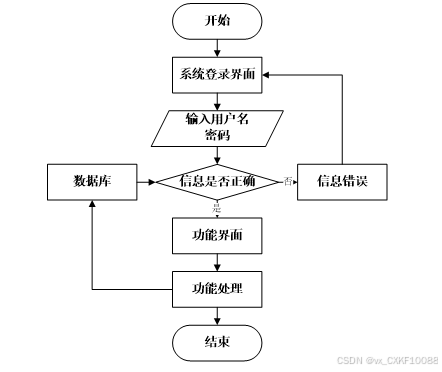
图2-4 系统操作流程图
2.4.4 添加信息流程
管理员可以对图书信息进行信息的添加,用户可以对自己权限内的信息进行添加,输入信息后,系统会自行验证输入的信息和数据,若信息正确,会将其添加到数据库内,若信息有误,则会提示重新输入信息,添加信息流程如图2-5所示。
图2-5添加信息流程图
2.4.5 修改信息流程
管理员可以对图书信息进行的修改,用户可以对自己权限内的信息进行修改,首先进入修改信息界面,输入修改信息数据,系统进行数据的判断验证,修改信息合法则修改成功,信息更新至数据库,信息不合法则修改失败,重新输入。修改信息流程图如图2-6所示。
图2-6修改信息流程图
2.4.6 删除信息流程
管理员可以对图书信息进行信息的删除,对要删除的信息进行选中后,点击删除按钮,系统会询问是否确定,若点击确定,则系统会删除掉选中的信息,并在数据库内对信息进行删除,删除信息流程图如图2-7所示。
图2-7删除信息流程图
本章主要通过对图书书籍可视化系统的可行性分析、功能需求分析、系统用例分析,确定整个图书书籍可视化系统要实现的功能。同时也为图书书籍可视化系统的代码实现和测试提供了标准。
本章主要讨论的内容包括图书书籍可视化系统的功能模块设计、数据库系统设计。
3.1 系统模块设计
图书书籍可视化系统根据前面章节的功能需求分析得出其总体设计模块图如图3-1所示。
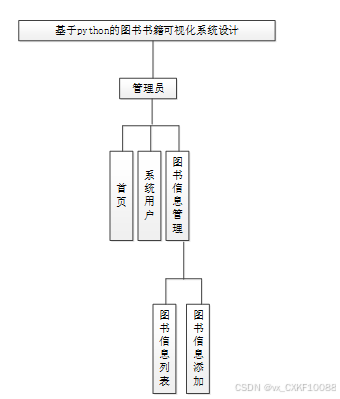
图3-1 图书书籍可视化系统功能模块图
数据库设计一般包括需求分析、概念模型设计、数据库表建立三大过程,其中需求分析前面章节已经阐述,概念模型设计有概念模型和逻辑结构设计两部分。
3.2.1 数据库概念结构设计
下面是整个图书书籍可视化系统中主要的数据库表总E-R实体关系图。
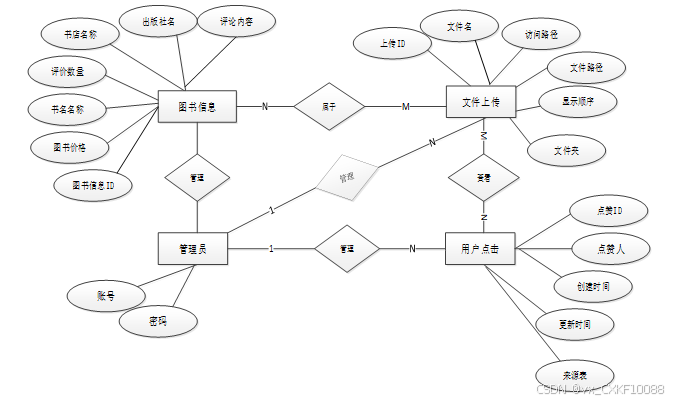
图3-2 图书书籍可视化系统总E-R关系图
通过上一小节中图书书籍可视化系统中总E-R关系图上得出一共需要创建很多个数据表。在此主要罗列几个主要的数据库表结构设计。
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | token_id | int | 10 | 0 | N | Y | 临时访问牌ID | |
| 2 | token | varchar | 64 | 0 | Y | N | 临时访问牌 | |
| 3 | info | text | 65535 | 0 | Y | N | ||
| 4 | maxage | int | 10 | 0 | N | N | 2 | 最大寿命:默认2小时 |
| 5 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 6 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 7 | user_id | int | 10 | 0 | N | N | 0 | 用户编号: |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | auth_id | int | 10 | 0 | N | Y | 授权ID: | |
| 2 | user_group | varchar | 64 | 0 | Y | N | 用户组: | |
| 3 | mod_name | varchar | 64 | 0 | Y | N | 模块名: | |
| 4 | table_name | varchar | 64 | 0 | Y | N | 表名: | |
| 5 | page_title | varchar | 255 | 0 | Y | N | 页面标题: | |
| 6 | path | varchar | 255 | 0 | Y | N | 路由路径: | |
| 7 | position | varchar | 32 | 0 | Y | N | 位置: | |
| 8 | mode | varchar | 32 | 0 | N | N | _blank | 跳转方式: |
| 9 | add | tinyint | 3 | 0 | N | N | 1 | 是否可增加: |
| 10 | del | tinyint | 3 | 0 | N | N | 1 | 是否可删除: |
| 11 | set | tinyint | 3 | 0 | N | N | 1 | 是否可修改: |
| 12 | get | tinyint | 3 | 0 | N | N | 1 | 是否可查看: |
| 13 | field_add | text | 65535 | 0 | Y | N | 添加字段: | |
| 14 | field_set | text | 65535 | 0 | Y | N | 修改字段: | |
