




 本文详细介绍如何将Apache Storm与Kafka整合,实现基于Kafka的数据流处理。通过WordCount示例,展示从搭建环境、配置依赖、编写处理组件到运行Topology的全过程。
本文详细介绍如何将Apache Storm与Kafka整合,实现基于Kafka的数据流处理。通过WordCount示例,展示从搭建环境、配置依赖、编写处理组件到运行Topology的全过程。
Storm与Kafka整合就是将Kafka作为消息源Spout。
本示例采用的都是目前最新的版本号:
- kafka 2.4.0
- storm 2.1.0
一:启动zookeeper和Kafka服务
# 启动zookeeper
./zkServer.sh start
# 启动Kafka
sudo ./bin/kafka-server-start /usr/local/etc/kafka/server.properties
# 创建test主题
./bin/kafka-topics --create --zookeeper localhost:2181 --partitions 1 --replication-factor 1 --topic test
# 生产者控制台
./bin/kafka-console-producer --broker-list localhost:9092 --topic test
二:Word Count 示例
1. pom.xml
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.13</artifactId>
<version>2.4.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</dependency>
2. log4j2.xml
关闭掉Storm中INFO级别的日志。
<configuration>
<Loggers>
<logger name="org.apache.storm" level="ERROR"/>
<logger name="org.apache.zookeeper" level="ERROR"/>
<logger name="org.example.kafka" level="INFO"/>
</Loggers>
</configuration>
3. SplitSentenceBolt
import lombok.extern.slf4j.Slf4j;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Map;
/**
* 将句子分隔成单词
*/
@Slf4j
public class SplitSentenceBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
try {
String sentence = input.getStringByField("sentence");
String[] words = sentence.split(" ");
// 将每个单词流向到下一个Bolt
for (String word : words) {
// 发射时携带发射过来的input
collector.emit(input, new Values(word));
}
// 处理成功了给当前tuple做一个成功的标记,调用上游的ack方法
collector.ack(input);
} catch (Exception e) {
log.error("SplitSentenceBolt#execute exception", e);
// 异常做一个失败的标记,调用上游的fail方法
collector.fail(input);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
4. WordCountBolt
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.HashMap;
import java.util.Map;
public class WordCountBolt extends BaseRichBolt {
private OutputCollector collector;
private Map<String, Long> wordCountMap = null;
/**
* 大部分示例变量通常在prepare中进行实例化
* @param topoConf
* @param context
* @param collector
*/
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
this.wordCountMap = new HashMap<>();
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
Long count = wordCountMap.get(word);
if (count == null) {
count = 0L;
}
count++;
wordCountMap.put(word, count);
collector.emit(new Values(word, count));
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
5. ReportBolt
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import java.util.*;
public class ReportBolt extends BaseRichBolt {
private Map<String, Long> wordCountMap = null;
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.wordCountMap = new HashMap<>();
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
Long count = input.getLongByField("count");
wordCountMap.put(word, count);
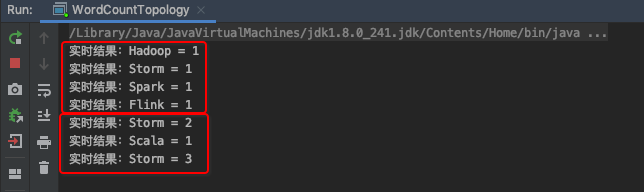
System.out.println("实时结果:" + word + " = " + count);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
6. WordCountTopology
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.kafka.spout.ByTopicRecordTranslator;
import org.apache.storm.kafka.spout.KafkaSpout;
import org.apache.storm.kafka.spout.KafkaSpoutConfig;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.example.kafka.bolt.ReportBolt;
import org.example.kafka.bolt.SplitSentenceBolt;
import org.example.kafka.bolt.WordCountBolt;
public class WordCountTopology {
public static void main(String[] args) throws Exception {
String topic = "test";
// 该类将传入的kafka记录转换为storm的tuple
ByTopicRecordTranslator<String,String> brt =
new ByTopicRecordTranslator<>( (r) -> new Values(r.value(), r.topic()), new Fields("sentence", topic));
// 设置要消费的topic
brt.forTopic(topic, (r) -> new Values(r.value(), r.topic()), new Fields("sentence", topic));
KafkaSpoutConfig<String, String> kafkaSpoutConfig = KafkaSpoutConfig
.builder("localhost:9092", topic)
.setProp(ConsumerConfig.GROUP_ID_CONFIG, "test-group")
.setRecordTranslator(brt)
.build();
KafkaSpout<String, String> kafkaSpout = new KafkaSpout<>(kafkaSpoutConfig);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka-spout", kafkaSpout, 1);
builder.setBolt("split-bolt", new SplitSentenceBolt(), 1).shuffleGrouping("kafka-spout");
builder.setBolt("wordcount-bolt", new WordCountBolt(), 1).shuffleGrouping("split-bolt");
builder.setBolt("report-bolt", new ReportBolt(), 1).globalGrouping("wordcount-bolt");
StormTopology topology = builder.createTopology();
Config config = new Config();
if (args == null || args.length == 0) {
// 本地模式
config.setDebug(true);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("WordCountTopology", config, topology);
} else {
// 集群模式
StormSubmitter.submitTopology(args[0],config,builder.createTopology());
}
}
}
7. 启动WordCountTopology#main
注意:可能启动比较慢,需要等一下,等待启动完成。如果配置了log4j2.xml启动时是不输出任何日志的,如果没有配置启动时会输出很多日志。
8. Kafka生产消息
./bin/kafka-console-producer --broker-list localhost:9092 --topic test
>Hadoop Storm Spark Flink
>Storm Scala Storm



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











