






 本文详细介绍了单层感知机模型的工作原理,包括激活函数的选择、损失函数的定义以及梯度计算过程。通过一个具体的例子展示了如何利用PyTorch进行模型的搭建和训练,并解释了参数更新的步骤。内容涵盖了输入、权重、偏置、误差计算及反向传播等关键概念。
本文详细介绍了单层感知机模型的工作原理,包括激活函数的选择、损失函数的定义以及梯度计算过程。通过一个具体的例子展示了如何利用PyTorch进行模型的搭建和训练,并解释了参数更新的步骤。内容涵盖了输入、权重、偏置、误差计算及反向传播等关键概念。
单层感知机模型
y=XW+by=∑xi∗wi+b y = XW + b \\ y = \sum x_i*w_i+ b y=XW+by=∑xi∗wi+b
单层感知机模型的每一个输入节点xix_ixi和对应的权重wiw_iwi相乘累加后,与bias相加,便得到了预测值。
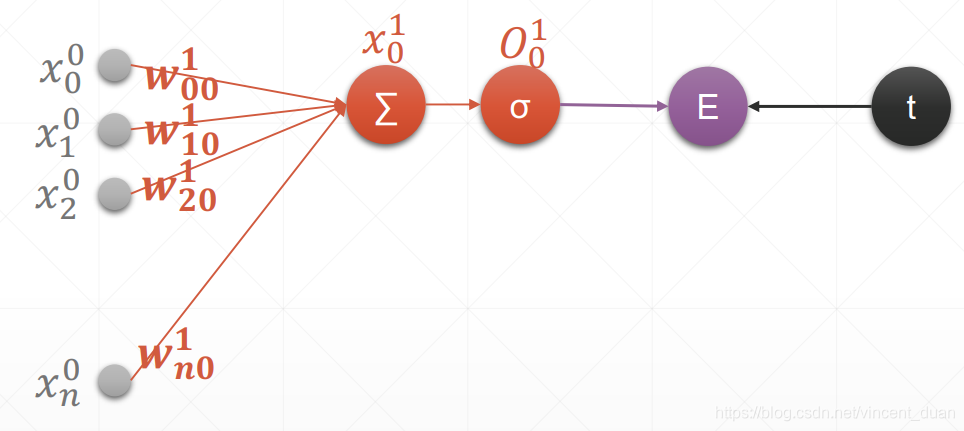
我们使用sigmoid函数作为激活函数,通常使用符号σ\sigmaσ表示。
对于最左边的输入层的上标,也就是xn0x_n^0xn0中的0表示第0层,n表示第0层第n个元素节点。
从www到σ\sigmaσ是1层,wij1w^1_{ij}wij1表示第1层,i表示连接的上一层xix_ixi,j表示本层的第j个节点。因为上图中只有一层,所以j=0 。x01x_0^1x01中1表示第一层,0表示第一层的0号节点【这里讨论单层输出感知机,所以第一层只有一个节点】。x01x_0^1x01经过激活函数之后,有一个输出值O01O_0^1O01,其中1表示第一层,0表示第0号节点。
随后,O01O_0^1O01与target值计算:Error(Loss)=∑(O01−target)2Error(Loss)=\sum(O_0^1-target)^2Error(Loss)=∑(O01−target)2
梯度
Loss计算公式:
E=12(O01−t)2
E = \frac{1}{2}(O_0^1 - t)^2
E=21(O01−t)2
这里引入了一个额外的12\frac{1}{2}21是为了与求导后的数2抵消掉。不会影响单调性的。
∂E∂wj0=(O0−t)∗O0∂wj0∂E∂wj0=(O0−t)σ(x01)∂wj0∂E∂wj0=(O0−t)σ(x0)(1−σ(x0))∂x01∂wj0
\frac {\partial E}{\partial w_{j0}} =(O_0 - t)*\frac{O_0}{\partial w_{j0}} \\
\frac {\partial E}{\partial w_{j0}} = (O_0 - t)\frac{\sigma(x_0^1)}{\partial w_{j0}} \\
\frac {\partial E}{\partial w_{j0}} = (O_0 - t) \sigma(x_0)(1-\sigma(x_0))\frac{\partial x_0^1}{\partial w_{j0}}
∂wj0∂E=(O0−t)∗∂wj0O0∂wj0∂E=(O0−t)∂wj0σ(x01)∂wj0∂E=(O0−t)σ(x0)(1−σ(x0))∂wj0∂x01
求导之前需要先向右计算一次所有的变量值,这就是向前传播
∂x0∂wj0=∂∑wj0xj0∂wj0=xj0
\frac {\partial x_0}{\partial w_{j0}}=\frac {\partial \sum w_{j0}x_j^0}{\partial w_{j0}} = x_j^0
∂wj0∂x0=∂wj0∂∑wj0xj0=xj0
因此上面的公式得到最终结果:
∂E∂wj0=(O0−t))O0(1−O0)xj0
\frac {\partial E}{\partial w_{j0}} =(O_0 - t))O_0(1-O_0)x_j^0
∂wj0∂E=(O0−t))O0(1−O0)xj0
方法实现
输入10个特征的x
x = torch.randn(1,10)
# tensor([[ 0.5817, -1.1089, -0.9756, -0.4556, -0.2144, -1.1662, 1.9232, 0.2331,
# -1.2987, -0.4950]])
w = torch.randn(1,10,requires_grad = True)
# tensor([[-1.0490, -1.7553, 0.1665, -0.0458, -0.8664, -0.3328, -0.1398, 1.2416,
# 1.3097, -0.4996]], requires_grad=True)
o = torch.sigmoid(x@w.t())
# tensor([[0.5831]], grad_fn=<SigmoidBackward>)
loss = F.mse_loss(torch.ones(1,1),o)
# tensor(0.1738, grad_fn=<MseLossBackward>)
loss.backward()
w.grad
# tensor([[-0.1179, 0.2248, 0.1977, 0.0923, 0.0435, 0.2364, -0.3898, -0.0472,
# 0.2632, 0.1003]])
这样就得到了每一个www的梯度,随后可以根据w′=w−0.001∗∇ww' = w - 0.001 * \nabla ww′=w−0.001∗∇w来更新参数了。


















 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