| 15 | field_get | text | 65535 | 0 | Y | N | 查询字段: | |
| 16 | table_nav_name | varchar | 500 | 0 | Y | N | 跨表导航名称: | |
| 17 | table_nav | varchar | 500 | 0 | Y | N | 跨表导航: | |
| 18 | option | text | 65535 | 0 | Y | N | 配置: | |
| 19 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 20 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | book_information_id | int | 10 | 0 | N | Y | 图书信息ID | |
| 2 | book_prices | varchar | 64 | 0 | Y | N | 图书价格 | |
| 3 | title_of_the_book | text | 65535 | 0 | Y | N | 书名名称 | |
| 4 | number_of_evaluations | varchar | 64 | 0 | Y | N | 评价数量 | |
| 5 | bookstore_name | varchar | 64 | 0 | Y | N | 书店名称 | |
| 6 | publishing_house_name | varchar | 64 | 0 | Y | N | 出版社名 | |
| 7 | comment_content | text | 65535 | 0 | Y | N | 评论内容 | |
| 8 | comment_time | varchar | 64 | 0 | Y | N | 评论时间 | |
| 9 | purchase_region | varchar | 64 | 0 | Y | N | 购买地区 | |
| 10 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 11 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | hits_id | int | 10 | 0 | N | Y | 点赞ID: | |
| 2 | user_id | int | 10 | 0 | N | N | 0 | 点赞人: |
| 3 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 4 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 5 | source_table | varchar | 255 | 0 | Y | N | 来源表: | |
| 6 | source_field | varchar | 255 | 0 | Y | N | 来源字段: | |
| 7 | source_id | int | 10 | 0 | N | N | 0 | 来源ID: |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | regular_users_id | int | 10 | 0 | N | Y | 普通用户ID | |
| 2 | user_name | varchar | 64 | 0 | Y | N | 用户姓名 | |
| 3 | user_gender | varchar | 64 | 0 | Y | N | 用户性别 | |
| 4 | user_phone_number | varchar | 64 | 0 | Y | N | 用户电话 | |
| 5 | user_address | varchar | 64 | 0 | Y | N | 用户地址 | |
| 6 | examine_state | varchar | 16 | 0 | N | N | 已通过 | 审核状态 |
| 7 | user_id | int | 10 | 0 | N | N | 0 | 用户ID |
| 8 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 9 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | upload_id | int | 10 | 0 | N | Y | 上传ID | |
| 2 | name | varchar | 64 | 0 | Y | N | 文件名 | |
| 3 | path | varchar | 255 | 0 | Y | N | 访问路径 | |
