




 这篇ACL2018的论文来自腾讯,探讨如何通过对抗训练提升神经机器翻译模型的鲁棒性。研究发现输入的微小扰动可能影响翻译质量,因此提出在输入句子上添加扰动,并在编码器和解码器中设计目标函数,以确保模型在面对扰动时仍能生成稳定输出。论文介绍了两种添加扰动的策略:词汇级别和特征级别,并强调模型的通用性和翻译性能的提升。
这篇ACL2018的论文来自腾讯,探讨如何通过对抗训练提升神经机器翻译模型的鲁棒性。研究发现输入的微小扰动可能影响翻译质量,因此提出在输入句子上添加扰动,并在编码器和解码器中设计目标函数,以确保模型在面对扰动时仍能生成稳定输出。论文介绍了两种添加扰动的策略:词汇级别和特征级别,并强调模型的通用性和翻译性能的提升。
论文信息
ACL2018 来自腾讯
提出背景
在神经机器翻译中,由于引入了循环神经网络和注意力机制,上下文中的每个词都可能影响模型的全局输出结果,类似于蝴蝶效应。
比如说,同声传译里面的同音异形词;文本中的拼写错误
输入的小的扰动会影响神经机器翻译的质量,在这篇文章中提出了利用对抗训练来提高NMT模型的robustness的方法。
具体方法
该方法的架构示意图如下图所示:
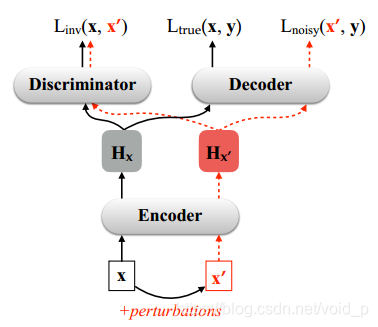
其工作过程为:给定一个输入句子 x,首先生成与其对应的扰动输入 x’,接着采用对抗训练,让编码器对于 x 和 x’ 生成相似的中间表示,同时要求解码器端输出相同的目标句子 y。这样能使得输入中的微小扰动不会导致目标输出产生较大差异。
对于翻译过程来说,有两个阶段:首先把输入x编码成隐藏状态
H
x
H_x
Hx,然后从隐藏状态
H
x
H_x
Hx中解码得到翻译y。
模型有两个目标:
(1)编码得到的
H
x
′
H_{x'}
Hx′和
H
x
H_{x}
Hx相近。
(2)给定
H
x
′
H_{x'}
Hx′,解码器可以输出robust翻译y。
训练的目标函数
J
(
θ
)
=
∑
<
x
,
y
>
∈
S
(
L
t
r
u
e
(
x
,
y
;
θ
e
n
c
,
θ
d
e
c
)
+
α
∑
x
′
∈
N
(
x
)
L
i
n
v
(
x
,
x
′
;
θ
e
n
c
,
θ
d
e
c
)
+
β
∑
x
′
∈
N
(
x
)
L
n
o
i
s
y
(
x
,
y
;
θ
e
n
c
,
θ
d
e
c
)
)
J(\theta)=\sum\limits_{<x,y>\in S}(L_{true}(x,y;\theta_{enc},\theta_{dec})+ \alpha \sum\limits_{x'\in N(x)}{L_{inv}(x,x';\theta_{enc},\theta_{dec}}) +\beta \sum\limits_{x'\in N(x)}{L_{noisy}(x,y;\theta_{enc},\theta_{dec}) })
J(θ)=<x,y>∈S∑(Ltrue(x,y;θenc,θdec)+αx′∈N(x)∑Linv(x,x′;θenc,θdec)+βx′∈N(x)∑Lnoisy(x,y;θenc,θdec))
其中第一项和第三项的计算方法是:
θ
^
=
a
r
g
m
i
n
L
(
x
,
y
;
θ
)
=
a
r
g
m
i
n
∑
<
x
,
y
>
∈
S
−
l
o
g
P
(
y
∣
x
;
θ
)
\widehat{\theta}=argmin L(x,y;\theta)=argmin{\sum\limits_{<x,y>\in S}-logP(y|x;\theta)}
θ
=argminL(x,y;θ)=argmin<x,y>∈S∑−logP(y∣x;θ)
θ
\theta
θ表示的是可以训练的参数。第二项表示的是adversarial loss。
两种给输入x加入扰动的策略
- 在词汇级别加入扰动(lexical level)
给定一个输入的句子x,随机采样一些单词的位置,这些单词用词表中其他位置单词代替。这些单词遵循如下的分布:
P
(
x
∣
x
i
)
=
e
x
p
(
c
o
s
(
E
[
x
i
]
,
E
[
x
]
)
∑
e
x
p
(
c
o
s
(
E
[
x
i
]
,
E
[
x
]
)
P(x|x_i)=\frac{exp(cos(E[x_i],E[x])}{\sum exp(cos(E[x_i],E[x])}
P(x∣xi)=∑exp(cos(E[xi],E[x])exp(cos(E[xi],E[x])
分母是代表词表中除了x以外的其他单词。
- 在feature级别加入扰动(feature level)
给定一个句子,可以得到每个单词的词嵌入向量,给词嵌入向量加入高斯噪声。
E
(
x
i
′
)
=
E
[
x
i
]
+
ϵ
E(x'_i)=E[x_i]+\epsilon
E(xi′)=E[xi]+ϵ
ϵ
\epsilon
ϵ服从的是高斯分布。对句子中的所有单词都加入高斯噪声。
这只是该论文中提出的两种加入干扰的策略,可以根据特定的任务来设计需要加入干扰的策略。
模型的优势
- 提高了鲁棒性和翻译性能(translation performance)。
- 适用于任何噪声扰动,该篇文章中提出了两种构造噪声的方法,可以扩展到任意噪声形式。
- 不依赖于特定的网络结构,适用于任何NMT系统。

















 1427
1427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









