




 本文详细介绍了如何使用Apache Storm的Distributed RPC (DRPC) 功能进行服务器端配置和客户端远程调用。从配置Nimbus节点的drpc.servers参数开始,到使用Java实现DoubleWordBolt和DoubleWordTopology,再到本地执行和提交到Storm集群的过程,最后演示了如何通过DRPCClient进行远程调用。
本文详细介绍了如何使用Apache Storm的Distributed RPC (DRPC) 功能进行服务器端配置和客户端远程调用。从配置Nimbus节点的drpc.servers参数开始,到使用Java实现DoubleWordBolt和DoubleWordTopology,再到本地执行和提交到Storm集群的过程,最后演示了如何通过DRPCClient进行远程调用。
一:服务器端
1. 在Nimbus主节点中配置drpc.servers
conf/storm.yaml
drpc.servers:
- "127.0.0.1"
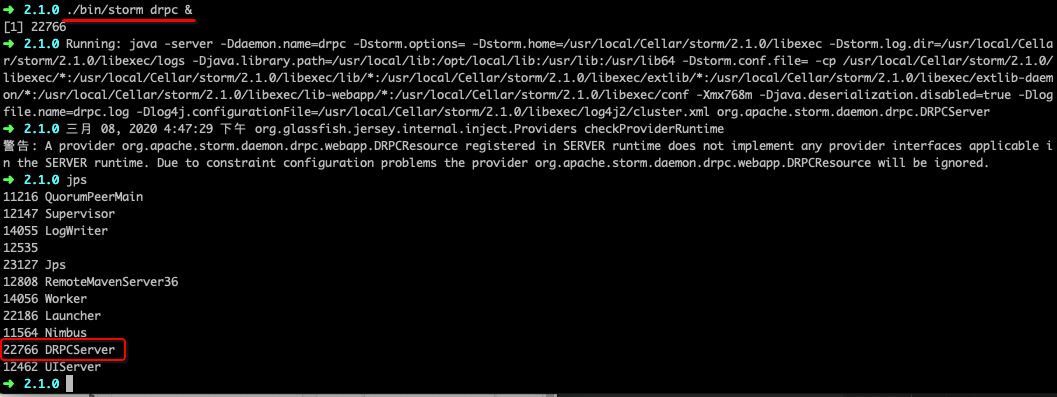
2. 启动drpc服务
./bin/storm drpc &
3. storm-drpc-server
3.1 pom.xml
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</dependency>
</dependencies>
3.2 resources/log4j2.xml
Storm本身会打印很多很多info级别的日志,为了减少日志输出,可以提高日志的级别。
<configuration>
<Loggers>
<logger name="org.apache.storm" level="ERROR"/>
<logger name="org.apache.zookeeper" level="ERROR"/>
<logger name="org.example.drpc" level="INFO"/>
</Loggers>
</configuration>
3.3 DoubleWordBolt
public class DoubleWordBolt extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getString(1);
String result = word + word;
collector.emit(new Values(tuple.getValue(0), result));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 至少两个字段,第一个字段为id
declarer.declare(new Fields("id", "result"));
}
}
3.4 DoubleWordTopology
@Slf4j
public class DoubleWordTopology {
public static void main(String[] args) throws Exception {
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("doubleWord");
builder.addBolt(new DoubleWordBolt(), 3).shuffleGrouping();
Config config = new Config();
if (args == null || args.length == 0) {
// 本地
LocalDRPC localDRPC = new LocalDRPC();
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("drpc-double-word", config, builder.createLocalTopology(localDRPC));
List<String> wordList = Arrays.asList("Hadoop", "Storm", "Spark", "Flink");
for (String word : wordList) {
String result = localDRPC.execute("doubleWord", word);
log.info("️✅word={} result={}", word, result);
}
localCluster.shutdown();
localDRPC.shutdown();
} else {
// Storm集群
config.setNumWorkers(2);
StormSubmitter.submitTopology(args[0], config, builder.createRemoteTopology());
}
}
}
3.5 本地执行
由于设置Storm自身日志为ERROR,所以启动程序时很干净,不输出日志并不表示程序没运行,程序运行比较慢,需要等一会才会输出结果。
执行main方法,等待一会才会有结果。