| 4 | file | varchar | 255 | 0 | Y | N | 文件路径 | |
| 5 | display | varchar | 255 | 0 | Y | N | 显示顺序 | |
| 6 | father_id | int | 10 | 0 | Y | N | 0 | 父级ID |
| 7 | dir | varchar | 255 | 0 | Y | N | 文件夹 | |
| 8 | type | varchar | 32 | 0 | Y | N | 文件类型 |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | user_id | mediumint | 8 | 0 | N | Y | 用户ID:[0,8388607]用户获取其他与用户相关的数据 | |
| 2 | state | smallint | 5 | 0 | N | N | 1 | 账户状态:[0,10](1可用|2异常|3已冻结|4已注销) |
| 3 | user_group | varchar | 32 | 0 | Y | N | 所在用户组:[0,32767]决定用户身份和权限 | |
| 4 | login_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 上次登录时间: |
| 5 | phone | varchar | 11 | 0 | Y | N | 手机号码:[0,11]用户的手机号码,用于找回密码时或登录时 | |
| 6 | phone_state | smallint | 5 | 0 | N | N | 0 | 手机认证:[0,1](0未认证|1审核中|2已认证) |
| 7 | username | varchar | 16 | 0 | N | N | 用户名:[0,16]用户登录时所用的账户名称 | |
| 8 | nickname | varchar | 16 | 0 | Y | N | 昵称:[0,16] | |
| 9 | password | varchar | 64 | 0 | N | N | 密码:[0,32]用户登录所需的密码,由6-16位数字或英文组成 | |
| 10 | | varchar | 64 | 0 | Y | N | 邮箱:[0,64]用户的邮箱,用于找回密码时或登录时 | |
| 11 | email_state | smallint | 5 | 0 | N | N | 0 | 邮箱认证:[0,1](0未认证|1审核中|2已认证) |
| 12 | avatar | varchar | 255 | 0 | Y | N | 头像地址:[0,255] | |
| 13 | open_id | varchar | 255 | 0 | Y | N | 针对获取用户信息字段 | |
| 14 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 15 | vip_level | varchar | 255 | 0 | Y | N | 会员等级 | |
| 16 | vip_discount | double | 11 | 2 | Y | N | 0.00 | 会员折扣 |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | group_id | mediumint | 8 | 0 | N | Y | 用户组ID:[0,8388607] | |
| 2 | display | smallint | 5 | 0 | N | N | 100 | 显示顺序:[0,1000] |
| 3 | name | varchar | 16 | 0 | N | N | 名称:[0,16] | |
| 4 | description | varchar | 255 | 0 | Y | N | 描述:[0,255]描述该用户组的特点或权限范围 | |
| 5 | source_table | varchar | 255 | 0 | Y | N | 来源表: | |
| 6 | source_field | varchar | 255 | 0 | Y | N | 来源字段: | |
| 7 | source_id | int | 10 | 0 | N | N | 0 | 来源ID: |
| 8 | register | smallint | 5 | 0 | Y | N | 0 | 注册位置: |
| 9 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 10 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
整个图书书籍可视化系统的需求分析主要对系统总体架构以及功能模块的设计,通过建立E-R模型和数据库逻辑系统设计完成了数据库系统设计。
