




 本文深入解析Apache Storm中Ack机制的工作原理,包括如何处理任务失败、重试机制及错误记录。通过具体示例,展示了Ack机制在SplitSentenceBolt和WriteWordBolt组件中的应用,以及如何避免重复处理导致的数据冗余。
本文深入解析Apache Storm中Ack机制的工作原理,包括如何处理任务失败、重试机制及错误记录。通过具体示例,展示了Ack机制在SplitSentenceBolt和WriteWordBolt组件中的应用,以及如何避免重复处理导致的数据冗余。
一:简介
当一个Bolt处理失败时需要提供一种处理错误的方式,Ack就是用来定义处理错误的逻辑,一般可以选择重现发射或者记录错误。
实用Ack时要注意:
- 发射时需要带上Tuple和messageId
collector.emit(new Values("xxx"), msgId); - Bolt处理业务逻辑需要用try catch捕获未知异常,处理成功需要调用
collector.ack(input);
处理失败时需要调用collector.fail(input); - Spout需要重写
public void ack(Object msgId)和public void fail(Object msgId)两个方法用来定义Bolt处理失败后的逻辑
二:示例一 SplitSentenceBolt处理异常
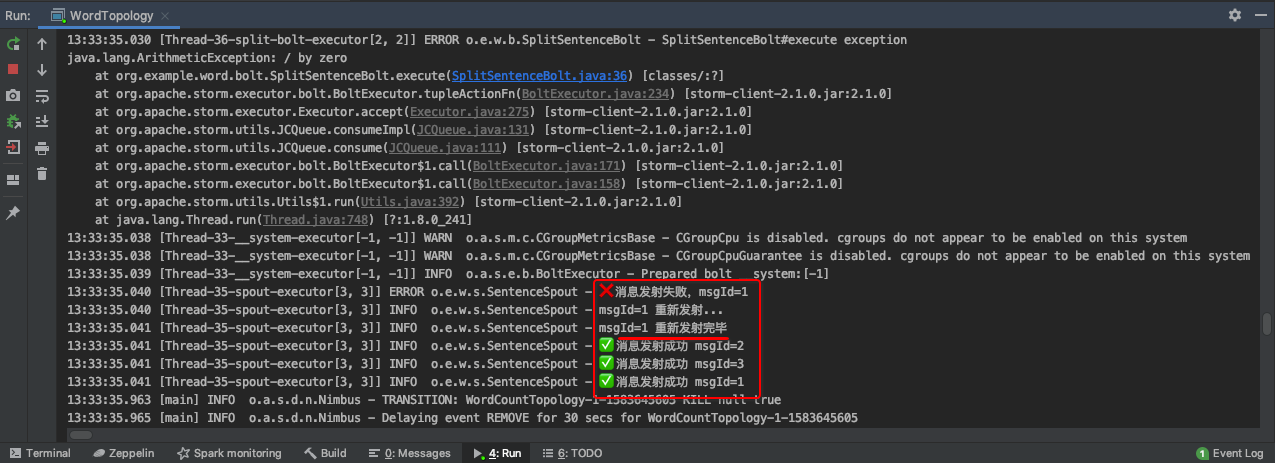
本示例演示将一组句子通过逗号分隔成单词,然后将单词写到文件中。如果第一个Blot处理失败时需要重写发射尝试下一次继续处理。
- pom.xml
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.1.0</version>
<!-- 本地模式去掉scope,否则会报NoClassDefFoundError: org/apache/storm/topology/IRichSpout-->
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>com.codahale.metrics</groupId>
<artifactId>metrics-core</artifactId>
<version>3.0.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</dependency>
</dependencies>
- SentenceSpout
import lombok.extern.slf4j.Slf4j;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
@Slf4j
public class SentenceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private List<String> sentenceList = Arrays.asList(
"Hadoop,Hive,HBase",
"Sqoop,Flume",
"Storm,Spark,FLink",
"Java,Scala,Python"
);
private Integer index = 0;
@Override
public void open(Map<String, Object> conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
/**
* Storm将会循环调用该方法
*/
@Override
public void nextTuple() {
if (index < sentenceList.size()) {
final String sentence = sentenceList.get(index);
// 发射时需要指定 消息id
collector.emit(new Values(sentence), index);
index++;
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
/**
* 发射成功后的确认
* 发射成功是指:发送成功并且要发射的Bolt成功处理了,没有报错
* @param msgId
*/
@Override
public void ack(Object msgId) {
log.info("✅️消息发射成功 msgId={}", msgId);
}
@Override
public void fail(Object msgId) {
