




写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
随着大模型时代的到来,模型参数量、训练数据量、计算量等各方面急剧增长。大模型训练面临新的挑战:
- 显存挑战:例如,175B的GPT-3模型需要175B*4bytes即700GB模型参数空间,而常见的GPU显存如A100是80G显存,这样看来连模型加载都困难更别说训练。
- 计算挑战:175B的GPT-3模型计算量也很庞大了,再叠加预训练数据量,所需的计算量与BERT时代完全不可同日而语。
分布式训练(Distributed Training)则可以解决海量计算和内存资源要求的问题。它可将一个模型训练任务拆分为多个子任务,并将子任务分发给多个计算设备(eg:单机多卡,多机多卡),从而解决资源瓶颈。
本文将详细介绍分布式训练的基本概念、集群架构、并行策略等,以及如何在集群上训练大语言模型。
何为分布式训练?
分布式训练是指将机器学习或深度学习模型训练任务分解成多个子任务,并在多个计算设备上并行训练,可以更快速地完成整体计算,并最终实现对整个计算过程的加速。
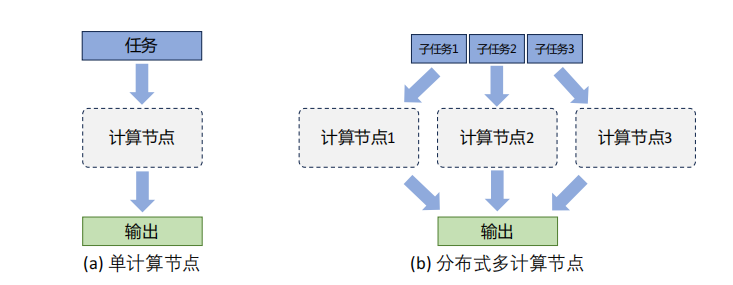
如上图是单个计算设备和多个计算设备的不同,这里计算设备可以是CPU、GPU、TPU、NPU等。
在分布式训练的背景下,无论是单服务器内的多计算设备还是跨服务器的多设备,系统架构均被视为 「分布式系统」 。这是因为,即使在同一服务器内部,多个计算设备(如GPU)之间的内存也不一定是共享的,意味着 「设备间的数据交换和同步必须通过网络或高速互联实现」 ,与跨服务器的设备通信本质相同。
分布式训练集群架构
分布式训练集群属于高性能计算集群(High Performance Computing Cluster,HPC),其目标是提供海量的计算能力。 在由高速网络组成的高性能计算上构建分布式训练系统。
高性能计算集群硬件组成如图所示。
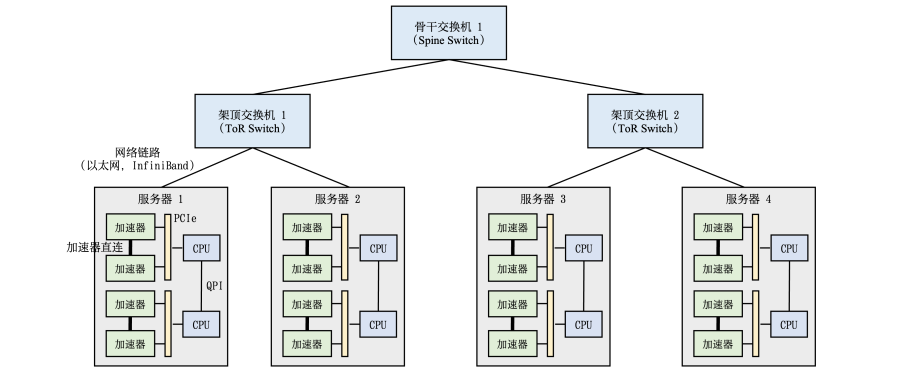
整个计算集群包含大量带有计算加速设备的服务器,多个服务器会被安置在机柜中,服务器通过架顶交换机(Top of Rack Switch,ToR)连接网络。在架顶交换机满载的情况下,可以通过在架顶交换机间增加骨干交换机进一步接入新的机柜。
每个服务器中通常是由2-16个计算加速设备组成,这些计算加速设备之间的高速通信直接影响到分布式训练的效率。传统的PCI Express(PCIe)总线,即使是PCIe 5.0版本,也只能提供相对较低的128GB/s带宽,这在处理大规模数据集和复杂模型时可能成为瓶颈。
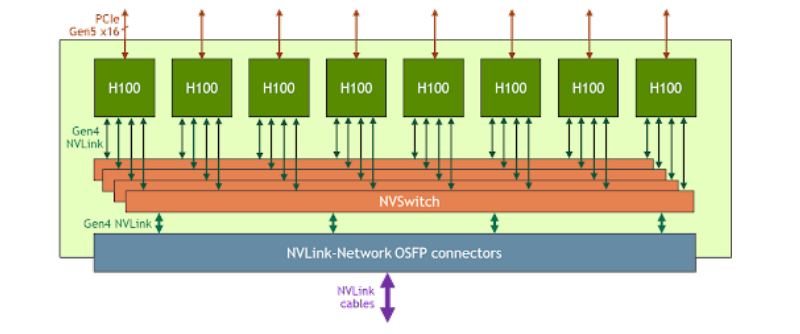
为了解决这一问题,NVIDIA推出了NVLink和NVSwitch技术。如下图所示,每个H100 GPU都有多个NVLink端口,并连接到所有四个NVSwitch上。每个NVSwitch都是一个完全无阻塞的交换机,完全连接所有8个H100计算加速卡。NVSwitch的这种完全连接的拓扑结构,使得服务器内任何H100加速卡之间都可以达到900GB/s双向通信速度。