二:提交到Storm服务器
1. 打包程序
mvn clean package
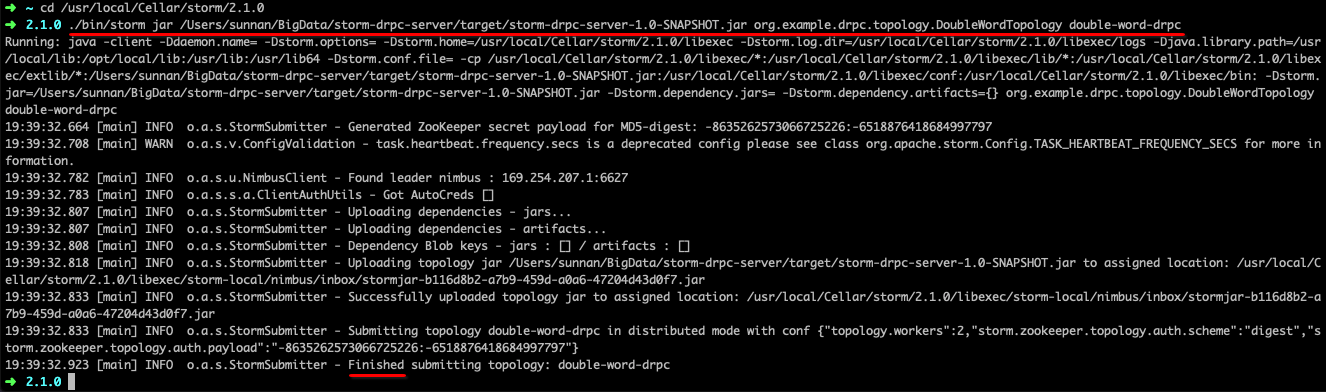
2. 上传到Storm集群
./bin/storm jar ~/BigData/storm-drpc-server/target/storm-drpc-server-1.0-SNAPSHOT.jar
org.example.drpc.topology.DoubleWordTopology
double-word-drpc

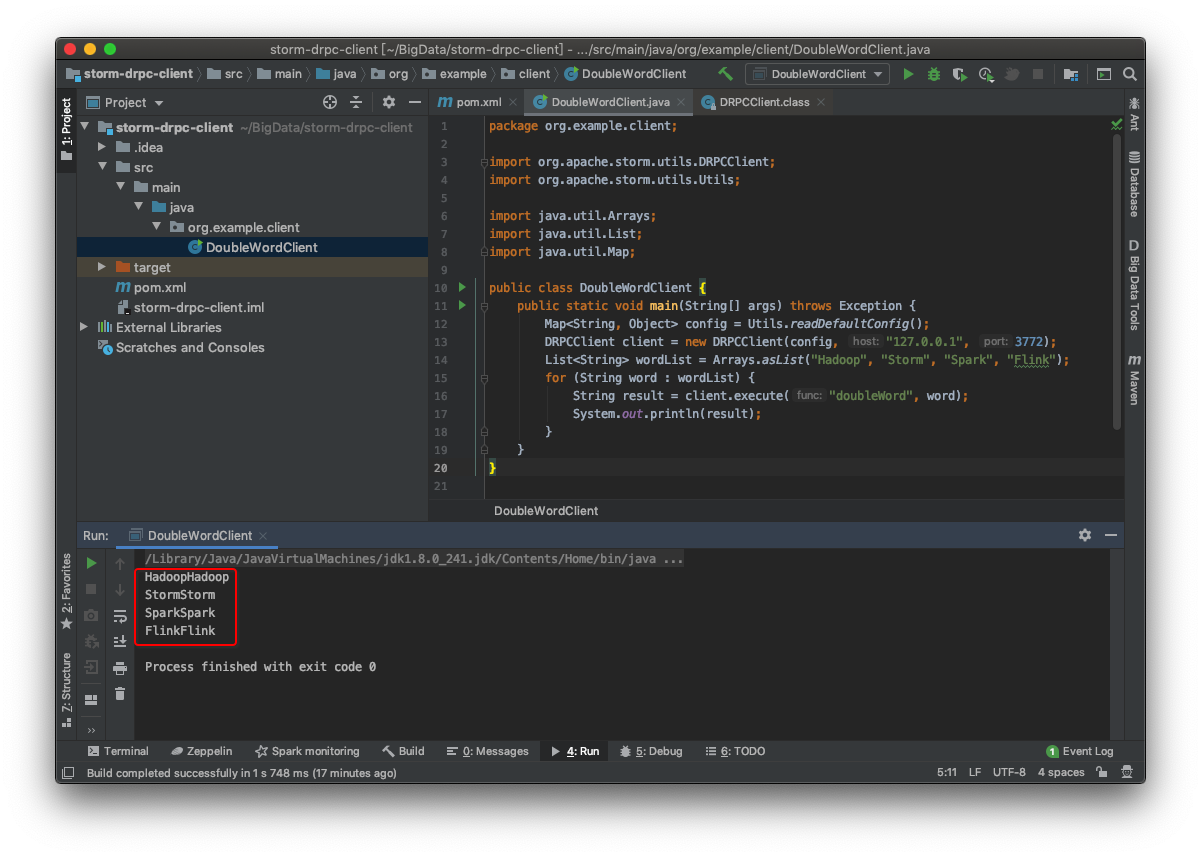
三:客户端远程调用
import org.apache.storm.utils.DRPCClient;
import org.apache.storm.utils.Utils;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
public class DoubleWordClient {
public static void main(String[] args) throws Exception {
Map<String, Object> config = Utils.readDefaultConfig();
DRPCClient client = new DRPCClient(config, "127.0.0.1", 3772);
List<String> wordList = Arrays.asList("Hadoop", "Storm", "Spark", "Flink");
for (String word : wordList) {
String result = client.execute("doubleWord", word);
System.out.println(result);
}
}
}


















 3312
3312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