log.error("❌消息发射失败,msgId={}", msgId);
log.info("msgId={} 重新发射...", msgId);
collector.emit(new Values(sentenceList.get((Integer)msgId)), msgId);
log.info("msgId={} 重新发射完毕", msgId);
}
@Override
public void close() {
log.info("************************************ SentenceSpout STOP ************************************");
super.close();
}
}
- SplitSentenceBolt
/**
* 将句子分隔成单词
*/
@Slf4j
public class SplitSentenceBolt extends BaseRichBolt {
private OutputCollector collector;
private boolean flag = true;
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
try {
String sentence = input.getStringByField("sentence");
// 模拟处理失败的场景
if (sentence.equals("Sqoop,Flume") && flag) {
flag = false;
int a = 1/0;
}
String[] words = sentence.split(",");
// 将每个单词流向到下一个Bolt
for (String word : words) {
// 发射时携带发射过来的input
collector.emit(input, new Values(word));
}
// 处理成功了给当前tuple做一个成功的标记,调用上游的ack方法
collector.ack(input);
} catch (Exception e) {
log.error("SplitSentenceBolt#execute exception", e);
// 异常做一个失败的标记,调用上游的fail方法
collector.fail(input);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
- WriteWordBolt
@Slf4j
public class WriteWordBolt extends BaseRichBolt {
private OutputCollector collector;
private FileWriter writer;
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
try {
writer = new FileWriter("/usr/temp/words");
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
try {
writer.write(word);
writer.write("\r\n");
writer.flush();
collector.ack(input);
} catch (IOException e) {
log.error("WriteWordBolt#execute exception", e);
collector.fail(input);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
- WordTopology
public class WordTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new SentenceSpout());
builder.setBolt("split-bolt", new SplitSentenceBolt()).shuffleGrouping("spout");
builder.setBolt("write-bolt", new WriteWordBolt()).shuffleGrouping("split-bolt");
StormTopology topology = builder.createTopology();
String topologyName = "WordCountTopology";
Config config = new Config();