4 系统关键模块的详细设计与实现
图书书籍可视化系统的详细设计与实现主要是根据前面的图书书籍可视化系统的需求分析和图书书籍可视化系统的总体设计来设计页面并实现业务逻辑。主要从图书书籍可视化系统界面实现、业务逻辑实现这两部分进行介绍。
4.1管理登录界面
管理员在后台可以输入用户名+密码进行登录,管理员的用户名和密码是在数据库中直接设定好的。管理员登录界面如下图4-1所示。

图4-1管理员登录界面图
用户登录关键代码如下:
def Login(self, ctx):
print("===================登录=====================")
ret = {
"error": {
"code": 70000,
"message": "账户不存在",
}
}
body = ctx.body
password = md5hash(body["password"]) or ""
obj = service_select("user").Get_obj(
{"username": body["username"]}, {"like": False}
)
if obj:
user_group = service_select("user_group").Get_obj({'name': obj['user_group']}, {"like": False})
if user_group and user_group['source_table'] != '':
user_obj = service_select(user_group['source_table']).Get_obj({"user_id": obj['user_id']}, {"like": False})
if user_obj['examine_state'] == '未通过':
ret = {
"error": {
"code": 70000,
"message": "账户未通过审核",
}
}
return ret
if user_obj['examine_state'] == '未审核':
ret = {
"error": {
"code": 70000,
"message": "账户未审核",
}
}
return ret
if obj["state"] == 1:
if obj["password"] == password:
timeout = timezone.now()
timestamp = int(time.mktime(timeout.timetuple())) * 1000
token = md5hash(str(obj["user_id"]) + "_" + str(timestamp))
ctx.request.session[token] = obj["user_id"]
service_select("access_token").Add(
{"token": token, "user_id": obj["user_id"]}
)
obj["token"] = token
ret = {
"result": {"obj": obj}
}
else:
ret = {
"error": {
"code": 70000,
"message": "密码错误",
}
}
else:
ret = {
"error": {
"code": 70000,
"message": "用户账户不可用,请联系管理员",
}
}
return ctx.response(json.dumps(ret, ensure_ascii=False))
管理员可以查看系统用户、图书信息管理(图书信息列表、图书信息添加)等,并且可以根据需要进行相应的操作,界面如下图4-2所示。

图4-2管理员功能界面图
管理员可以对系统中所有的用户角色进行管控,如果需要添加新的用户,点击页面中的“添加”按钮根据提示输入上用户信息,点击“提交”以后在对应的用户界面就可以查看到了,可以点击用户后面的“删除”按钮直接删除某一用户。系统用户管理界面如下图所示。界面如下图4-3所示。
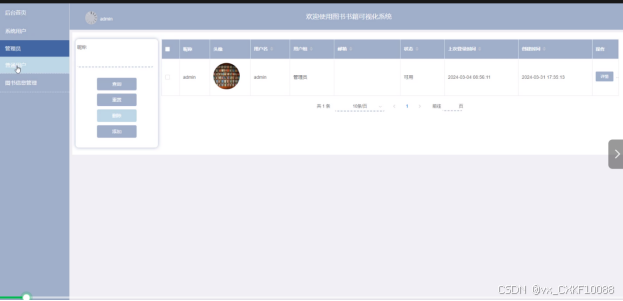
图4-3系统用户管理界面图
系统用户代码如下:
def Del(self, ctx):
if len(ctx.query) == 0:
errorMsg = {"code": 30000, "message": "删除条件不能为空!"}
return errorMsg
result = self.service.Del(ctx.query, self.config)
if self.service.error:
return {"error": self.service.error}
return {"result": result}
管理员点击“图书信息列表”可以查看所有的图书信息,包括图书价格、书名名称、
