




 探讨MapReduce处理大量数据时的性能瓶颈,介绍Combiner如何在Map端进行预聚合,减少网络传输,提升作业执行效率。同时,分析Combiner在特定场景下的局限性。
探讨MapReduce处理大量数据时的性能瓶颈,介绍Combiner如何在Map端进行预聚合,减少网络传输,提升作业执行效率。同时,分析Combiner在特定场景下的局限性。
需求
词频统计,假设有一个文件,统计这个文件词频
常见的解决办法
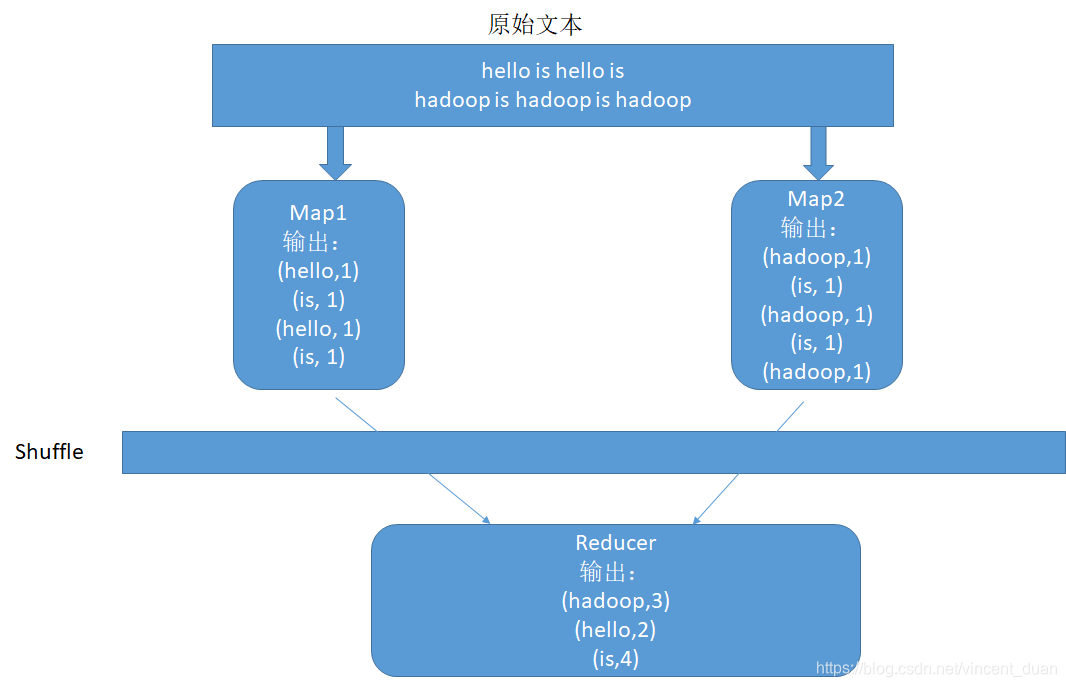
例如原始文本是:
交给两个Map去处理,map1处理hello is hello is,map2处理hadoop is hadoop is hadoop,输出结果map1为:(hello,1)(is, 1)(hello, 1)(is, 1),map2为(hadoop,1)(is, 1)(hadoop, 1)(is, 1)(hadoop,1)。然后把结果给shuffle,shuffle按照相同的key(会按照字典顺序排序)丢给Reducer中去处理。
问题
map1中有4个Key,map2中有4个Key,一共9个Key。但是在Reducer中一共只输出了3个Key。如果map1中处理1000万个key,第二个处理1000万个Key,所有的数据都要经过网络传输,性能一定会受影响。
解决办法
如果在map端再做一次聚合,是不是就会提高性能了。这个聚合的操作和我们的Reduce逻辑完全一样。
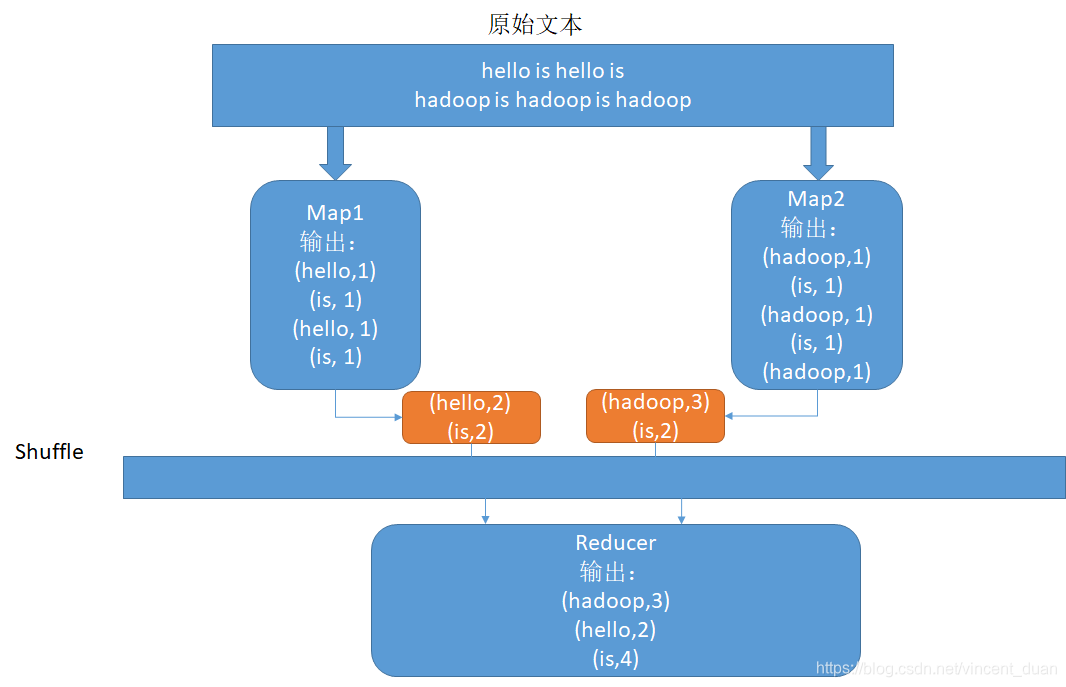
这个Map端的聚合操作就叫做Combiner。
这样能很大程度上节省网络开销。
实现方法
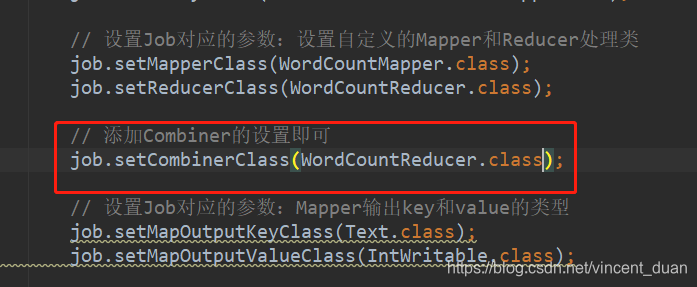
跟Reducer的方法是一样的,直接添加上Reducer就可以了。
Combiner的优点
能减少IO,提升作业的执行性能
Combiner的局限性
在求平均数的场景下,会出现错误的结果。

















 3282
3282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