config.setDebug(false);
// 本地模式 提交拓扑
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(topologyName, config, topology);
Utils.sleep(10000);
cluster.killTopology(topologyName);
cluster.shutdown();
}
}
三:示例二 WriteWordBolt处理异常
WordTopology和SentenceSpout代码保持不变。
SplitSentenceBolt正常处理
/**
* 将句子分隔成单词
*/
@Slf4j
public class SplitSentenceBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
try {
String sentence = input.getStringByField("sentence");
String[] words = sentence.split(",");
// 将每个单词流向到下一个Bolt
for (String word : words) {
// 发射时携带发射过来的input
collector.emit(input, new Values(word));
}
// 处理成功了给当前tuple做一个成功的标记,调用上游的ack方法
collector.ack(input);
} catch (Exception e) {
log.error("SplitSentenceBolt#execute exception", e);
// 异常做一个失败的标记,调用上游的fail方法
collector.fail(input);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
WriteWordBolt 发生异常
@Slf4j
public class WriteWordBolt extends BaseRichBolt {
private OutputCollector collector;
private FileWriter writer;
private boolean flag = true;
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
try {
writer = new FileWriter("/usr/temp/words");
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
try {
// 模拟处理失败的场景Sqoop,Flume句子Sqoop失败,Flume成功
if (word.equals("Sqoop") && flag) {
flag = false;
int a = 1/0;
}
writer.write(word);
writer.write("\r\n");
writer.flush();
collector.ack(input);
} catch (Exception e) {
log.error("WriteWordBolt#execute exception", e);
collector.fail(input);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
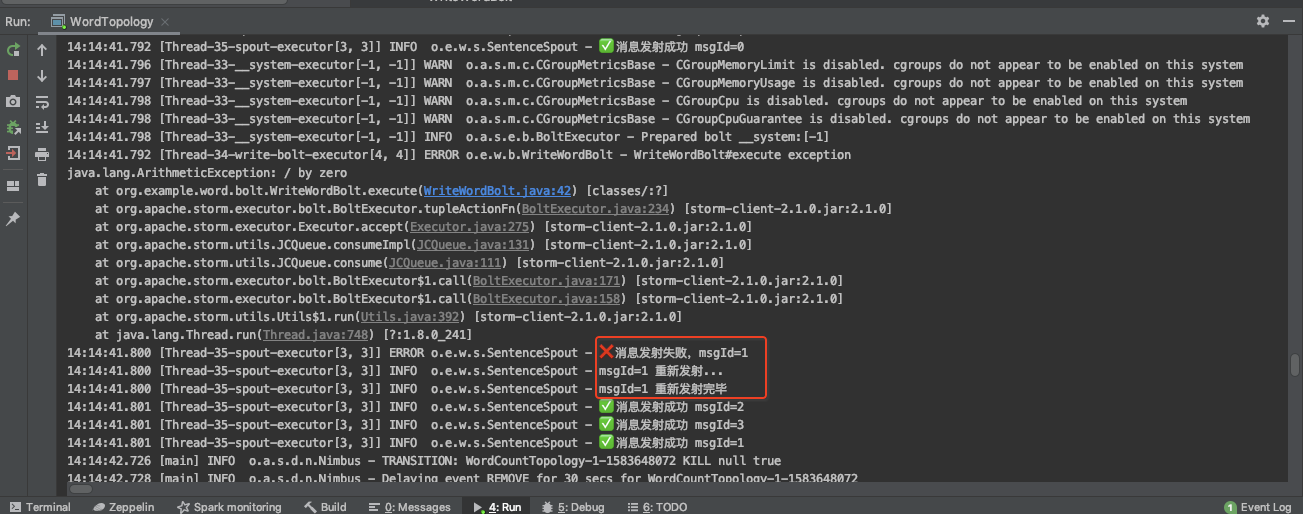
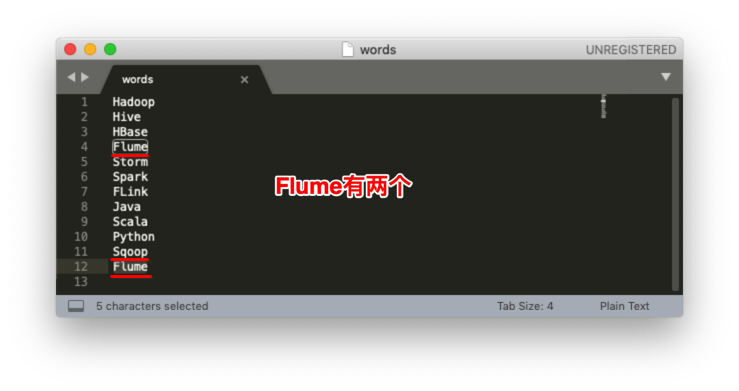
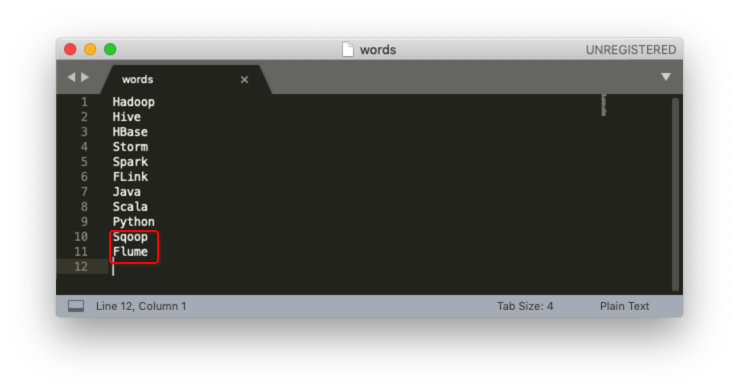
Flume为什么有两个?
在WriteWordBolt中当第一次处理“Sqoop,Flume”时Flume处理成功了而Sqoop处理失败了,当Sqoop处理失败了会执行collector.fail(input);而input是指整个句子“Sqoop,Flume”而不是一个单词Sqoop,SentenceSpout#fail方法会继续将这个句子发射给下一个Bolt, 这样WriteWordBolt又会重新处理Sqoop和Flume两个单词,所以看到Sqoop和Flume成功写到文件中了,这就造成Flume被写了2次。问题的最终原因是在调用fail方法时时将整个句子作为参数传递了。


















 4911
4911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