评价数量、书店名称、出版社名、评论内客、评论时间等。通过输入书名名称、收店名称、出版社名进行查询、重置、导出、删除、导入和下载导入文档等操作。也可以选择某一条图书信息进行删除。导入相关图书信息可以生成大屏数据可视化。在可视化界面可以查看图书评论数、出版社数据统计、图书价格统计、购买地区分布、读者评论相关的统计报表。界面如下图4-4到4-6所示。

图4-4图书信息列表管理界面图
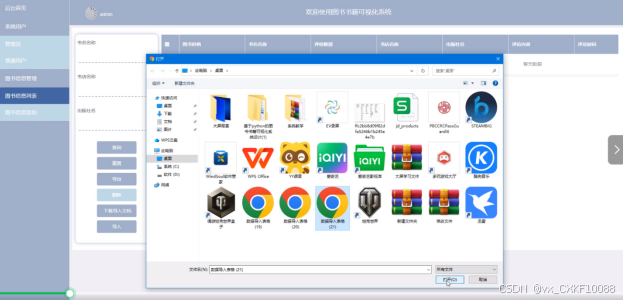
图4-5下载导入文档界面图
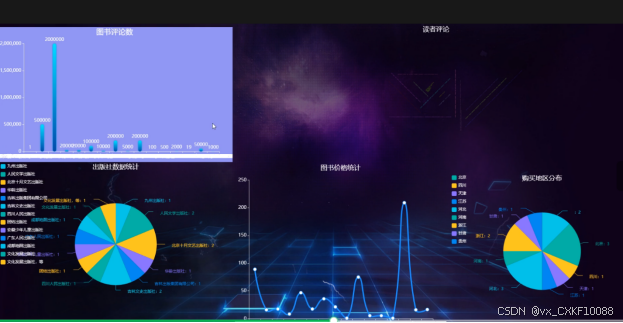
图4-6数据可视化界面图
管理员点击“图书信息添加”,输入图书价格、评论内容、书名名称、评论时间、评价数量、书店名称、出版社名、购买地区等相关信息,点提交,就可以添加新的图书信息。界面如下图4-7所示。

图4-8图书信息添加界面图
图书信息添加代码如下:
def Add(self, ctx):
body = ctx.body
unique = self.config.get("unique")
obj = None
if unique:
qy = {}
for i in range(len(unique)):
key = unique[i]
qy[key] = body.get(key)
obj = self.service.Get_obj(qy)
if not obj:
error = self.Add_before(ctx)
if error["code"]:
return {"error": error}
error = self.Events("add_before", ctx, None)
if error["code"]:
return {"error": error}
result = self.service.Add(body, self.config)
if self.service.error:
return {"error": self.service.error}
res = self.Add_after(ctx, result)
if res:
result = res
res = self.Events("add_after", ctx, result)
if res:
result = res
return {"result": result}
else:
return {"error": {"code": 10000, "message": "已存在"}}
5系统测试
测试存在于软件开发进程中的最后一个阶段,它可以保证一个软件的开发质量是否符合设计者的初衷,也为程序的正式上线做了最后一道质量检测的工序。软件测试主要是控制各种条件、包括软件输出方式,使用模式和运行环境等,来评估一个系统或应用是否符合设计标准。在软件测试过程中,我们一般刻意的去制造错误和极端条件,不能仅依照正常模式允许,而是多去尝试那些意外的情况。
只有在运行和维护阶段之前经历大量的测试的软件,才能说明它的质量是经得起检验的。最近计算机业界也都一致认为,测试应该存在于软件设计的每个阶段,因为越早发现错误,修复起来就越容易。
实际上,对于一个软件应用,错误是必然存在的,无论使用何种技术或手段,都不可能绝对的排除软件漏洞。测试是随着软件开发一同诞生的,两者是共同发展进步的。实际上,测试可以大幅度的降低维护的成本,如果一个漏洞在开发的早期就被发现,那么修复它的成本远比上线后再修复的成本要低得多。
测试有白盒测试和黑盒测试两种方式。
其中,白盒测试是将软件看成一个透明的白盒子,按照程序的内部控制结构和处理技术逻辑来选定测试用例、软件系统测试的逻辑路径及过程需要进行管理测试,又称玻璃盒测试。因此白盒测试需要选择足够多的测试用例,覆盖尽可能多的代码来发现程序中的错误。
黑盒测试,也称为功能测试。它将需软件看作一个黑盒,像一个普通用户一样来模拟软件的使用流程。黑盒测试通过大量的输入边界值或错误数据,来检查是否可产生正确的输出。
本系统测试 主要选择黑盒测试,少量采用白盒测试。通过测试达到以下测试目的:
1.检查各大功能模块的运行,确保其能够正确运行,并检查各页面的完整性,保证页面完整。
2.检查各个接口是否可以正确地输入和输出,保证数据流通稳定可行。
3.检查数据结构,保证其和外部接口没有访问错误,访问顺利。
4.检查原计划的性能需求有没有完成,运行流畅。
本系统的测试用例(部分):
| 登录部分测试用例 | |||||
| 编号 | 对象 | 项目 | 操作 | 预期结果 | 结果 |
| 1 | 登录 | 登录提示 | 使用正确的账号密码登录 | 成功登录 | 预期结果 |
| 2 | 登录提示 | 使用正确的账号但错误的密码登录 | 提示密码错误 | 预期结果 | |
| 3 | 登录提示 | 使用错误的账号登录 | 提示不存在账户 | 预期结果 | |
| 4 | 登录提示 | 不输入账号,点击登录 | 提示输入账号 | 预期结果 | |