针对分布式训练服务器集群进行架构涉及的主流架构,目前主流的主要分为参数服务器(ParameterServer,简称PS)和去中心化架构(Decentralized Network)两种分布式架构。
参数服务器架构
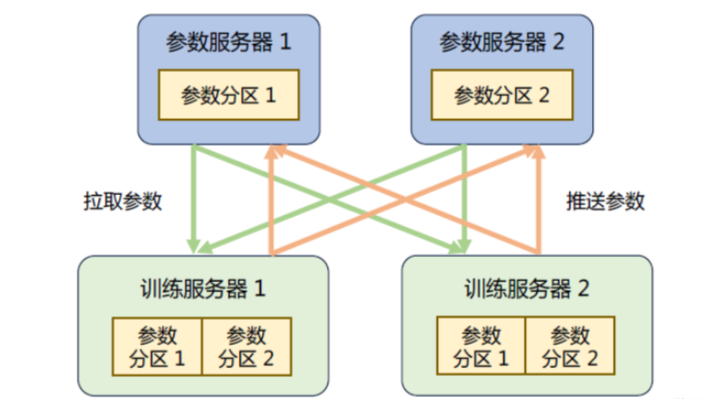
参数服务器架构的分布式训练系统中有两种服务器:
- 训练服务器:提供大量的计算资源
- 参数服务器:提供充足的内存资源和通信资源
如下所示是具有参数服务器的分布式训练集群的示意图。在训练过程中,每个训练服务器都拥有完整的模型,并根据将分配到此服务器的训练数据集切片(Dataset Shard)进行计算,将得到的梯度推送到相应的参数服务器。参数服务器会等待两个训练服务器都完成梯度推送,然后开始计算平均梯度,并更新参数。之后,参数服务器会通知训练服务器拉取最新的参数,并开始下一轮训练迭代。
去中心化架构
去中心化架构没有中央服务器或控制节点,而是由节点之间进行直接通信和协调,这种架构的好处是可以减少通信瓶颈,提高系统的可扩展性。
节点之间的分布式通信一般有两大类:
- 点对点通信(Point-to-Point Communication):在一组节点内进行通信
- 集合通信(Collective communication,CC):在两个节点之间进行通信
去中心化架构中通常采用集合通信实现。
常见通信原语如下:
「Broadcast」
将数据从主节点发送到集群中的其他节点。如下图,计算设备1将大小为1xN的张量广播到其它设备,最终每张卡输出均为1×N矩阵。
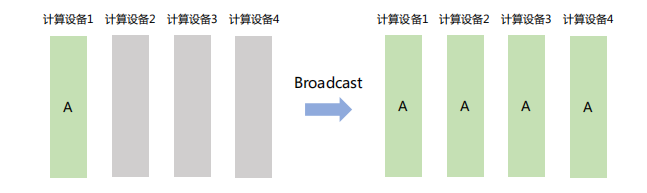
Broadcast在分布式训练中主要用于 「模型参数初始化」 。
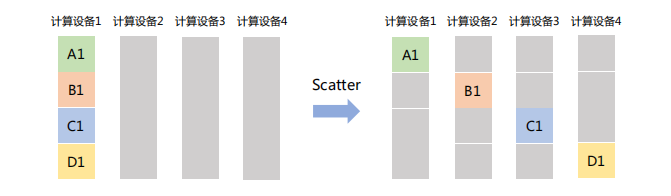
「Scatter」
主节点将一个大的数据块分割成若干小部分,再将每部分分发到集群中的其他节点。如下图,计算设备1将大小为1xN的张量分成4个子张量,再分别发送给其它设备。
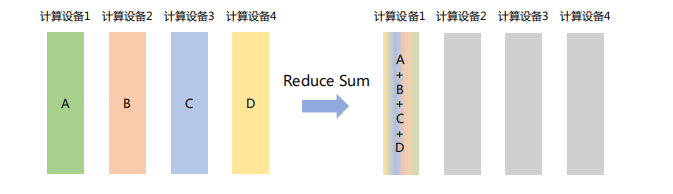
「Reduce」
将不同节点上的计算结果进行聚合。Reduce操作可以细分为多种类型,包括SUM(求和)、MIN(求最小值)、MAX(求最大值)、PROD(乘积)、LOR(逻辑或)等,每种类型对应一种特定的聚合方式。
如下图所示,Reduce Sum操作将所有计算设备上的数据进行求和,然后将结果返回到计算设备1。
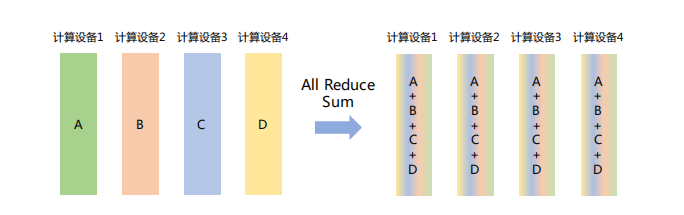
「All Reduce」
在所有节点上执行同样的Reduce操作,如求和、求最小值、求最大值等。可通过单节点上Reduce+Broadcast操作完成。
如下图所示,All Reduce Sum操作将所有节点上的数据求和,然后将求和结果Broadcast到所有节点。
「Gather」
将所有节点的数据收集到单个节点,可以看作是Scatter操作的逆操作。
如下图所示,Gather操作将所有设备的数据收集到计算设备1中。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1678
1678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