| 5 | 登录提示 | 输入账号但不输入密码点击登录 | 提示输入密码 | 预期结果 | |
| 6 | 登录入口 | 已登录账号,查看登录入口 | 不显示登录入口 | 预期结果 | |
处理器:Inter Core I7-4710MQ四核处理器
内存:4GB
硬盘:1T
操作系统:Windows 10
数据库:MySQL
全部测试用例都已通过(包括但不限于以上测试用例),且不存在漏洞,实现了论文开始时所作要求。本系统运行稳定,使用流畅,可以满足客户需求。
试运行后进行系统评估,可以认为该系统达到预定的目标要求,可以满足用户的需求,也满足了系统开发前所作目标。
系统在经过大量重复测试后运行十分稳定,安全实用,功能模块已经达到预定目标所需。
在规定的时间内实现系统的大部分功能,且满足要求,节省开发成本,有助于提高科学管理水平,符合本人经济情况。
本系统通过对python和Mysql数据库的简介,从硬件和软件两反面说明了图书书籍可视化系统的可行性,本文结论及研究成果如下:实现了python与Mysql相结合构建的图书书籍可视化系统,网站可以响应式展示。通过本次图书书籍可视化系统的研究与实现,我感到学海无涯,学习是没有终点的,而且实践出真知,只有多动手才能尽快掌握它,经验对系统的开发非常重要,经验不足,就难免会有许多考虑不周之处。比如要有美观的界面,更完善的功能,才能吸引更多的用户。
由于在此之前对于python知识没有深入了解,所以从一开始就碰到许多困难,例如一开始的页面显示不规范、数据库连接有问题已经无法实现参数的传递等等,不过通过在网上寻找有关资料以及同学的帮助下最后都得到了解决,在此过程中,我不仅学到了很多知识,也提高了自己解决问题的能力,尤其是学会如何从大量的信息中筛选出所需有用的信息,同时我更加深刻的体会到了,虽然书本上的大部分知识都是有价值,正确的,但实际上每个人编程的思路和对数据处理的方法、思想都是不同的,这就要求我们一定要通过实践才能找到解决问题的方案。在此次毕业设计活动中,我不断的提高了自己,也得到了宝贵的经验,我相信这些对我以后的发展都会有很大帮助。
通过这次图书书籍可视化系统的开发,我参考了很多相关系统的例子,取长补短,吸取了其他系统的长处,逐步对该系统进行了完善,但是该系统还是有很多的不足之处,有待以后进一步学习。
[1]Savchuk S ,Dvulit P ,Kerker V , et al.Python Software Tool for Diagnostics of the Global Navigation Satellite System Station (PS-NETM)–Reviewing the New Global Navigation Satellite System Time Series Analysis Tool[J].Remote Sensing,2024,16(5):
[2]Jiang Y ,Bugby L S ,Lees E J .PMST: A custom Python-based Monte Carlo Simulation Tool for research and system development in portable pinhole gamma cameras[J].Nuclear Inst. and Methods in Physics Research, A,2024,1061169161-.
[3]SabahiM ,SafariA ,NazariHerisM .Design and implementation of a cost‐effective practical single‐phase power quality analyzer using pyboard microcontroller and python‐to‐python interface[J].The Journal of Engineering,2024,2024(2):
[4]Ishan R ,Prakash C ,K. P T , et al.Python-Based Open-Source Tool for Automating Seleno-Referencing of Chandrayaan-2 Hyper-Spectral Data Cubes[J].Journal of the Indian Society of Remote Sensing,2024,52(2):305-313.
[5]Maurer J V ,Siggel M ,Kosinski J .PyTME (Python Template Matching Engine): A fast, flexible, and multi-purpose template matching library for cryogenic electron microscopy data[J].SoftwareX,2024,25101636-.
[6]王晨.基于Python爬虫的豆瓣书籍数据分析和可视化[J].信息与电脑(理论版),2023,35(23):174-176.
[7]王蔷,郭琪.基于Python语言的微博网络数据可视化系统设计与应用[J].电脑编程技巧与维护,2023,(11):101-104.DOI:10.16184/j.cnki.comprg.2023.11.012.
[8]孙振坤.融合多种算法的图书推荐系统研究[D].华东师范大学,2023.DOI:10.27149/d.cnki.ghdsu.2023.004132.
[9]杨冰倩.基于Python爬虫的影评情感分析与可视化系统设计[J].无线互联科技,2023,20(20):43-45+49.
[10]高凤毅,葛苏慧,林喜文,等.基于Python的招聘网站数据爬取与分析[J].电脑编程技巧与维护,2023,(09):70-72.DOI:10.16184/j.cnki.comprg.2023.09.006.
[11]代毛莉,习聪玲,梦以媛,等.基于微信小程序的校园书籍系统开发与制作[J].电脑编程技巧与维护,2023,(07):68-70+120.DOI:10.16184/j.cnki.comprg.2023.07.019.
[12]刘琳琳.基于区块链的高校校际联盟图书资源共享系统[D].河南工业大学,2023.DOI:10.27791/d.cnki.ghegy.2023.000586.
[13]陈超.基于SSM的网上书城销售管理系统的设计与实现[D].北京邮电大学,2022.DOI:10.26969/d.cnki.gbydu.2022.001459.
[14]梁家亚.基于文本内容的小学课外阅读图书推荐系统的设计与实现[D].中央民族大学,2022.DOI:10.27667/d.cnki.gzymu.2022.000114.
[15]周星宇.基于学生学习行为的高校图书推荐系统的设计与实现[D].华东师范大学,2022.DOI:10.27149/d.cnki.ghdsu.2022.002830.
[16]陶永,李月清,段兆英.图书可视化验收系统的设计与实现[J].北京工业职业技术学院学报,2022,21(02):26-29.
[17]肖伦山.基于DeepFM混合模型的高校图书推荐系统的设计与实现[D].西南大学,2022.DOI:10.27684/d.cnki.gxndx.2022.002052.
[18]徐杰铭.顾及图书错位查询功能的数字图书馆系统的设计与实现[D].合肥工业大学,2022.DOI:10.27101/d.cnki.ghfgu.2022.001432.
[19]赵涵原.基于Python爬虫的书籍数据可视化分析[J].电子技术与软件工程,2021,(14):178-179.
[20]魏秀丽.基于协同过滤的高校图书馆个性化图书推荐系统[D].首都经济贸易大学,2021.DOI:10.27338/d.cnki.gsjmu.2021.000079.
图书书籍可视化系统的完成,标志着我即将结束校园生活并跨入社会。在即将毕业的此刻,我想对所有帮助过我的师长、同学和亲人表达我发自内心的谢意。
感谢学校这个大家庭,在这里我们总能找到自己的归属。学校始终在向我们传达着温暖和关怀,接纳和包容我们的缺点。学校给我最大的感受便是要将自己的专业知识与实践相结合,而我也正在努力的成为学校所要求的应用型人才。
感谢各位老师,学院使我从懵懂一步步走向成熟。在这里每个老师都拥有着最大的善意和耐心,来教育我们这群大孩子。学院举办的各类活动是给予我锻炼自己的机会,正是这些机会让我成为了更好的自己,提升了自己各方面的能力。
其次我要感谢我的论文指导老师。我之所以被老师所吸引,是因为老师对于学生友爱和对于工作认真的态度。从选题到开题到论文的撰写,老师一直都在悉心的指导,在指出存在的问题后会与我们探讨解决方法。
最后,我要对即将参与本篇论文审阅和答辩的各位老师表示感谢。
免费领取项目源码,请关注❥点赞收藏并私信博主,谢谢~


















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









